







原文链接:https://arxiv.org/abs/2111.12448
全文摘要
这篇论文探讨了如何在三维形状生成模型中学习可解释、结构化的潜在表示,并解决控制身份特征的问题。作者提出了一个直观而有效的方法,通过交换不同形状之间的任意特征来训练一个能够鼓励分离身份特征的三维形状变分自编码器(VAE)。实验结果表明,目前最先进的方法无法有效地分离人脸和身体的身份特征,而该方法能够在保持良好的表征和重构能力的同时正确地解耦这些特征的生成。
论文方法
方法描述
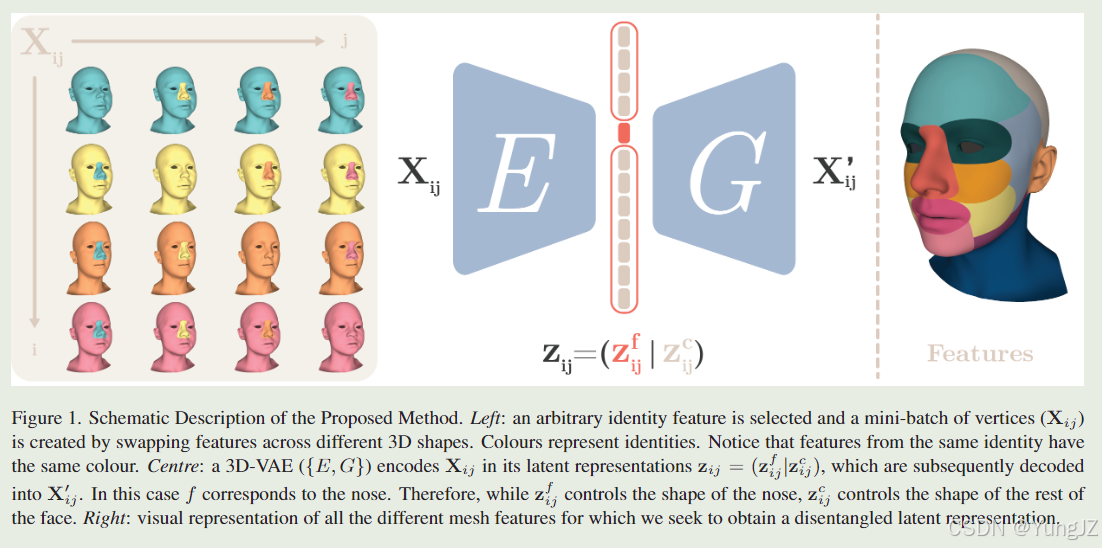
该论文提出了一种用于自监督三维生成模型的可解释性和结构化的潜在表示学习方法。这种方法通过训练一个基于网格卷积的变分自编码器来实现。该编码器解码器配对被设计为生成模型,并且被称为生成器。在编码器中,每个螺旋卷积层后面都跟着一个ELU激活函数。而在解码器中,则是使用了反卷积层。此外,还有三个全连接层:其中两个是编码器的最后两层,用于预测变分分布的均值和方差;另一个则是解码器的第一层,将潜在变量转换成低维网格以便于进行网格卷积操作。
方法改进
该方法的主要改进在于引入了一个特征交换和潜在一致性损失的机制。通过定义任意数量的特征模板,可以将不同的特征从一个网格转移到另一个网格。这个过程可以通过在线交换特征来完成,从而形成一个大小为√B×√B的矩阵。在这个矩阵中,每行代表同一张图像的不同特征,而每列则代表不同图像中的相同特征。同时,该方法还引入了潜在一致性损失,以确保不同特征之间的相似性和差异性得到保留。
解决的问题
该方法解决了自监督三维生成模型中难以获得可解释性和结构化潜在表示的问题。通过引入特征交换和潜在一致性损失,该方法能够控制特定特征与预定义的一组潜在变量之间的关系,从而使生成的模型更加可控和灵活。
论文实验
本文主要介绍了作者在三维人脸和身体数据集上使用自编码器来实现特征解码的方法,并与其他几种方法进行了比较。具体来说,作者首先从两个线性模型中随机生成了1万个三角形网格,然后将这些数据分为训练集、验证集和测试集。接着,作者实现了四个网络(两个用于人脸,两个用于身体),并使用ADAM优化器对它们进行了训练。最后,作者使用多个评估指标来比较不同方法的性能,并得出了一些结论。
在实验中,作者首先使用重构误差、多样性、Jensen-Shannon距离、覆盖率、最小匹配距离和1-最近邻准确率等指标来评估不同的模型在生成样本方面的表现。结果表明,与大多数其他方法相比,作者的方法在保持较低的重构误差的同时,也能够生成更多样化的数据。此外,作者还使用了一些其他的指标来评估模型的生成能力,例如Chamfer距离和Earth Mover距离。结果显示,作者的方法在这方面的表现也很不错。
接下来,作者使用了一些方法来评估不同方法中的潜在变量是否被正确地分离出来。由于作者的数据集中没有标签信息,因此无法使用传统的Z-Diff、SAP和Factor等指标来评估潜在变量的分离情况。相反,作者提出了一种新的方法,即通过生成两个与每个潜在变量相对应的形状,并计算它们之间的欧几里得距离来评估潜在变量的影响。结果显示,与大多数其他方法相比,作者的方法可以更好地分离出潜在变量,并且更易于解释。
最后,作者还展示了如何直接操纵生成的三维网格。用户可以选择一个或多个顶点,并指定它们的新位置,然后作者的方法会自动生成一个新的局部变形的网格以满足用户的编辑需求。这可以通过对潜在表示进行小规模优化来实现。结果表明,这种方法非常有效,并且可以避免全局变化的问题。
总的来说,本文提出了一种新的方法来实现三维人脸和身体数据集上的特征解码,并对其性能进行了全面的评估。该方法不仅可以生成多样化的数据,而且还可以更好地分离出潜在变量,并支持直接操纵生成的三维网格。
论文总结
文章优点
- 该研究提出了一种新的方法来学习更分离、可解释和结构化的潜在表示,以提高3D变分自编码器(VAE)的性能。
- 研究人员通过使用特征交换的小批量处理和引入额外的潜在一致性损失来实现这一目标。
- 研究人员还探讨了这种方法在其他领域的应用潜力,并提出了未来的研究方向。
方法创新点
- 该研究提出的新的小批量处理方法可以更好地捕捉输入数据中的形状差异和相似性,从而鼓励更分离、可解释和结构化的潜在表示的学习。
- 研究人员还引入了一个新颖的损失函数,可以利用形状差异和相似性来增强潜在表示的质量。
- 研究人员还探讨了如何将这种技术应用于其他领域的问题,如点云或体素数据的生成模型。
未来展望
- 该研究为3D形状生成提供了新的思路和技术,但仍然存在一些限制和挑战,例如如何确保每个子集内的变量之间具有正交性和分离性等。
- 未来的研究可以进一步探索如何扩展这种方法到其他领域,以及如何改进其性能和鲁棒性。
- 另外,研究人员还可以考虑如何结合其他技术,如注意力机制或条件生成模型,以进一步提高3D形状生成的质量和多样性。
原文翻译
摘要
在面部和身体的三维生成模型中学习解耦、可解释且结构化的潜在表示仍然是一个开放的问题。当需要控制身份特征时,这个问题尤为严重。在这篇论文中,我们提出了一种直观而有效的自监督方法来训练一个三维形状变分自动编码器(VAE),该方法鼓励身份特征的解耦潜在表示。通过交换不同形状之间的任意特征来管理迷你批处理生成,可以定义利用已知差异和相似性的损失函数。实验结果表明,在三维网格上,最先进的潜在解耦方法无法解耦面部和身体的身份特征。我们的方法正确地解耦了这些特征的生成,同时保持良好的表示和重建能力。我们的代码和预训练模型可以在github.com/simofoti/3DVAE-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









