







摘要-图像去雾是一种具有代表性的低级视觉任务,从模糊图像中估计出潜在的无雾图像。近年来,基于卷积神经网络的方法主导了图像去雾。然而,最近在高级视觉任务中取得突破的视觉Transformers,并没有为图像去雾带来新的维度。我们从流行的Swin Transformer开始,发现它的几个关键设计不适合图像去雾。为了为此,我们提出了DehazeFormer,它包括各种改进,例如修改的归一化层,激活函数和空间信息聚合方案。我们在各种数据集上训练DehazeFormer的多个变体,以证明其有效性。具体来说,在最常用的SOTS室内数据集上,我们的小模型仅用25%的参数和5%的计算成本就优于FFA-Net。据我们所知,我们的大模型是第一个在SOTS室内数据集上PSNR超过40 dB的方法,大大优于以前的最先进的方法。我们还收集了一个大规模的现实遥感去雾数据集,用于评估该方法 (代码)https://github.com/IDKiro/DehazeFormer.
索引术语-图像处理,图像去雾,深度学习,视觉Transformer。
一.导言
HAZE是一种常见的大气现象,会损害日常生活和机器视觉系统。雾霾的存在降低了现场的能见度,影响了人们对物体的判断,浓雾甚至会影响交通安全。对于计算机视觉来说,雾霾在大多数情况下会降低捕获图像的质量。它可能会影响模型在高级视觉任务中的可靠性,进一步误导机器系统,如自动驾驶。所有这些都使得图像去除成为一项有意义的低层视觉任务。
图像去霾的目的是从观测到的雾霾图像中估计出潜在的无雾霾图像。对于单幅图像去霾问题,有一个流行的模型[1-3]来刻画模糊图像的退化过程:
![]()
其中I是捕获的模糊图像,J是潜在的无模糊图像,A是全局大气光,t是介质透射图。
![]()
其中β是大气的散射系数,d是场景深度。由此可见,图像去雾是一种典型的不适定问题,早期的图像去雾方法倾向于用先验知识来约束解空间[4-7]。他们通常分别估计A和t(x)以降低问题的复杂性,然后使用等式(1)来推导结果。这些基于先验知识的方法可以产生具有良好可见性的图像。然而,这些图像通常与无雾图像明显不同,并且可能在不满足先验的区域中引入伪影。
近年来,深度学习在计算机视觉领域取得了巨大的成功,研究人员提出了大量基于深度卷积神经网络(CNN)的图像去雾方法[8-21]。在足够数量的合成图像对的情况下,这些方法可以实现优于基于先验的方法的性能。早期的基于CNN的方法[8-10]还分别估计A和t(x),其中t(x)使用在合成数据集时使用的传输图来监督。
目前的方法[13-20]更倾向于预测潜在的无雾图像或无雾图像的残差与模糊图像,因为它往往会实现更好的性能。最近,ViT [22]在使用普通Transformer架构的高级视觉任务中表现优于几乎所有CNN架构。随后,提出了许多修改的架构[23-40],视觉Transformer正在挑战CNN在高级视觉任务中的主导地位。许多工作已经证明了视觉Transformer的有效性,但仍然没有基于Transformer的图像去雾方法击败最先进的图像去雾网络。在这项工作中,我们提出了一种名为DehazeFormer的图像去雾Transformer,这是受到Swin Transformer [30]的启发。它大大超过了这些基于CNN的方法。
我们发现,视觉 Transformer中常用的LayerNorm [41]和GELU [42]损害了图像去雾性能。具体来说,视觉 Transformer中使用的LayerNorm将图像块对应的token分别归一化,导致块之间的相关性丧失。因此,我们去除了多层感知器(MLP)之前的归一化层并提出RescaleNorm来代替LayerNorm,RescaleNorm对整个特征图进行归一化,重新引入归一化后丢失的特征图的均值和方差。
此外,SiLU / Swish [43]和GELU在高级视觉任务中表现良好,但ReLU [44]在图像去雾方面表现更好。我们认为这是因为它们引入的非线性在解码时不容易逆转。我们认为图像去雾不仅需要网络编码高度表达的特征,而且这些特征很容易恢复到图像域信号。
Swin Transformer采用循环移位的窗口划分方法有效地聚集局部特征,但在图像去雾中发现循环移位对于图像边缘区域是次优的,具体地说,循环移位应该使用掩蔽的多头自注意(MHSA)来防止不合理的空间聚集,使边缘区域的窗口更小。我们认为在一个小窗口内聚合信息会带来不稳定性,这可能会使网络的训练产生偏差。因此,我们提出了一种基于反射填充和裁剪的移位窗口分区方案,该方案允许MHSA丢弃掩码并实现恒定的窗口大小。我们还发现MHSA的聚合权重始终为正,这使得它表现得像低通滤波器[29]。由于MHSA的聚合权重是动态的、全正的和归一化的,我们认为静态的、可学习的和无约束的聚合权重有助于补充MHSA,而卷积满足这一标准。
此外,我们还提出了一个基于先验知识的软重建模块,它的性能优于全局残差学习,并提出了一个基于SKNet [45]的多尺度特征图融合模块,以取代级联融合。我们的实验表明,DehazeFormer能够以较低的开销显著优于同时期的方法。图1显示了在SOTS室内数据集上DehazeFormer与其他图像去雾方法的比较。我们的小型模型仅用25%的#Param和5%的计算成本击败了FFA-Net [18]。我们的基本模型开销较低,但性能优于之前的最新方法AECR-Net [19]。据我们所知,我们的大型模型是第一种超过40 dB的方法,大大优于同时期的方法。
有一些非均匀的图像去雾数据集是使用专业的烟雾机收集的[46],但它们太小,与自然场景中存在的非均匀烟雾相去甚远。相反,我们倾向于收集遥感图像去雾数据集,因为高度非均匀的烟雾在遥感图像中很普遍。我们考虑了波长等因素对雾霾空间分布的影响,然后合成了一个大规模的真实感遥感图像去雾数据集。
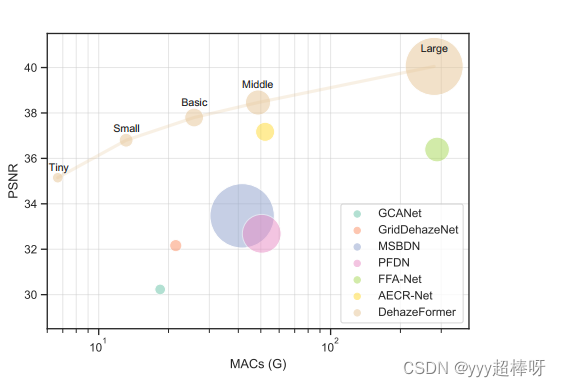
图1. DehazeFormer与其他图像去雾方法在SOTS室内数据集上的比较。点的大小表示方法的#Param,横轴表示每个算法的计算复杂度。(这句话是在讲述一项关于图像去雾算法 DehazeFormer 的对比实验结果。SOTS indoor 是一个标准的图像去雾测试数据集,用于评估不同算法在去除室内图像中的雾霾效果。该实验结果使用图形的方式来展示 DehazeFormer 和其他相关方法之间的性能差异。在图形中,每个点代表一个算法,点的大小表示该算法所使用的参数数量(#Param),点的颜色和形状则没有特殊意义。图形的 X 轴是每个算法的计算复杂度,以 MACs 的形式衡量(MACs 是 Multiply–accumulate Operations 的缩写,是计算机视觉中常用的浮点运算计数器)。Y 轴是图像去雾算法的性能,以 PSNR(Peak Signal-to-Noise Ratio)的形式衡量,PSNR 数值越高表示去雾效果越好。通过这个图形,我们可以看出 DehazeFormer 在相同的计算复杂度下,相对于其他算法,其性能更好。同时,DehazeFormer 所使用的参数数量也相对较少,说明其在计算效率和模型精简性方面都表现出色。)
二、相关工作
A.图像去雾
早期的单图像去雾方法通常基于手工先验,例如暗通道先验(DCP)[4],颜色衰减先验(CAP)[6],颜色线[5]和Hazelines [7]。这些基于先验的方法通常产生具有良好可见性的图像。然而,由于这些先验是基于经验统计的,当场景不满足这些先验时,这些去雾方法往往会输出不切实际的结果。随着深度学习的快速发展,近年来基于学习的去雾方法占据了主导地位。DehazeNet [8]和MSCNN [9]是将CNN应用于图像去雾的先驱。它们学习估计t并获得结果以及通过常规方法估计的A。之后,DCPDN [10]使用两个子网络分别估计t和A,而GFN [12]估计三个预定义图像操作的融合系数图。另一方面,AOD-Net [11],重写等式(1),使得网络仅需要估计一个分量。GridDehazeNet [13]提出,学习恢复图像比估计t更好,因为后者会陷入次优解。最近的工作[14-20]倾向于估计无雾图像或无雾图像与有雾图像之间的残差。
由于基于学习的方法的去雾性能很大程度上取决于数据集的质量和大小,因此已经提出了几种数据集。这些去雾数据集分为两大类:真实的数据集[46-49]和合成数据集[50-52]。真实的数据集使用专业烟雾机产生的真实的烟雾来生成真实的烟雾图像。合成数据集通常使用等式。(1)将相应的雾度图像与无雾度图像和深度图进行合成。虽然真实的数据集看起来更有吸引力,但难以获得足够的图像对,并且由雾度机器产生的雾度的分布仍然与真实的雾度有显著差异。因此,大多数方法倾向于使用合成数据集进行训练和测试。与这些数据集相比,本文提出了一个新的合成遥感图像去雾数据集,称为RS-Haze,用于评估该方法去除高度非均匀雾霾的能力。RS-Haze比以前的数据集[53-56]更大,更真实,考虑了传感器特性,雾霾分布和颗粒大小,光波长以及其他被忽略的因素。
B.视觉变换器
CNN多年来一直主导着大多数计算机视觉任务,而最近,Vision Transformer(ViT)[57]架构显示出取代CNN的能力。ViT开创了Transformer架构[22]的直接应用,该架构通过分片线性嵌入将图像投影到令牌序列中。原始ViT的缺点是其弱感应偏差和二次计算成本。为此,PVT [23]使用金字塔架构来引入多尺度归
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









