







目录
一、摘要
联邦学习(FL)近年来引起了越来越多的关注。FL与边缘计算的集成,使边缘系统更加高效和智能化。FL通常使用服务器主动选择某些边缘设备来参与全局模型训练。然而,所选的边缘设备可能是偏离的,甚至在训练中崩溃。同时,未被选择的空闲边缘设备不能被充分用于训练。因此,除了广泛研究的通信效率和数据异质性问题外,我们还考虑了上述时间效率,并提出了一种时间高效的异步联邦学习协议TEA-Fed来解决这些问题。使用TEA-Fed,空闲边缘设备积极申请训练任务,一旦分配任务就异步参与模型训练。考虑到在边缘计算中可能存在大量的边缘设备,我们引入了控制参数来限制同时参与训练同一模型的设备的数量。同时,我们还在模型聚合步骤中引入了关于模型稳定性的缓存机制和加权平均,以减少模型稳定性的不利影响,进一步提高了全局模型的精度。最后,实验结果表明,该协议能够加快模型训练的收敛速度,提高了模型训练的精度,并具有对异构数据的鲁棒性。
二、背景
目前联邦学习框架主要存在以下问题:
- 大多数边缘设备的计算资源和通信能力是有限的,比如电量低、计算能力有限、网络拥塞等资源限制。
- 同步训练的弊端。同步联合优化未能充分利用边缘设备的空闲时间进行模型训练,那些未被选择的空闲设备在每个全局时期不被使用,或者一些设备在之后空闲上传更新的本地模型,可能不再被选择。
在许多优化算法中,每一轮都由服务器随机选择参与模型培训的客户端。但是,由于不稳定的网络条件、电池电量不足和设备崩溃,边缘设备通常是不可靠的,这将会影响到所选客户端的培训。此外,所选客户端在完成培训后可能仍然空闲。但是客户必须等到下一轮培训后才能再次被选中。此外,除了所选的设备外,其他空闲设备也没有得到充分利用。
三、贡献
- 如何利用边缘器件的空闲时间来提高不同数据分布下的模型收敛速度,是本文研究的主要问题
- 提出了时间高效的异步联邦学习(TEA-Fed),以提高FL训练效率和模型精度。TEA-Fed关键思想是在执行FL任务时更加积极高效地利用边缘设备的空闲时间。 空闲边缘设备主动申请训练任务并参与模型训练。实验结果表明,TEA-Fed显著提高了模型的收敛速度和精度。
四、算法

4.1 问题描述
由一个服务器和n个边缘设备组成的边缘计算系统。全局优化公式描述为:
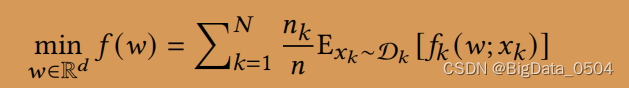
---从本地设备k数据集
中采样,其中Dk=nk
---设备k的预测损失,w为模型参数
一般情况下,边缘设备上的局部数据分布存在一定程度的差异,即总体数据非IID。
4.2 算法主要框架
-
Task Request任务请求
与传统训练方式不同,传统的是设备被动等待训练,TEA-Fed中,设备处于空闲时会向服务器发送任务请求,如果被分配了训练任务,服务器将向它发送最新的模型。
-
Task Assignment任务分配
服务器收到来自设备的任务请求后,检查当前参数训练的设备数量是否小于N.C(C为参与训练的客户端的比例,可以避免由于参与者过多导致服务器过载风险),如果当前设备小于N.C则将最新的模型参数发送给相应的客户端,否则不会发送。

-
Local Update局部更新和上传
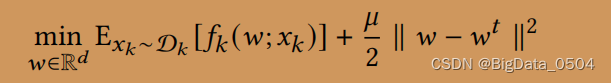
在局部优化目标上加入正则项,可以有效限制No-IID数据产生的负面影响,其中μ是正则化权值参数。惩罚项可以将局部更新限制在更接近设备接收到的初始模型,有助于减少数据异质性的影响,使模型收敛更加稳定。
-
Model Aggregation 模型聚合
参与模型训练的服务器和空闲设备以异步方式执行更新,服务器将把它收到的更新放到缓存中,并将它们用于聚合。防止缓存过多设置了一个缓存限制,超参与γ(0,1)用于控制缓存数量。

首先对缓存的更新进行加权平均,然后在最新的局部平均更新和当前的全局模型之间进行弹性平均,后者不仅保留了一定的历史状态,而且还利用了新更新的信息。这样,全局模型就可以更平稳、更快速地收敛。
更新缓存机制。在现有的方法中,服务器一旦从任何设备收到一个本地更新,就会立即更新全局模型,然后进入下一轮的培训。虽然这可以在一定程度上提高训练速度,但一个糟糕的局部更新可能会导致全局模型的分歧。为了增加模型稳定性,进一步提高模型的精度,采用了一种缓存机制。我们将缓存容量设置为[𝑁·𝛾]本地更新的大小,其中是𝛾∈(0,1)。根据每次更新的持久性,服务器在接收到局部更新的𝛾-分数后,通过加权平均来更新全局模型。在本文中,我们将𝛾的值设为0.1,这与任务分配中𝐶-分数相似。
根据稳定性进行加权平均。由于客户端和服务器异步执行更新,因此缓存中的本地更新的模型版本可能不一致。假设服务器上第𝑡轮最新的全球模型为𝑤𝑡,设备𝑘上传的更新为𝑤𝑘ℎ𝑘,其中时间戳ℎ𝑘≤𝑡,那么模型跟踪是𝑡−ℎ𝑘。关于稳定性的函数𝑆(𝑡−ℎ𝑘)如下:
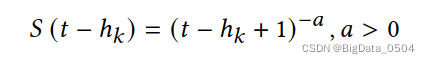
平均更新u:
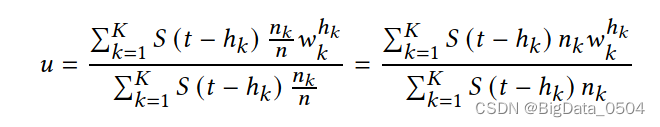
缓存中所有本地更新的平均一致性被定义为𝛿:
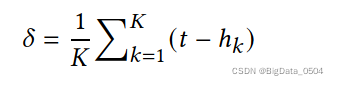
在t轮混合权重表示:
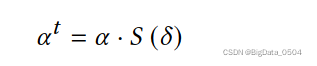
全局模型更新为:

五、实验
FedAvg和FedAsny作为baseline.
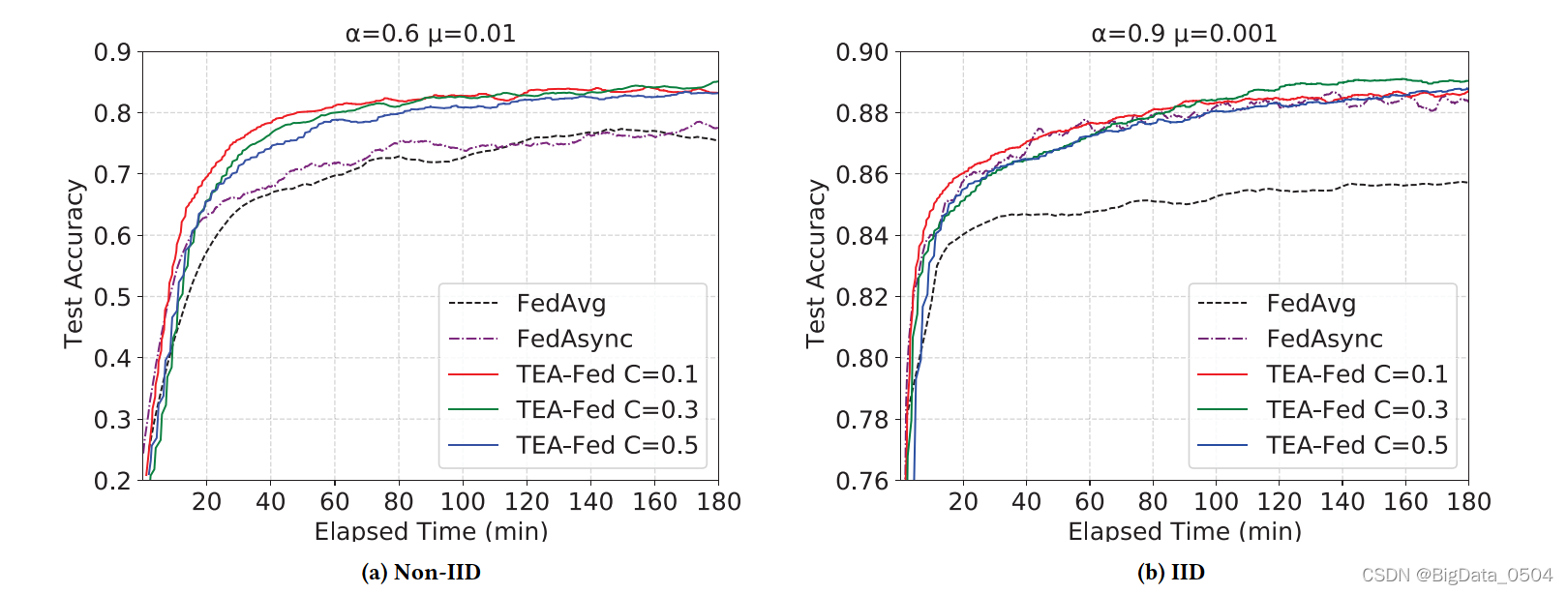
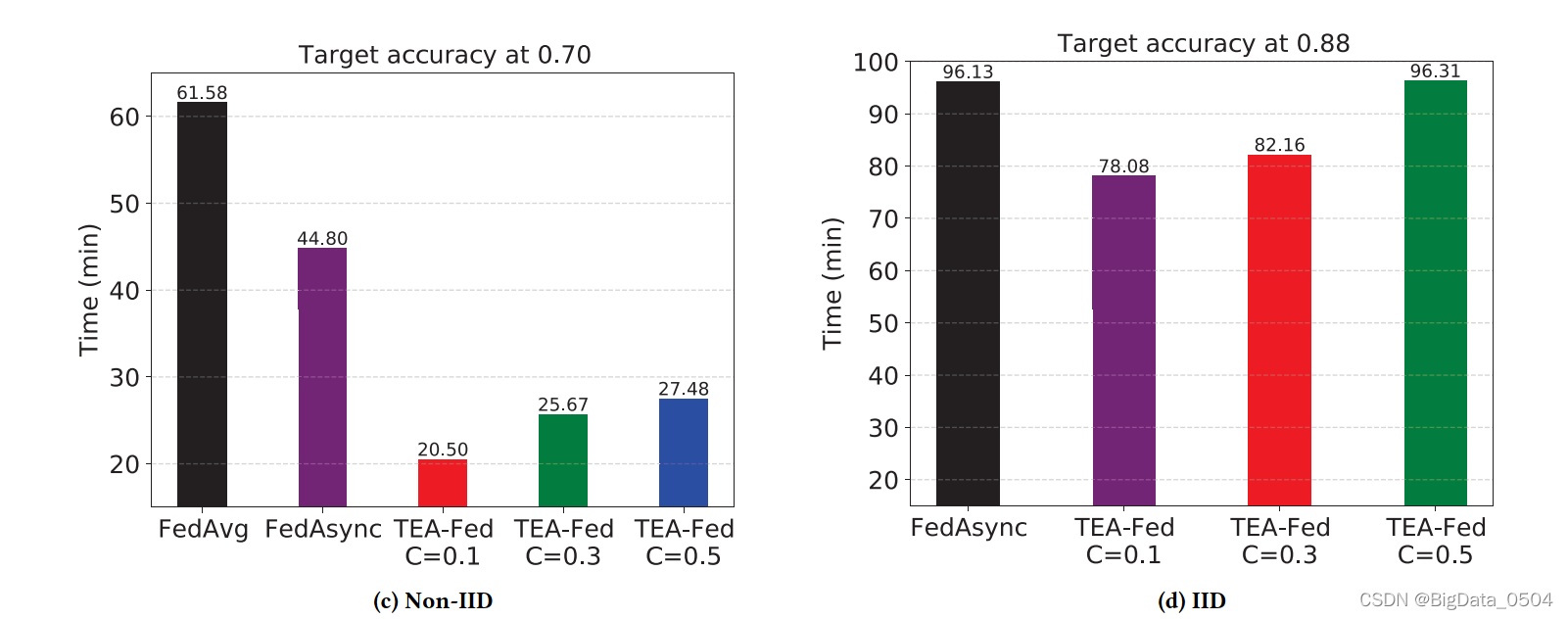
1. C对模型的影响
![]()
![]()
C与模型精度以及训练轮数不成正比。虽然增加𝐶在一定程度上提高了设备的并行性,但有太多的设备同时参与了同一时期的全局模型的训练,这可能会导致更大的延迟。C=0.1时,模型表现最好。
2. α对模型的影响
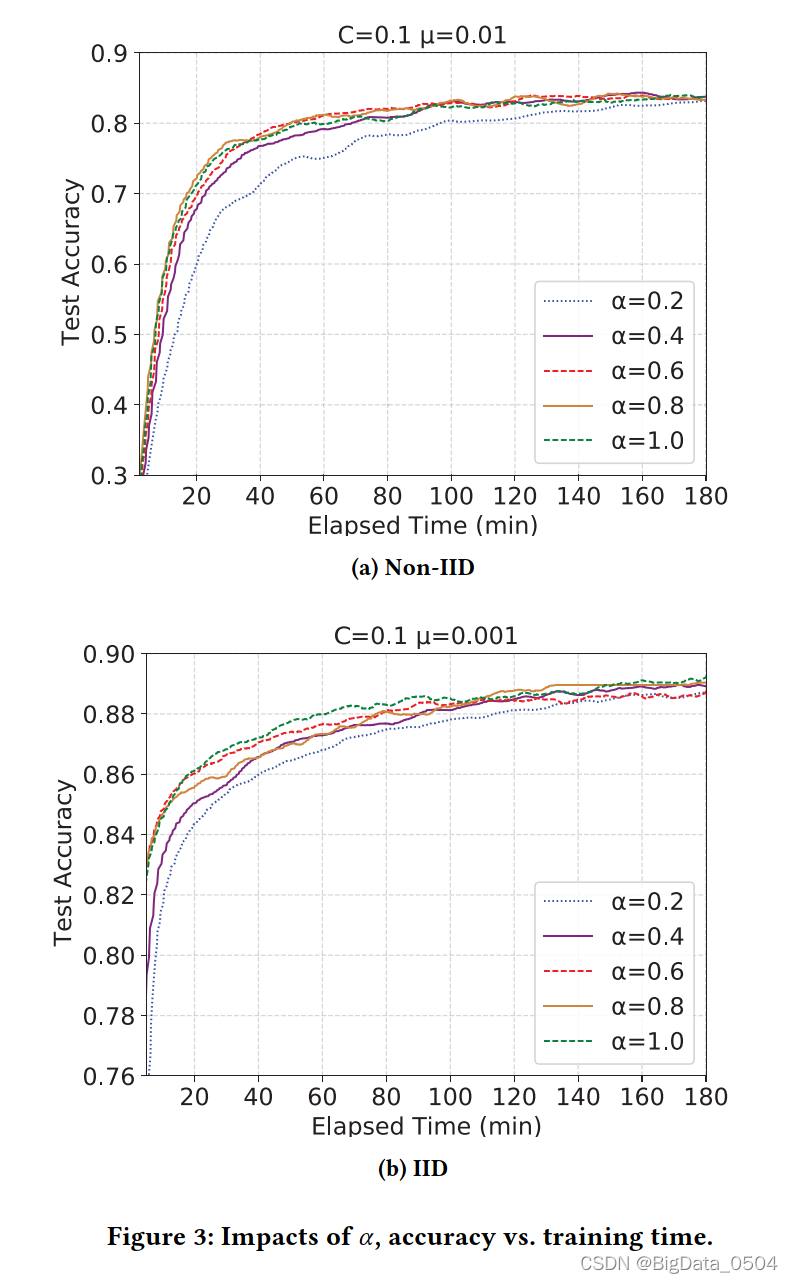
混合合超参数𝛼是在新的更新和旧的全局模型之间的权衡。𝛼的值越大,新的更新对更新后的全局模型的影响就越大。在图3中,我们研究了TEA-fed如何在不同的𝛼下工作。其中,𝛼在0.4和0.9之间对收敛的影响差异不太大,因此TEA-fed的收敛并不会随着𝛼的增加或减少而变化。
3.μ对模型的影响
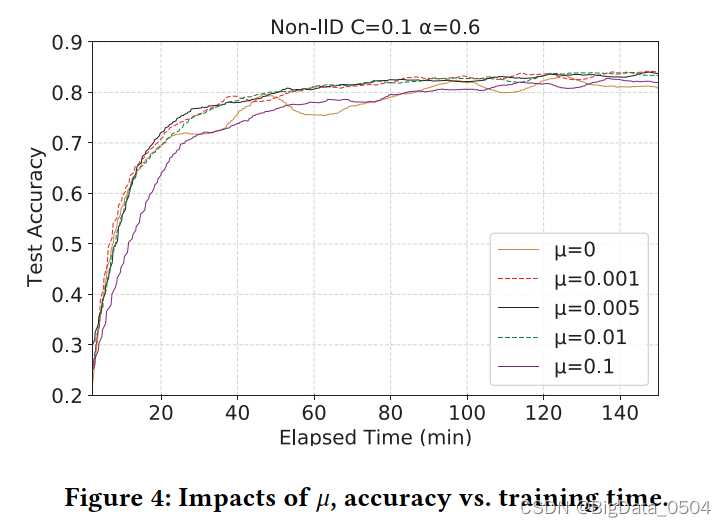
当𝜇>0时,可以显著提高异质数据的收敛效率。适当选择𝜇可以提高非IID数据方法的稳定性,提高精度,使全局模型收敛更稳定、更快.

















 2249
2249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









