







背景
现有的联邦学习方法存在通信瓶颈和收敛性两个问题,该篇论文介绍了一种新的FL训练方法,叫做FetchSGD,旨在解决上述两个问题。
论文思想
该论文的主要思想是,用Count Sketch来对模型参数进行压缩,并且根据sketch的可合并性(mergeability)在服务器上对模型进行聚合。由于Count Sketch是线性的,因此局部模型上的momentum(不知道怎么翻译好,动量?)和error accumulation(错误累计)都会被带到服务器上,我们便可以在服务器上基于这些信息得到一个更佳的聚合模型
FL问题设置
假设一个FL系统中有
C
C
C个client,数据域为
Z
Z
Z,
{
P
}
i
=
1
C
\{P\}_{i=1}^C
{P}i=1C为在
Z
Z
Z上的
C
C
C个不相关的概率分布,并且
Z
=
X
×
Y
Z = X \times Y
Z=X×Y,
X
X
X是特征空间,
Y
Y
Y是label空间,第
i
i
i个client上的数据集
D
i
D_i
Di服从分布
P
i
P_i
Pi,
W
W
W为模型的参数,
L
:
W
×
Z
−
>
R
L:W \times Z->R
L:W×Z−>R表示损失函数,然后全局的目标函数为最小化以下的损失函数:
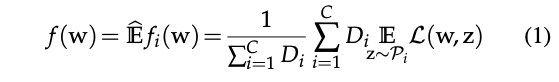
如果我们假设每一个client上的数据集大小都是一样的,那么损失函数可以简化为:
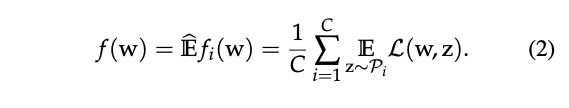
算法
在“论文思想”里面已经讲过,该算法的一个关键部分是对上传的模型参数进行Count Sketch来对模型参数进行压缩,解决的是通信瓶颈的问题,因为Count Sketch具有以下的可合并性:
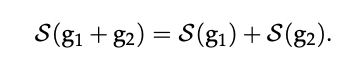
那么在服务器上进行模型聚合的时候,下面等式是成立的:
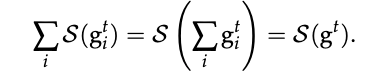
对于一个特定的Count Sketch算子
S
(
.
)
S(.)
S(.),会有一个相对应的解压缩算子
U
(
.
)
U(.)
U(.)与之对应:
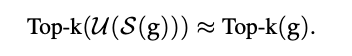
但是这种办法有一个问题:就是Top-k方法并不是一个无偏估计,那么在无偏估计下的梯度压缩方法的收敛性在使用了Top-k方法之后并不成立。为了解决这个问题,有研究指出,如果有偏差梯度压缩方法积累了由偏差梯度压缩算子产生的误差并在以后的优化中重新引入误差,则它们可以收敛,也就是我们可以通过以下办法来使得新的FL系统收敛:

同样,在client上的偏差压缩方法也会导致同样的问题,并且我们不方便在client上进行误差的重新引入,为了解决这个问题,我们将误差的重新引入这个步骤放到server中(因为Count Sketch方法是线性的,那么client上的误差也会带到server上来),具体步骤如下:

综上,整个算法如下:

算法解析:
- 首先被选择的client从server下载全局模型,然后在本地训练得到新的局部模型
- 使用Count Sketch方法对模型进行压缩,上传 S i t S_i^t Sit
- server对上传的 S i t S_i^t Sit进行聚合,然后根据上文所讲述的方法进行client端和server端的误差重新引入
- 根据 Δ t \Delta^t Δt更新全局模型
总结
该论文所描述的一个基本流程是:对上传的模型进行“压缩-解压缩”,然后因为在”压缩-解压缩“的过程中会造成一些信息的损失,并且导致系统难以收敛,因此使用了“误差重新引入”的方式来使得系统重新收敛。亮点在于“误差重新引入”的方法缓解了压缩模型所导致的信息损失的问题,个人觉得还是具备一些不错的启发性















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









