







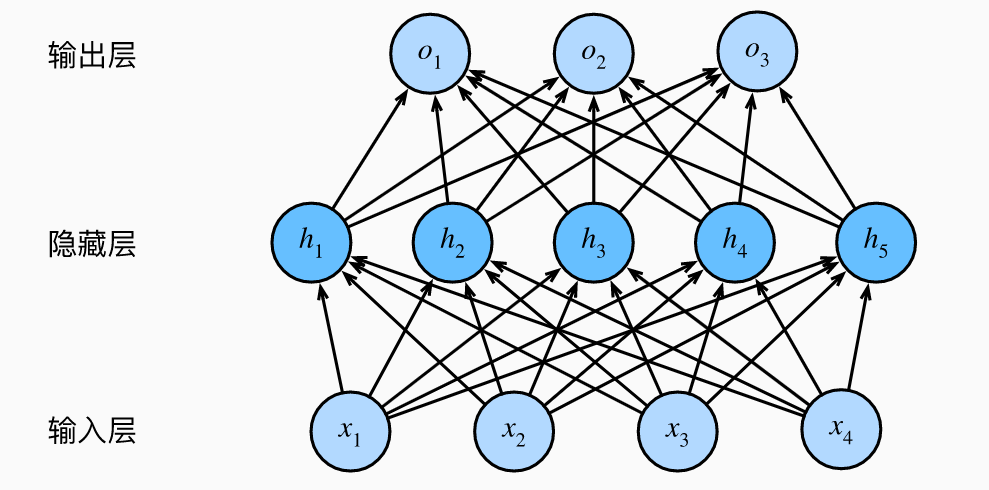
一、结构
(一)模型
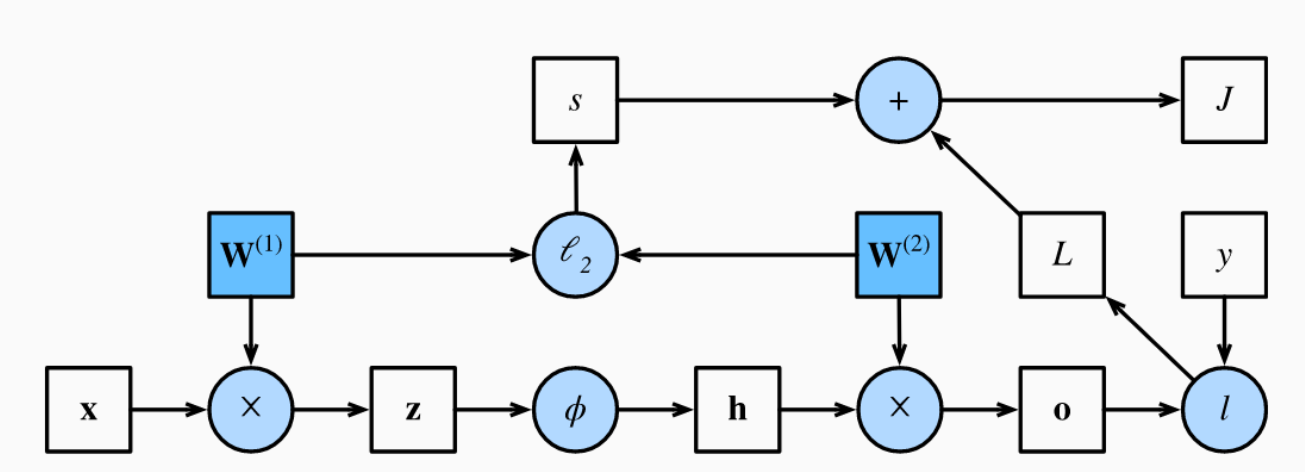
H = σ ( X W ( 1 ) + b ( 1 ) ) , O = H W ( 2 ) + b ( 2 ) . \begin{aligned} \mathbf{H} & = \sigma(\mathbf{X} \mathbf{W}^{(1)} + \mathbf{b}^{(1)}), \\ \mathbf{O} & = \mathbf{H}\mathbf{W}^{(2)} + \mathbf{b}^{(2)}.\\ \end{aligned} HO=σ(XW(1)+b(1)),=HW(2)+b(2).
(二)前向传播过程
我们将一步步研究单隐藏层神经网络的机制,为了简单起见,我们假设输入样本是 x ∈ R d \mathbf{x}\in \mathbb{R}^d x∈Rd。这里的中间变量是:
z = W ( 1 ) x + b , \mathbf{z}= \mathbf{W}^{(1)} \mathbf{x}+{b}, z=W(1)x+b,
其中 W ( 1 ) ∈ R h × d \mathbf{W}^{(1)} \in \mathbb{R}^{h \times d} W(1)∈Rh×d是隐藏层的权重参数, b {b} b是隐藏层神经单元的偏置项。将中间变量 z ∈ R h \mathbf{z}\in \mathbb{R}^h z∈Rh通过激活函数 ϕ \phi ϕ后,我们得到长度为 h h h的隐藏激活向量:
h = ϕ ( z ) . \mathbf{h}= \phi (\mathbf{z}). h=ϕ(z).
隐藏变量 h \mathbf{h} h也是一个中间变量。假设输出层的权重为 W ( 2 ) ∈ R q × h \mathbf{W}^{(2)} \in \mathbb{R}^{q \times h} W(2)∈Rq×h,我们可以得到输出层变量,它是一个长度为 q q q的向量:
o = W ( 2 ) h + b . \mathbf{o}= \mathbf{W}^{(2)} \mathbf{h}+{b}. o=W(2)h+b.
假设损失函数为 l l l,样本标签为 y y y,我们可以计算单个数据样本的损失项,
L = l ( o , y ) . L = l(\mathbf{o}, y). L=l(o,y).
根据 L 2 L_2 L2正则化的定义,给定超参数 λ \lambda λ,正则化项为
s = λ 2 ( ∥ W ( 1 ) ∥ F 2 + ∥ W ( 2 ) ∥ F 2 ) . s = \frac{\lambda}{2} \left(\|\mathbf{W}^{(1)}\|_F^2 + \|\mathbf{W}^{(2)}\|_F^2\right). s=2λ(∥W(1)∥F2+∥W(2)∥F2).
最后,模型在给定数据样本上的正则化损失为:
J = L + s . J = L + s. J=L+s.
在下面的讨论中,我们将
J
J
J称为目标函数(objective function)。
计算图如下
二、实现
(一)读取数据集
import paddle
from paddle import nn
from paddle.fluid.layers.nn import shape
from paddle.vision import transforms
from paddle import vision
from paddle.io import TensorDataset, DataLoader
import matplotlib.pylab as plt
def load_data_fashion_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = vision.datasets.FashionMNIST(mode='train', transform=trans, download=True)
mnist_test = vision.datasets.FashionMNIST(mode='test', transform=trans, download=True)
return (DataLoader(mnist_train, batch_size=batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
DataLoader(mnist_test, batch_size=batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
def get_dataloader_workers():
return 4
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
(二)建立模型
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1)## 这里“@”代表矩阵乘法
return (H@W2 + b2)
(三)损失函数
loss = nn.CrossEntropyLoss()
(四)优化算法
trainer = paddle.optimizer.SGD(parameters=params, learning_rate=0.1)
(五)训练
'''————————————————————————————————————————————————————————————————————————————————————————————————'''
'''精确度'''
def accuracy(y_hat, y):
y = y.reshape(shape=[y.shape[0]])
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat == y
return float(cmp.sum())
'''————————————————————————————————————————————————————————————————————————————————————————————————'''
'''累加器'''
class Accumulator:
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
'''————————————————————————————————————————————————————————————————————————————————————————————————'''
'''评估精度'''
def evaluate_accuracy(net, data_iter):
if isinstance(net, paddle.nn.Layer):
net.eval()
metric = Accumulator(2)
with paddle.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
'''————————————————————————————————————————————————————————————————————————————————————————————————'''
'''训练'''
def train_epoch_ch3(net, train_iter, loss, updater):
if isinstance(net, paddle.nn.Layer):
net.train()
metric = Accumulator(3)
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, paddle.optimizer.Optimizer):
updater.clear_grad()
l.backward()
updater.step()
else:
l.backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
'''————————————————————————————————————————————————————————————————————————————————————————————————'''
'''训练过程+精度'''
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
print("train: ", train_metrics)
test_acc = evaluate_accuracy(net, test_iter)
print("test: ", test_acc)
train_loss, train_acc = train_metrics
num_epochs, lr = 5, 0.03
updater = paddle.optimizer.SGD(parameters=params, learning_rate=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
(六)预测
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
def predict(net, test_iter, n=10):
for X, y in test_iter:
break
trues = get_fashion_mnist_labels(y)
preds = get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict(net, test_iter)















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









