






Transformer:机器学习中的Transformer是一种使用注意力机制、以对输入数据的每个部分的重要性进行差异加权的深度学习模型。
Transformer - Attention is all you need - 知乎 (zhihu.com)
熬了一晚上,我从零实现了Transformer模型,把代码讲给你听 - 知乎 (zhihu.com)
熬了一晚上,我从零实现了Transformer模型,把代码讲给你听 - 知乎 (zhihu.com)
一文读懂: Transformer(无代码) - 知乎 (zhihu.com)

黑框里 左边是encoder 右边是decoder
每个encoder里的参数不一样
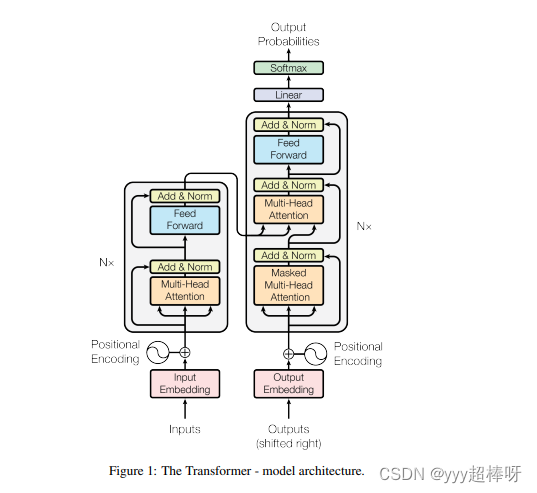
Embedding部分接受原始的文本输入(batch_size*seq_len,例:[[1,3,10,5],[3,4,5],[5,3,1,1]]),叠加一个普通的Embedding层以及一个Positional Embedding层,输出最后结果。
普通的 Embedding 层想说两点:(将词变成向量)
- 采用
torch.nn.Embedding实现embedding操作。需要关注的一点是论文中提到的Mask机制,包括padding_mask以及sequence_mask(具体请见文章开头给出的理论讲解那篇文章)。在文本输入之前,我们需要进行padding统一长度,padding_mask的实现可以借助torch.nn.Embedding中的padding_idx参数。 - 在padding过程中,短补长截
positional encoding:位置向量
将词向量和位置向量相加。
前馈神经网络(Feedforward Neural Network)是最基本的神经网络模型之一。前馈神经网络也被称为多层感知机(Multilayer Perceptron,MLP),其结构由多个全连接层组成,其中每个层都包含多个节点(神经元)。
LSTM(Long Short-Term Memory,长短时记忆)是一种常用于处理序列数据的循环神经网络结构。
想象一下,即假如我们要对一个句子里的每个单词进行词性的判断,这时我们的输入是:一个句子,其中每个单词是一个向量,一个句子包含多个向量,我们的输出是:词性,每个词性是一个类别,每个单词具有对应的词性。输入是n个序列,输出是n个类别。如果是机器翻译的话,那输入是一个句子,输出也是一个句子,这就是seq2seq.(序列对序列)
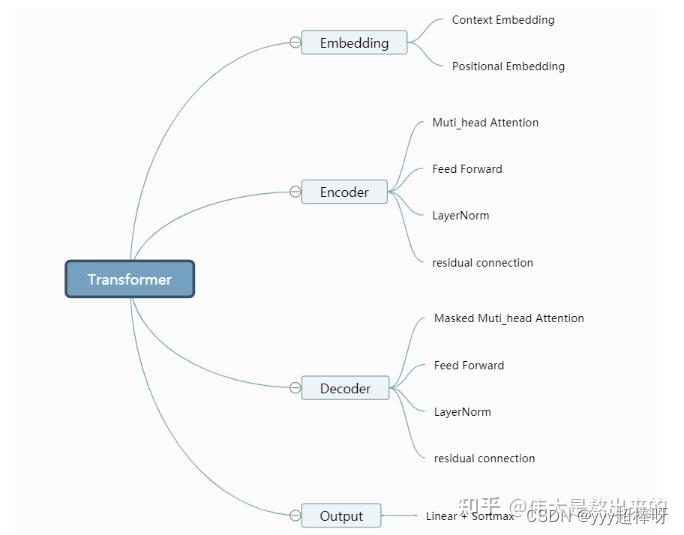
Q(Query)、K(Key)和V(Value)可以理解为是序列、键值和权重的概念。具体而言,Q、K、V在Transformer模型中是用来计算注意力(Attention)的三个矩阵,它们分别表示:
- Query(查询):在注意力机制中,Query通常是当前时刻的输入向量,用于计算与其它位置的相似度得分。
- Key(键):在注意力机制中,Key通常是历史时刻的状态向量,用于计算与当前Query的相似度得分。
- Value(值):在注意力机制中,Value通常是历史时刻的输出向量,即编码器的所有隐藏状态向量,它们被赋予不同的权重,用于生成当前时刻的输出。
-
在序列模型中,隐藏状态是模型在处理输入序列时的内部表示。在语言模型中,每个词都有一个对应的隐藏状态,它包含了该词在当前上下文中的语义信息。在处理序列时,模型会逐个词进行处理,并根据前一个词的隐藏状态来生成下一个词的隐藏状态。这种逐个处理的方式保证了模型能够按照序列的顺序逐步捕捉到不同位置的语义信息。
因此,Q、K、V可以被看作是序列中不同位置的向量表示,它们之间的相似度得分用于计算注意力权重,从而影响最终的输出结果。通过Transformer模型的多头注意力机制,Q、K、V可以同时捕捉到不同位置之间的关系,实现更加精确的上下文建模。
Layer Normalization(层归一化)是一种常见的神经网络正则化技术,用于在神经网络中标准化每个输入特征。它与 Batch Normalization(批归一化)相似,但是不同之处在于,Batch Normalization 是在 mini-batch 上进行标准化,而 Layer Normalization 是在每个样本的特征维度上进行标准化。
transformer采用encoder-decoder架构,如下图所示。Encoder层和Decoder层分别由6个相同的encoder和decoder堆叠而成,模型架构更加复杂。其中,Encoder层引入了Muti-Head机制,可以并行计算,Decoder层仍旧需要串行计算。
缩放点积注意力(Scaled Dot-Product Attention)是Transformer模型中用于计算注意力权重的一种机制。在Transformer的自注意力机制中,通过比较查询(Query)和键(Key)的相似度来计算注意力权重,然后将注意力权重应用于值(Value)以获得最终的上下文表示。
使用Positional Encoding的优势
优势1
- transformer中,模型输入encoder的每个token向量由两部分加和而成
- Position Encoding
- Input Embedding
- transformer的特性使得输入encoder的向量之间完全平等(不存在RNN的recurrent结构),token的实际位置于位置信息编码唯一绑定。Positional Encoding的引入使得模型能够充分利用token在sequence中的位置信息。
-
Multi-Head Self Attention Laye(MSP):该层将所有注意力输出线性连接到正确的维度。较多的Attention Head有助于训练图像中的局部和全局依赖性。
-
Multi-Layer Percetrons Layer(MLP):该层包含两层高斯误差线性单元(GELU)。
-
Layer Norm(LN):这是在每个块之前添加的,因为它不包括训练图像之间的任何新相关性。这有助于提高训练时间和整体表现。
此外,在每个块之后还有残差连接(Residual Connection),残差连接允许组件直接流过网络而不经过非线性激活。
Swin Transformer:
(Vision Transformers)ViT:基于注意力机制的图像分类模型,ViT是一个基于最初为基于文本的任务设计的Transformer架构的视觉模型。ViT模型将输入图像表示为一系列图像块并直接预测图像的类标签,就像使用Transformer进行文本处理时使用的一系列单词嵌入一样。当对足够的数据进行训练时,ViT表现出很好的性能,以四分之一的计算资源打破了类似的CNN的性能。
Vision Transformer的总体架构以逐步的方式给出如下:
-
将图像拆分为块(固定大小)
-
压平图像块
-
从这些扁平图像块创建低维线性嵌入
-
包括位置嵌入
-
将序列作为输入馈送至最先进的Transformer编码器
-
使用图像标签预训练ViT模型,然后在大数据集上对其进行全面监督
-
微调下游数据集进行图像分类

GitHub - google-research/vision_transformer
感知机(Perceptron)是一种简单的二分类线性分类模型,它是机器学习领域的一个经典算法。
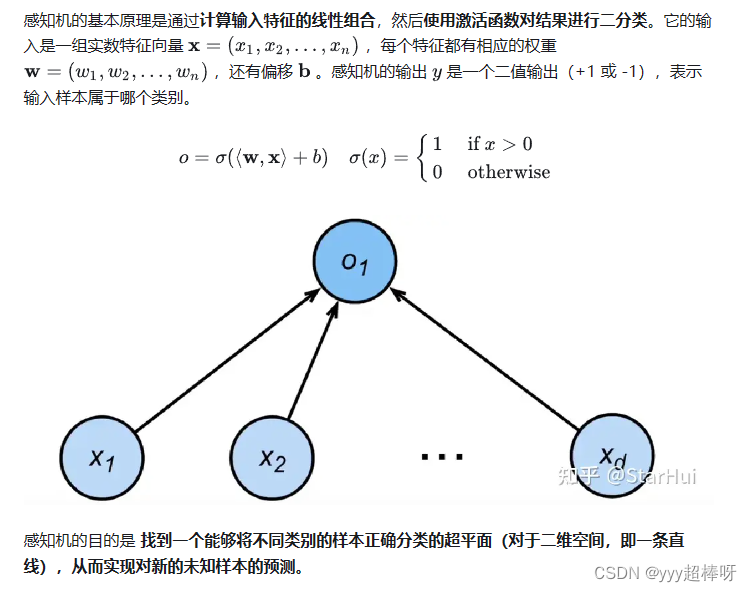
MLP多层感知机:我们可以通过在网络中 加入一个或多个隐藏层 来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前 �−1 层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。

多头自注意力机制:
visual Token:图像块。视觉Transformer将图像分成固定大小的块,正确地嵌入每个块,并连同位置嵌入信息一起作为Transformer编码器的输入。
ViT中的 LayerNorm 归一化层和GELU激活函数是导致ViT在dehaze任务上表现不好的原因
作者设计了RescaleNorm取代LayerNorm层,ReLU 取代GELU,空间信息聚合方案。
数据集:RESIDE数据集是一个大规模的均匀图像去雾数据集,它促进了图像去雾。然而,评估该方法对非均匀图像去雾的能力仍然依赖于一些小的、不切实际的数据集[46],这些数据集使用雾机来生成几乎不存在的非均匀雾。相比之下,遥感图像去雾是一项实用的非均匀图像去雾任务,因为遥感图像中的雾具有高度的非均匀性,因此,本文提出了一种新的遥感图像去雾数据集RS-Haze,与已有的遥感图像去雾数据集[55,56,76,77]相比,该数据集更真实,规模更大。
本文的数据集为RESIDE和作者自制的数据集RS-Haze
Vision Transformers的网络结构:
文件代码:
config:配置文件,通常用于保存模型的各种超参数和设置,以便在训练、测试或推理时使用。通过使用配置文件,我们可以更灵活地调整模型的设置,而无需直接修改代码。

datasets:加载和处理图像数据集

figs:模型架构图
models:dehazeformer模型的代码
utils:工具类。

common.py:用于分布式训练的工具类
data_parallel.py:是一个工具函数集合,用于处理图像数据和计算统计指标。
__init__.py:导入上面两个工具类。
test.py:测试代码
train.py:运行代码














 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









