







1. 摘要
本文介绍了一种名为DehazeFormer的图像去雾方法,该方法基于视觉Transformer模型,并对Swin Transformer进行了改进,包括修改归一化层、激活函数和空间信息聚合方案等。作者在多个数据集上训练了多个变体的DehazeFormer,并证明其有效性。在常用的SOTS室内数据集上,小型模型仅使用25%的参数和5%的计算成本就超过了FFA-Net。此外,作者还收集了一个大规模的遥感去雾数据集以评估该方法处理非均匀雾霾的能力。最终结果表明,大型模型在SOTS室内数据集上的PSNR超过40dB,显著优于先前的最佳方法。作者还在GitHub上分享了代码和数据集。地址将在文章结尾给出
2. 论文方法
2.1 方法描述
本文提出的 DehazeFormer 是一种基于 Swin Transformer 的图像去雾网络,其主要贡献在于针对图像去雾任务的特点进行了网络架构的优化。以下是该模型结构图:
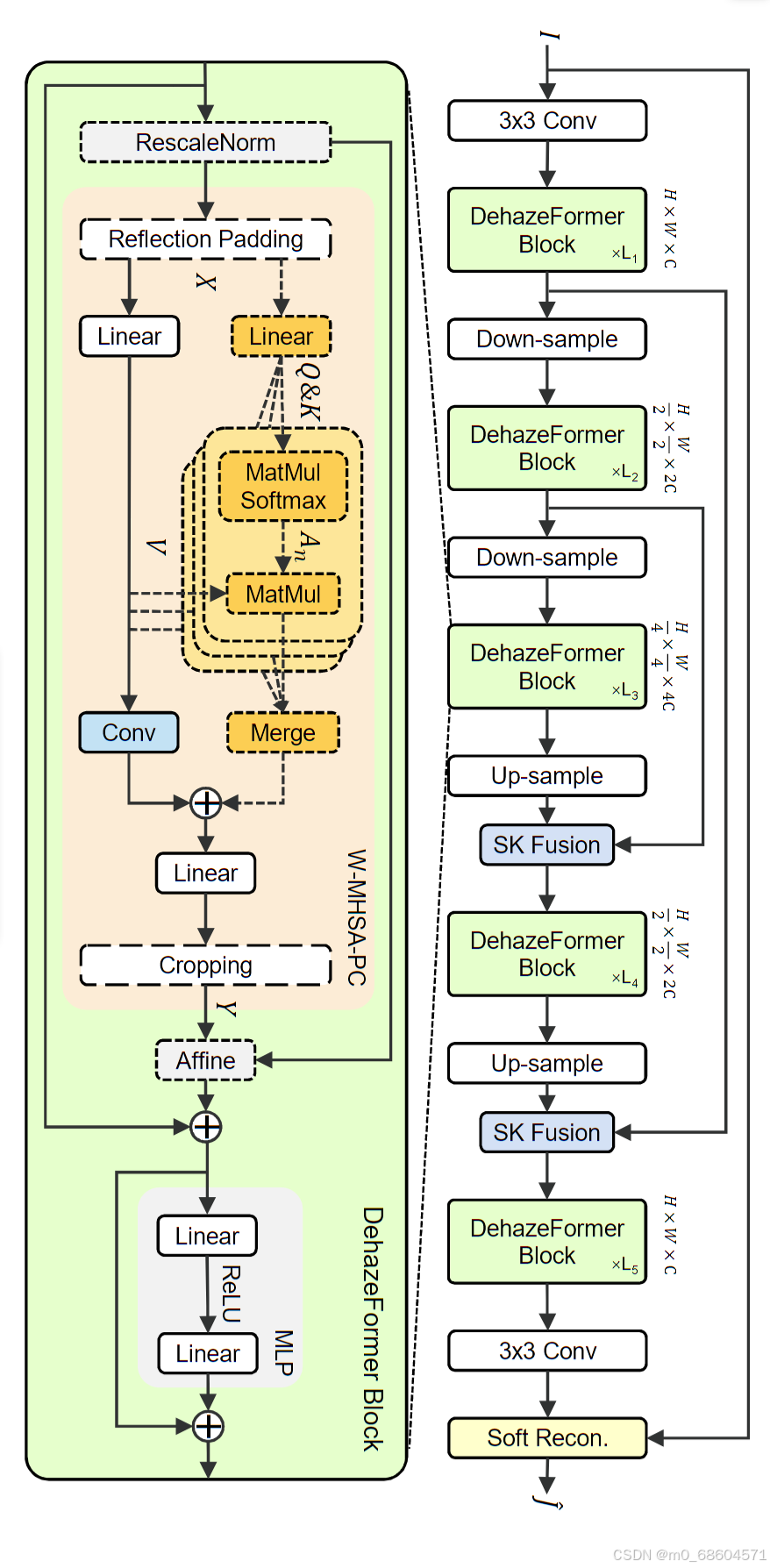
具体来说,DehazeFormer 在以下几个方面进行了改进:
-
层归一化:传统的层归一化在图像去雾任务中可能会导致边缘像素的信息丢失,因此本文引入了 Rescale Layer Normalization,该方法可以在保留全局信息的同时,将局部区域的信息也纳入考虑。

-
非线性激活函数:本文提出了 SoftReLU 激活函数,该函数是一种平滑的 ReLU 替代方案,可以更好地适应图像去雾任务的需求。
-
窗口划分与卷积操作:为了避免窗口划分带来的边缘效应,本文采用了 reflection padding 和 crop 操作,并使用额外的卷积操作来提取高频率信息。
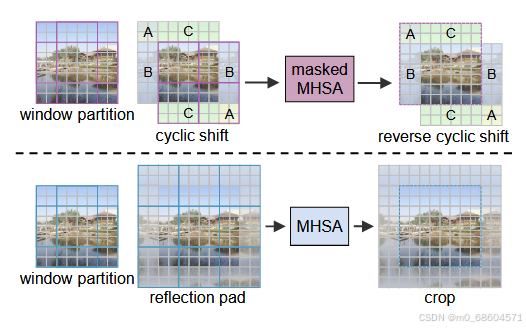
-
模型结构设计:本文提出了 W-MHSA(Weighted Multi-Head Self Attention)模块,该模块结合了注意力机制和卷积操作,能够更好地处理不同位置之间的依赖关系。
-
软重建层:提出了一个软重建公式,允许网络预测输出图像或全局残差,并且可以在没有强约束的情况下引入先验知识,从而灵活调整K(x)K(x)与B(x)B(x)之间的关系。
2.2 方法改进
通过上述改进,DehazeFormer 可以更有效地处理图像去雾任务中的挑战,包括非均匀性、光照变化等。同时,DehazeFormer 还具有较强的泛化能力,能够在多种数据集上取得优异的表现。
2.3 解决的问题
DehazeFormer 主要解决了图像去雾任务中存在的两个问题:
-
非均匀性:由于雾霾的不均匀分布,图像去雾任务需要考虑到不同区域的差异性,而传统的卷积神经网络可能无法很好地捕捉这些细节。
-
光照变化:由于光线的反射和折射,雾霾天气下的光照条件会发生变化,因此图像去雾任务需要考虑到这种变化,而传统的图像去雾方法往往只能处理相对稳定的光照条件。
3. 论文实验
本文主要介绍了针对图像去雾问题的深度学习方法——DehazeFormer,并进行了多组实验来验证其性能和效果。DehazeFormer提供了几种不同大小的变体,从微型(Tiny)到大型(Large),每个变体都有其独特的参数配置和计算复杂度,以适应不同的应用场景和资源限制。模型分为以下几种:
- Tiny (T):最小版本,具有较少的参数和较低的计算成本。
- Small (S):小型版本,在保持较小体积的同时提供较好的性能。
- Basic (B):基础版本,作为标准参考点。
- Middle (M):中型版本,提供了更好的性能但需要更多的资源。
- Large (L):大型版本,拥有最多的参数和最高的计算需求,适用于高性能要求的任务。
具体来说,本文采用了以下几种对比实验:
-
实验内容分为三部分:(1)使用RESIDE和RS-Haze数据集对DehazeFormer和其他基准模型进行定量比较;(2)在RS-Haze数据集上对不同版本的DehazeFormer进行定性比较;(3)对DehazeFormer的不同组件进行Ablation Study,包括归一化层、移位窗口分割方案、非线性激活函数等。
-
在定量比较中,作者使用PSNR和SSIM作为评估指标,并将结果列于表格IV中。结果显示,DehazeFormer在所有实验中均优于其他基准模型,特别是在RESIDE-Full室内场景下,DehazeFormer-L的PSNR超过了40dB,是目前最好的方法之一。
-
在定性比较中,作者选择了四个样本从不同的场景中来评估网络的去雾性能,包括合成室内和室外雾霾。结果表明,DehazeFormer能够恢复清晰的图像,保留纹理和颜色信息,并且在高密度雾霾区域也具有良好的去雾效果。
-
在Ablation Study中,作者对DehazeFormer的不同组件进行了分析和比较。结果表明,归一化层、移位窗口分割方案和非线性激活函数等组件都对网络性能有重要影响。例如,使用DWConv并将其放置在Transformer块之前可以显著提高网络性能,而SK融合模块和软重构模块也可以带来一定的性能提升。
综上所述,本文通过多组实验验证了DehazeFormer的性能和效果,并对其不同组件的作用进行了深入分析。这些实验结果对于进一步改进图像去雾算法具有重要意义。
4. 论文总结
4.1 文章优点
本文提出了一种基于Transformer架构的图像去雾网络DehazeFormer,并在多个数据集上取得了优异的表现。该文的方法创新点主要体现在以下几个方面:
- 使用RescaleNorm和ReLU代替常用的LayerNorm和GELU,以避免一些不重要的影响因素对高阶视觉任务的影响。
- 提出了一种基于反射填充和卷积的窗口划分方案,以提高MHSA的能力。
- 提出了一个基于SKNet的多尺度特征融合模块来替代串联式融合,并提出了一个软重构模块来改进全局残差学习的效果。
4.2 方法创新点:
DehazeFormer的主要创新点在于其提出的窗口划分方案和多尺度特征融合模块。传统的Transformer模型使用固定大小的窗口进行自注意力计算,但这种方法对于边缘区域的处理效果不佳。因此,本文提出了一种基于反射填充和卷积的窗口划分方案,使得MHSA可以有效地聚合局部信息,同时保持窗口大小不变。此外,本文还引入了一个基于SKNet的多尺度特征融合模块,以替代传统的串联式融合方式,从而更好地捕捉不同尺度的特征信息。
5.结尾
虽然DehazeFormer已经在多个数据集上取得了很好的表现,但是仍然存在一些问题需要解决。例如,在非均匀雾霾场景下的性能可能不如预期。因此,未来的研究方向包括如何进一步优化网络结构以适应不同的雾霾场景,并探索更加高效的训练策略以提高网络的泛化能力。此外,还可以考虑将DehazeFormer应用于其他低级视觉任务中,如图像超分辨率等。
通过对这篇论文的详细解读,我们可以看到作者在图像去雾方面的创新和贡献。论文中提出的DehazeFormer不仅为当前的研究提供了新的视角,还为未来的工作提供了有力的支持。通过对该技术实现的GitHub代码进行探索,我们可以更加深入地理解作者的思路,并为自己的项目提供启发。
如果您对这篇论文感兴趣,欢迎访问作者的GitHub地址,获取更多的代码和技术细节。此外,论文中提到的相关方法也为我们今后的研究提供了可参考的框架,期待能够与大家共同探讨这一领域的发展。
希望本文的解读对您有所帮助,欢迎在评论区交流想法。
来源:@article{song2023vision,
title={Vision Transformers for Single Image Dehazing},
author={Song, Yuda and He, Zhuqing and Qian, Hui and Du, Xin},
journal={IEEE Transactions on Image Processing},
year={2023},
volume={32},
pages={1927-1941}
}
文章地址:
2204.03883![]() https://arxiv.org/pdf/2204.03883
https://arxiv.org/pdf/2204.03883
代码开源地址:

















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









