







目录
一、文献框架

二、简介和创新点
针对K均值聚类算法的缺陷,结合粒子群提出一种新的K均值聚类算法,并与现有的基于遗传算法的KMC算法进行比较,通过理论分析与数据实验,证明该算法的有效性和优越性。
三、理论综述
1. PSO算法
PSO算法采用实数编码方式,具有三个重要参数:位置、速度和适应度值;算法中每个粒子自带位置和速度两个属性,位置或称解,即解空间中的粒子,粒子根据速度在解空间中进行搜索,通过跟踪个体极值和全局极值及时地更新自己,并通过适应度函数判断新位置的适应度值,通过算法迭代搜索最优值。

2. PSO-KMC算法
首先,确定粒子。显然,由(1)可知,在PSO算法中,粒子的位置和速度均为d维变量,在基于粒子群的K均值聚类算法中,将粒子群算法的实数编码方式转变为基于聚类中心的编码方式,从样本集中随机生成k个聚类中心,粒子坐标由所生成的聚类中心点组成,编码结构由k×d维的位置变量、k×d维的速度变量以及适应度值。
其次,聚类划分。当聚类中心确定时,聚类的划分由最近邻法则决定。
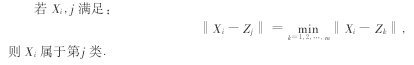
然后,粒子适应度值的计算。按照以下方法进行:

最后,算法描述。

3. 算法流程

四、实验分析
1. 数据:随机生成的三组数据,数据量分别为40个二维数据(分为两类)、400个二维数据分为两类、400个四维数据分成八类
2. 参数配置
3. 具体操作
实验1:40个二维数据(分成两类),数据量小,K-means出现对初始值敏感的问题
实验2:400个二维数据(分成两类),数据量加大,K-means对初始值敏感且陷入局部最小值;遗传聚类算法优于kmc,但也会陷入局部最小值,粒子群算法具有较强的全局寻优能力,每次均能收敛到全局最优点。
实验3:400个四维数据分成八类,观察三种算法在迭代过程中,每代群体中的最佳个体的类内离散度和的变化曲线。
4. 结果分析
根据收敛速度、是否陷入局部最优进行分析,说明所提出算法的有效性
五、疑问和思考
- 如何实现:尝试进行代码复现,或阅读相关代码
- 基于遗传算法的KMC算法原理是怎么样的,可以实现吗
- (2005年提出)迄今为止,PSO和KMC还可以如何融合
- 基于聚类中心的编码方式以及这种算法的基本思想是否适用于其他群智能算法
六、相关文献
http://www.sysengi.com/CN/abstract/abstract107259.shtml















 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









