






这是篇基于Swin transformer来设计的图像去雾网络,损失函数选择L1。
1.整体架构
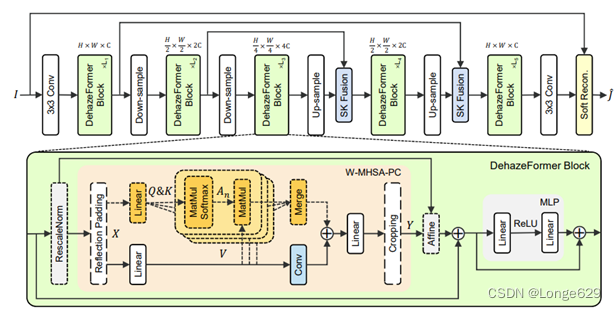
整体的网络架构是类U-net结构,图中DehazeFormer块中用虚线框表示的组件表示可选,MHSA和RescaleNorm、镜像填充和裁剪cropping仅在需要移动窗口分区时使用。
回顾Swin transformer:给定输入特征图X,用线性层映射到QKV上,使用窗口分区对token进行分组。下面的Q, K, V对应于单个窗口和头,其中l是窗口中的token,d是维度。自注意表示为:
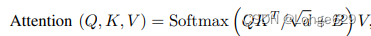
其中B是相对位置偏置项。一个线性层跟随它来映射注意力的输出。
DehazeFormer块不同于原来的Swin Transformer,SK融合层和软重建层来取代拼接融合层和全局残差学习。SK融合层来自于SKNet,即使用通道注意力来融合多个分支。设两个特征图x1,x2用映射层f将x1映射为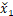 ,作者使用平均池化GAP(·),MLP (Linear-ReLU-Linear) FMLP(·)等运算得到权值:
,作者使用平均池化GAP(·),MLP (Linear-ReLU-Linear) FMLP(·)等运算得到权值:
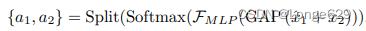
下一步使用权重{a1, a2}来融合x 1, x2,方式为y = a1x 1 + a2x2 + x2。目前去雾网络一般预测重建图像J (x)或全局残差R(x) = J (x)−I(x)。在退化模型是一个近似值,且没有强约束的情况下引入先验是有益的,将模糊图像退化公式改写为:
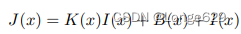
该公式就是软重构,其中,K (x) = 1 / t (x)−1并且B (x) =−(1 / t (x)−1)A。用网络预测O,并将O分成K,R。因此,网络架构软限制了K(x)和B(x)之间的关系,这种弱先验允许网络退化以预测全局残差(即K(x) = 0, B(x) = R(x))。
2.RescaleNorm
回顾LayerNorm,假设特征映射的形状x∈R b×n×c,其中n = h × w(即高度和宽度),归一化过程可表示为:
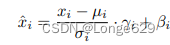
其中µ和σ表示均值和标准差,γ和β表示学习因子和偏差,i = (ib, in, ic)。在LayerNorm中,μ和σ沿c轴计算,使得µ,σ∈R b×n。
改进:作者认为均值和标准差与图像的亮度和对比度是相关的,所以在LayerNorm之后,将patch之间的相对亮度和对比度丢弃。对此,沿着(n, c)轴计算µ和σ,从而得到µ,σ∈R b。这种归一化方法称LayerNorm†。
对比:当插入LayerNorm后,清楚地看到有斑块出现在重建图像中。由于这种自编码不涉及patch间的相互作用,它只能以牺牲富纹理区域为代价来记忆天空区域的统计信息。通过改变LayerNorm为LayerNorm†,结果上很大程度上克服了负面影响。下图是分析归一化方法的自编码器。从左到右是自编码器架构、输出图像和误差图。

再改进:LayerNorm†仍然丢弃了特征映射的平均值和标准差。所以作者提出Rescale层规范化(RescaleNorm),它计算的均值和标准差被保存并在残差块的末尾引入。具体来说,先取µ,σ∈R b×1×1,并通过LN公式将输入特征映射x归一化为x1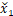 。然后,使用F(·)来处理
。然后,使用F(·)来处理 以获得
以获得 的输出。
的输出。
使用权重为Wγ, Wβ∈R的两个线性层1×c和偏差Bγ,Bβ∈R,1×1×c转换μ和σ通过{γ, β} ={σWγ +Bγ,µWβ +Bβ},其中γ,β∈R b×1×c。为加速收敛,作者将Bγ和Bβ初始化为1和0。将γ和β注入到y中,以重新引入平均值和标准偏差:
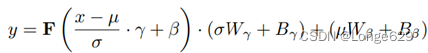
3. SoftReLU
实验中,ReLU和LeakyReLU在图像去雾方面优于GELU。因为GELU不容易反转。如果把GELU看作一个图像滤波器,由于它的非单调性,会引起梯度反转问题。GELU性能较差的另一个原因是GELU的非线性较强,因此,这里提出了SoftReLU,它是一个近似ReLU的平滑函数:
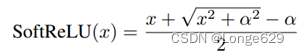
其中α是形状参数。设α = 0时,SoftReLU等价于ReLU。为了模拟GELU,在实验中设置α = 0.1。
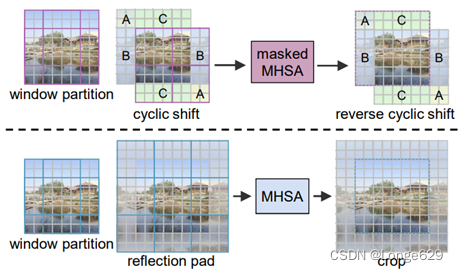
4. 带有镜像填充的移位窗口分区
Swin Transformer使用带有屏蔽MHSA的循环移位来实现移位窗口分区的patch处理。由于屏蔽,图像边缘的窗口大小小于设置的窗口大小。对于图像去雾,图像边缘和图像中心同样重要。较小的窗口导致窗口中的token数量更少,这会使网络的训练产生偏差。Swin Transformer提出的填充方案相当于循环移位。于是作者使用镜像填充而不掩蔽。这种方法的缺点是引入了计算成本。幸运的是,当图像尺寸变大时,边缘区域的百分比会变小。
5. W-MHSA-PC
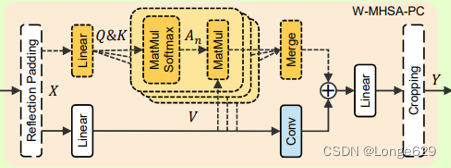
虽然MHSA的空间信息聚合权值是动态的,但其权值始终为正,具有平滑作用。与MHSA的空间信息聚合对应,文章在V上卷积,所以新的空间信息聚合公式:
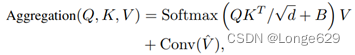
其中V表示窗口分区前的V, Conv(·)既可以是DWConv也可以是ConvBlock(Conv-ReLU-Conv)。也就是仍用注意机制来聚合窗口内的信息,同时使用卷积来聚合邻域内的信息,而不考虑窗口划分。此外,文章在某些编码浅层和解码层块中丢弃了MHSA。
这里使用卷积来提取高频信息,而不是作为位置嵌入。DehazeFormer的卷积层是在窗口划分之前在V上执行的,因此它增强在窗口之间聚合信息的能力。














 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









