






prompt-based few- shot learner, SFLM,通过弱增强和强增强技术给出文本样本的两个视图,SFLM会在弱增强版上生成一个伪标签后,在强增强版进行了微调的时候模型预测相同的伪标签。
未标记的数据也包含丰富的下游任务信息,比标记的数据更容易获得,在本文中,主要研究了在少量有标记和无标记数据的情况下,语言模型的few-shot learning,半监督学习得益于部分标记的数据集。通用的半监督学习是一种自我训练,它利用标记数据提供的监督信号为未标记数据创建伪标签,这些伪标签可以作为完善模型的额外监督
1. Problem setup
我们的目标是使PLMs在few-shot setting下适应到下游任务。模型m应该利用来自每个类别的极少标记数据去正确分类未见过的样例。
令x表示少量带标签的训练集,每类包含 N 个样本,令u表示和x相同任务域的无标签数据集。令无标签数据的数量为有限的大小UN,其中U为是无标签数据和带标签数据之间的比值。
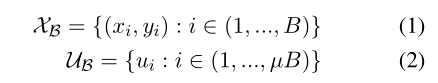
图中展示了这一过程,举例包含一个带标签数据和三个无标签数据。SFLM 通过以下损失函数优化:

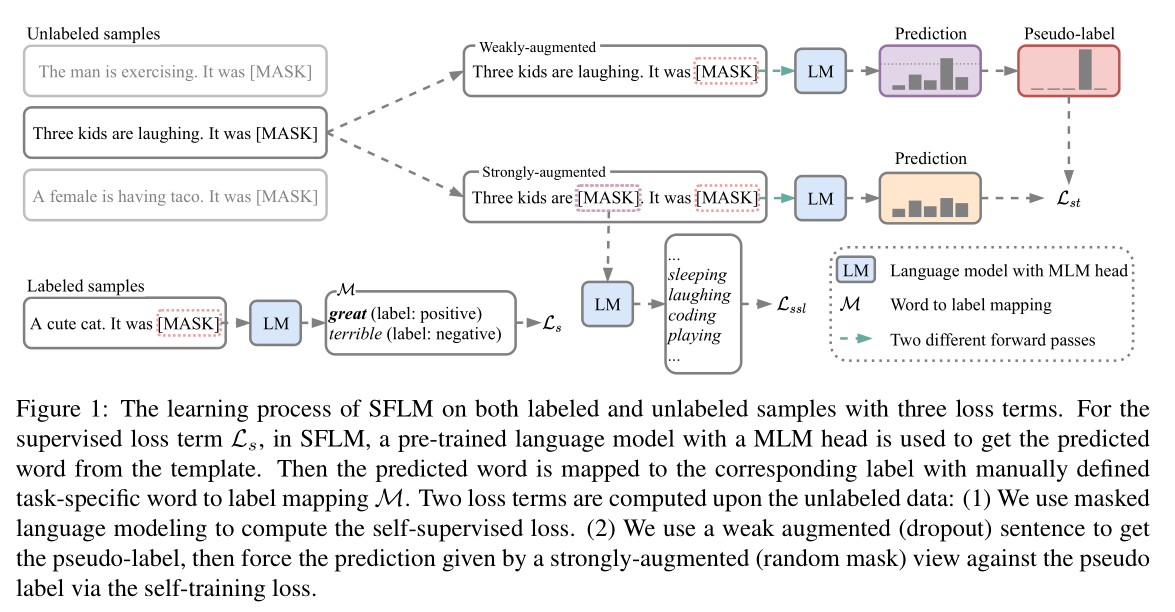
第一个labeled data监督损失,prompt template,第二个以及第三个loss基于unlabeled data,(1)利用MLM计算自监督损失(2)利用弱增强生成伪标签,然后通过自训练损失来强制强增强(随机掩码)对伪标签进行预测。
1. Prompt-based supervised loss
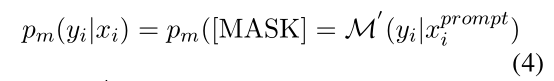
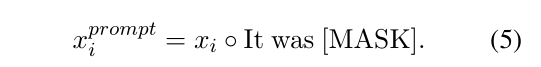
FT model
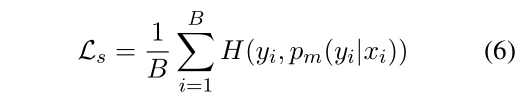
2. Self-training loss
对于每个未标记的句子ui,我们得到了弱增强α(ui)和强增强A(ui)。首先,我们为每个batch中的无标签句子根据弱增强版本的类别预测概率打上伪标签
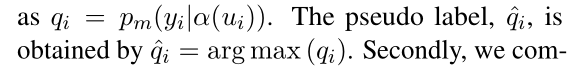
然后,我们为强增强版本的预测预测结构和伪标签 计算基于prompt的交叉熵损失
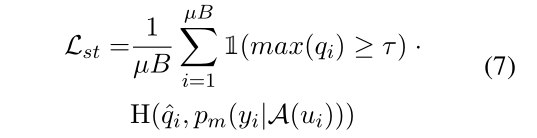
其中τ定义了阈值,超过该阈值,我们保留一个伪标签
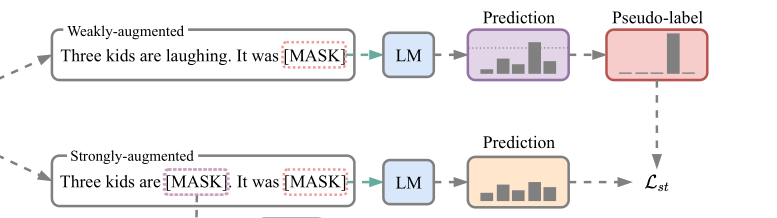
与图像不同,由于文本数据的离散型,文本增强技术可能很棘手。受到近期表征学习的一些启发,作者使用dropout进行弱增强,并使用随机 token mask作为强增强手段。对于弱增强,句子的表面形式保存未变,α(ui) =ui.对于强增强,用 [MASK] 随机替换掉句子中15%的token,然后分别将两个增强的句子输入到语言模型中。
3. Self-supervised loss
引入辅助自监督损失Lss;使用掩码语言模型损失是因为它的简单性和效率















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









