









这么受欢迎的Transform到底解决了什么问题?
背景
在过去的十几年中,深度卷积神经网络越来越成熟,使机器视觉任务得到了空前的关注和发展,有效提高了图像信息挖掘的效率与精度,能够智能化识别、自动化分析输入的图像数据。然而,随着不断地应用和改进,卷积神经网络固有的缺点越来越明显,即每个卷积只考虑局部区域,无法对长距离像素依赖进行建模。
基于卷积神经网络(CNN)
为解决这一缺点很多学者提出了不同的方法。2014年,何恺明等人提出空间金字塔池化(Spatial Pyramid Pooling),将输入特征图分为多个尺度,然后,对每个尺度进行池化操作,得到多个不同尺度的特征图[1]。2015年,何恺明等人提出残差网络,即通过显式地引入跨层连接来解决深层网络训练中的退化问题,有效地减轻了梯度消失和梯度爆炸的问题,使得可以训练更深的网络适应更复杂的任务[2]。2016年,Huang等人提出DenseNet模型,是建立在后面层与前面所有层的密集连接(Dense Connection),另外,通过特征在channel维度上的连接来实现特征重用(Feature Reuse)。DenseNet缓解了梯度消失问题,加强了特征传播,鼓励了特征重用,并大大减少了参数的数量[3]。2021年,Liu等人提出空洞卷积,该方法在降低了图像尺寸的同时增大感受野而且无需引入额外的计算,但是会导致细粒度信息严重丢失,只能应用于大尺寸图像处理或大目标检测[4]。
虽然通过增加网络深度、图像数据通道、多尺度提取图像特征以及增大感受野等方法能够学习到长距离数据之间依赖关系,但很大程度上增加了网络模型的复杂性,甚至会将丢失部分数据作为代价。
基于注意力机制的神经网络
近几年,随着Transformer应用在视觉领域,不仅提升了网络模型提取图像特征的性能,而且基于Transformer架构的自注意力机制能够编码上下文的长期依赖关系并进行学习,弥补了卷积神经架构的不足。目前,基于Transformer的网络模型已经被广泛应用于图像分类、分割以及目标检测等视觉领域。2019年,Dosovitskiy等人提出ViT模型将图像数据转化为序列数据进行视觉任务分类,第一次将Transformer应用在图像领域,具有较大的开创性意义并在实验中展现了很好的效果[5];同时,Wang等人也提出基于高度和宽度的轴向注意力,减少计算亲和度的同时更好的捕获像素之间长距离依赖关系[6];同年,Huang等人提出克里斯交叉网络(CCNet),即使用交叉的注意模块,捕获长距离依赖中的上下文信息[7]。还有最为人们所熟知的就是Swin Transformer模型,是Liu等人[8]在2021年提出的一种基于移动窗口注意力机制的深度学习模型。它将图像划分为固定大小的非重叠窗口,并在每个窗口内进行注意力计算,这种方法减少了计算和内存开销,并且保持了全局上下文的感知能力。同时,Swin Transformer还引入了一种跨窗口的注意力机制,通过在窗口之间进行信息交流,增强了模型的表达能力。虽然,基于Transformer的网络模型能够很好的提取图像数据的特征,但是,需要大规模的数据集来进行训练且计算量之大对硬件要求高。
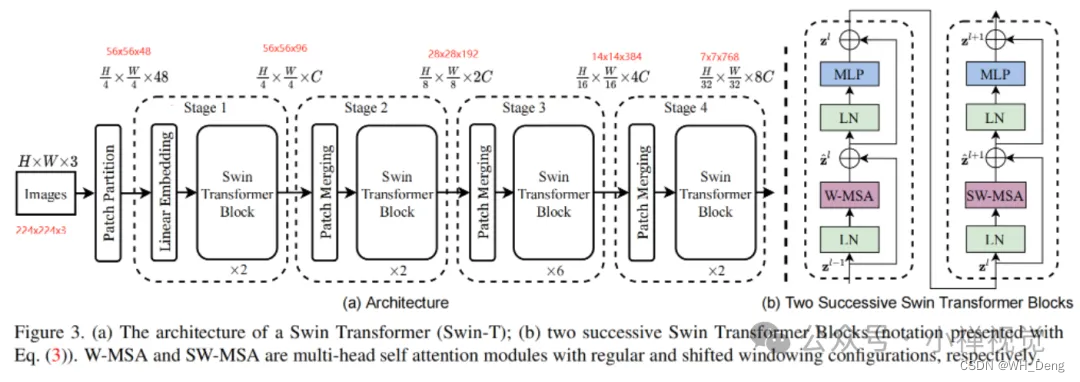
Swin Transform的网络模型图
大语言模型ChatGPT
ChatGPT作为人工智能领域在自然语言处理技术上打响的一枪,随着ChatGPT4.0的免费使用,更是引起广泛的关注。随着ChatGPT模型的不断优化,已经能够处理复杂的语言问题,同时还具有更好地上下文理解和自然度,这得益于其底层的Transform。
曾今就有人说,如果大语言模型没有理解上下文意思,怎么可能给出您想要的答案。很明显,如今看来,ChatGPT不仅能够理解语言,而且能够给出答案。随着国内更多的“生成式人工智能”的涌现,也促使国内很多大厂、研究所以及高校老师和学生跟风学习,以便将其赋能于其他领域。
ChatGPT的出现,掀起了“生成式人工智能”的浪花,随着而来的是Sora被OpenAI称为“世界模拟器”,影响这各行各业。

总结
目前有很多注意力机制的变形体,轴注意力机制、交叉注意力机制、窗口注意力机制、十字注意力机制以及基于超像素的注意力机制。其中,最大的瓶颈就是,使用注意力机制计算会使模型参数成几何级增加,使用单一注意力机制又不能很好的获得整体特征,难免会丧失长距离或像素块间的依赖关系,导致很难应用在一些具有特殊性的图像而言。
随着ChatGPT的应用,我们应该认识到对ChatGPT提出的问题(咒语或提示词)十分关键,高质量的标准化,规范化提示词,能够更好的让机器理解,并得到想要的答案,否则机器回答的可能牛唇不对马嘴。未来,如何提出好的问题(咒语),也是人们在利用人工智能时的重点。与此同时,从侧面也反映出只有高质量的标准化,规范化以及流水线式方法,才能更好的引领发展。
参考
[1]He, Kaiming et al. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.” IEEE Transactions on Pattern Analysis and Machine Intelligence 37 (2014): 1904-1916.
[2]He, Kaiming et al. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015): 770-778.
[3]Huang, Gao et al. “Densely Connected Convolutional Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 2261-2269.
[4]Liu, Jie et al. “Inception Convolution with Efficient Dilation Search.” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020): 11481-11490.
[5]Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner,T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
[6]Wang, Xiaolong , et al. “Non-local Neural Networks.” (2017).
[7]Huang, Zilong et al. “CCNet: Criss-Cross Attention for Semantic Segmentation.” 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2018): 603-612.
[8]Liu, Ze et al. “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.” 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (2021): 9992-10002.















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









