






 本文介绍了残差神经网络(ResNet)的发展背景、关键结构特点,如直连边和残差块,以及如何通过BatchNormalization和残差学习解决深度网络的退化问题和梯度消失/爆炸。重点阐述了ResNet的超深网络结构和如何通过ReLU激活、权重初始化等方法优化训练过程。
本文介绍了残差神经网络(ResNet)的发展背景、关键结构特点,如直连边和残差块,以及如何通过BatchNormalization和残差学习解决深度网络的退化问题和梯度消失/爆炸。重点阐述了ResNet的超深网络结构和如何通过ReLU激活、权重初始化等方法优化训练过程。
目录
一、开发背景
残差神经网络(ResNet)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的, 斩获2015年ImageNet竞赛中分类任务第一名, 目标检测第一名。 残差神经网络的主要贡献是发现了“退化现象(Degradation)”,并针对退化现象发明了 “直连边/短连接(Shortcut connection)”,极大的消除了深度过大的神经网络训练困难问题。神经网络的“深度”首次突破了100层、最大的神经网络甚至超过了1000层。
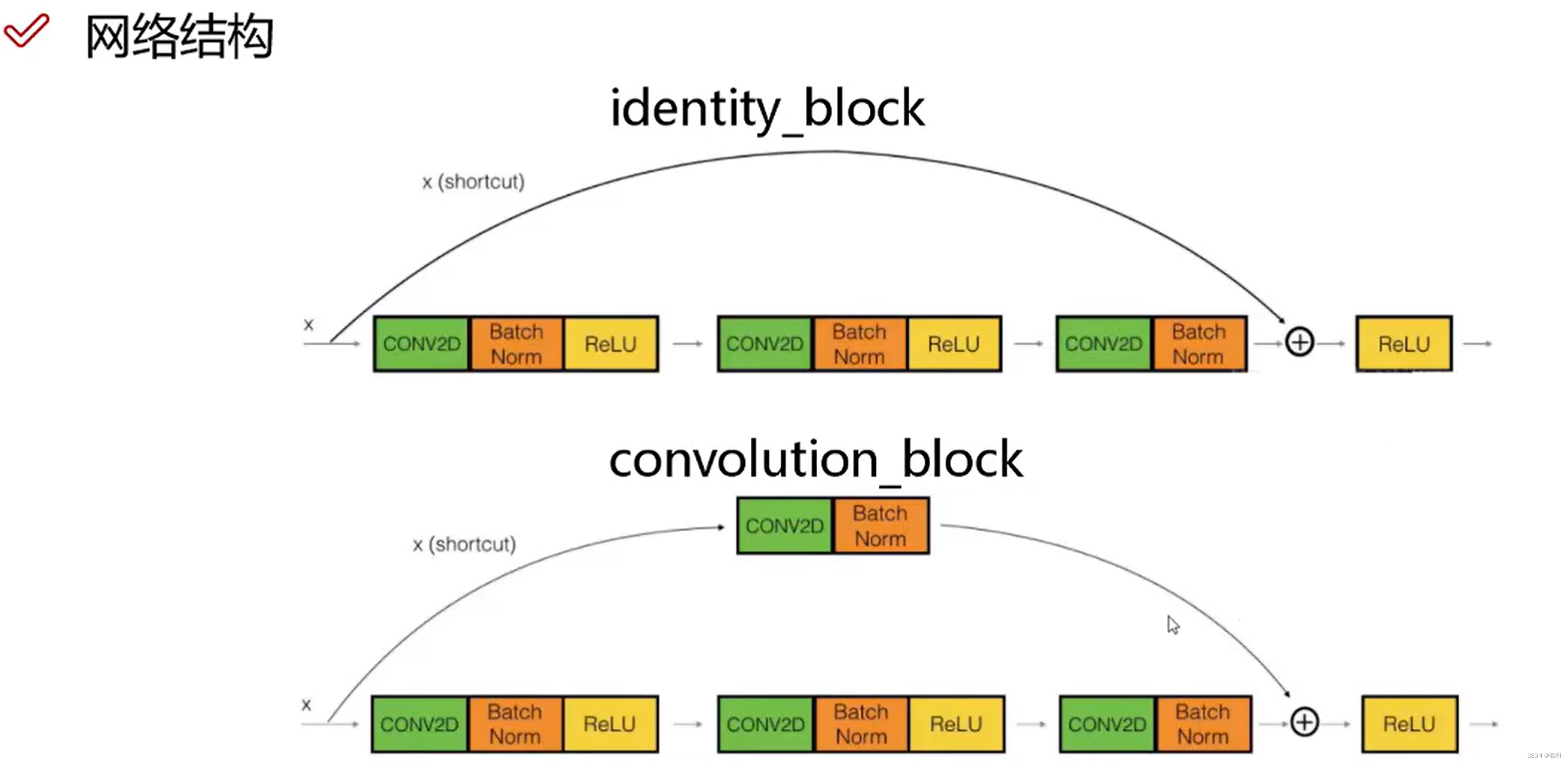
二、网络结构
残差单元(残差块)
ResNet团队分别构建了带有“直连边(Shortcut Connection)”的ResNet残差块、以及降采样ResNet残差块。
区别是降采样残差块的直连边增加了一个1×1的卷积操作。对于直连边,当输入和输出维度一致时,可以直接将输入加到输出上,这相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。
但是当维度不一致时,这就不能直接相加,通过添加1×1卷积调整通道数。这种残差学习结构可以通过前向神经网络+直连边实现, 而且整个网络依旧可以通过端到端的反向传播训练。结构如下图所示:
三、模型特点
1.超深的网络结构(突破1000层)
网络深度为什么重要?因为CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。
2.使用Batch Normalization
为什么不能简单地增加网络层数?对于原来的网络,如果简单地增加深度,会导致梯度弥散或梯度爆炸。Batch Normalization可以解决该问题的,因此可以训练到几十层的网络。
3.残差块
随着网络层数增加,出现了新的问题:退化问题,在训练集上准确率饱和甚至下降了。这个不能解释为过拟合,因为过拟合表现为在训练集上表现更好才对。退化问题说明了深度网络不能很简单地被很好地优化。作者通过实验说明:通过浅层网络y=x 等同映射构造深层模型,结果深层模型并没有比浅层网络有更低甚至等同的错误率,推断退化问题可能是因为深层的网络很那难通过训练利用多层网络拟合同等函数。
怎么解决退化问题?深度残差网络。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。所以要解决的就是学习恒等映射函数。但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 此外,拟合残差会更加容易。
总的来说,一是其导数总比原导数加1,这样即使原导数很小时,也能传递下去,能解决梯度消失的问题; 二是y=f(x)+x式子中引入了恒等映射(当f(x)=0时,y=2),解决了深度增加时神经网络的退化问题。
4.结构简单
虽然ResNet的主体结构跟GoogLeNet类似,但ResNet结构更简单,修改也更方便,因此ResNet迅速被广泛使用。
四、梯度消失与梯度爆炸
梯度是一个多变量函数在某一点处沿着不同坐标轴方向的导数的向量。在数学和机器学习领域,梯度的概念非常重要,尤其是在优化问题和神经网络训练中。
在机器学习,特别是在神经网络的训练中,梯度用于指导权重的更新。通过计算损失函数关于网络参数(如权重和偏置)的梯度,可以使用优化算法(如梯度下降)来调整参数,以减少预测误差。
反向传播算法
在神经网络中,梯度是通过反向传播算法计算的。反向传播算法包括两个主要步骤:
- 正向传播:输入数据通过网络,每一层计算输出,直到最后一层产生预测结果。
- 反向传播:计算损失函数关于网络输出的导数,然后从最后一层开始,逐层反向传播这些导数,得到损失函数关于网络中每个权重的梯度。
梯度下降
梯度下降是一种优化算法,用于最小化损失函数。在每次迭代中,根据损失函数的梯度,沿着梯度的相反方向更新权重,数学表达式为:

通过逐步调整权重,梯度下降算法旨在找到损失函数的最小值,从而训练出一个性能良好的神经网络模型。
梯度消失和梯度爆炸是深度神经网络训练中的两个常见问题,它们都与网络中反向传播算法的梯度计算有关。
梯度消失
梯度消失通常发生在深度神经网络中,特别是当网络层数较多时。在反向传播过程中,梯度会通过多层网络进行传播。如果激活函数的导数很小(如sigmoid或tanh函数在输入值非常大或非常小的时候),那么在反向传播过程中,梯度会逐层减小,最终在网络的前几层变得非常小,接近于0。这会导致权重更新非常缓慢,甚至几乎不更新,从而使得网络难以学习。
梯度消失的原因主要有两个:
- 激活函数的选择:某些激活函数(如sigmoid或tanh)在输入值的极端情况下导数会变得非常小。
- 权重初始化不当:如果权重初始化过大,那么在反向传播时,梯度可能会被放大,导致后续层的梯度变得非常小。
梯度爆炸
梯度爆炸则是指在反向传播过程中,梯度的值变得非常大,以至于权重更新过大,这可能导致网络训练不稳定,甚至发散。梯度爆炸通常发生在以下情况:
- 梯度累积:在深度网络中,如果每层的权重矩阵非常大,那么在反向传播时,梯度会逐层累积,导致最终的梯度值变得非常大。
- 错误的权重初始化:如果权重初始化过大,那么在反向传播时,梯度可能会被放大,导致梯度爆炸。
- 学习率设置不当:如果学习率设置得过高,那么即使梯度本身不大,权重的更新也可能过大,导致梯度爆炸。
解决方法
对于梯度消失和梯度爆炸,有几种常见的解决方法:
- 使用ReLU激活函数:ReLU(Rectified Linear Unit)激活函数在正输入时导数为1,可以缓解梯度消失问题。
- 权重初始化:使用如He初始化或Xavier初始化等方法,可以更好地控制权重的初始值,减少梯度消失和爆炸的风险。
- 梯度裁剪:在反向传播时对梯度进行裁剪,确保梯度的值不会超过某个阈值,可以防止梯度爆炸。
- 使用残差连接:在网络中使用残差连接可以帮助梯度直接流向前面的层,缓解梯度消失问题。
- 调整学习率:适当调整学习率的大小,避免过大的学习率导致梯度爆炸。
通过这些方法,可以有效地解决或缓解梯度消失和梯度爆炸的问题,提高深度神经网络的训练效率和稳定性。
观察梯度消失于爆炸的方法;
1. 监控梯度值
在训练神经网络时,监控权重参数的梯度值是观察梯度消失或爆炸的直接方式。这可以通过在训练过程中打印梯度的值或使用可视化工具(如TensorBoard)来实现。
2. 使用调试工具
使用专门的调试工具,如PyTorch的torch.autograd或TensorFlow的tf.GradientTape,可以帮助你检查梯度的计算过程和值。
3. 检查损失曲线
梯度消失可能导致损失函数的值在训练过程中变化缓慢,而梯度爆炸可能导致损失函数的值迅速增加,甚至变成NaN(不是一个数字)或无穷大。
参考文章:















 4688
4688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









