




多头自注意力机制,是transformer最核心的部分。整体架构如下:
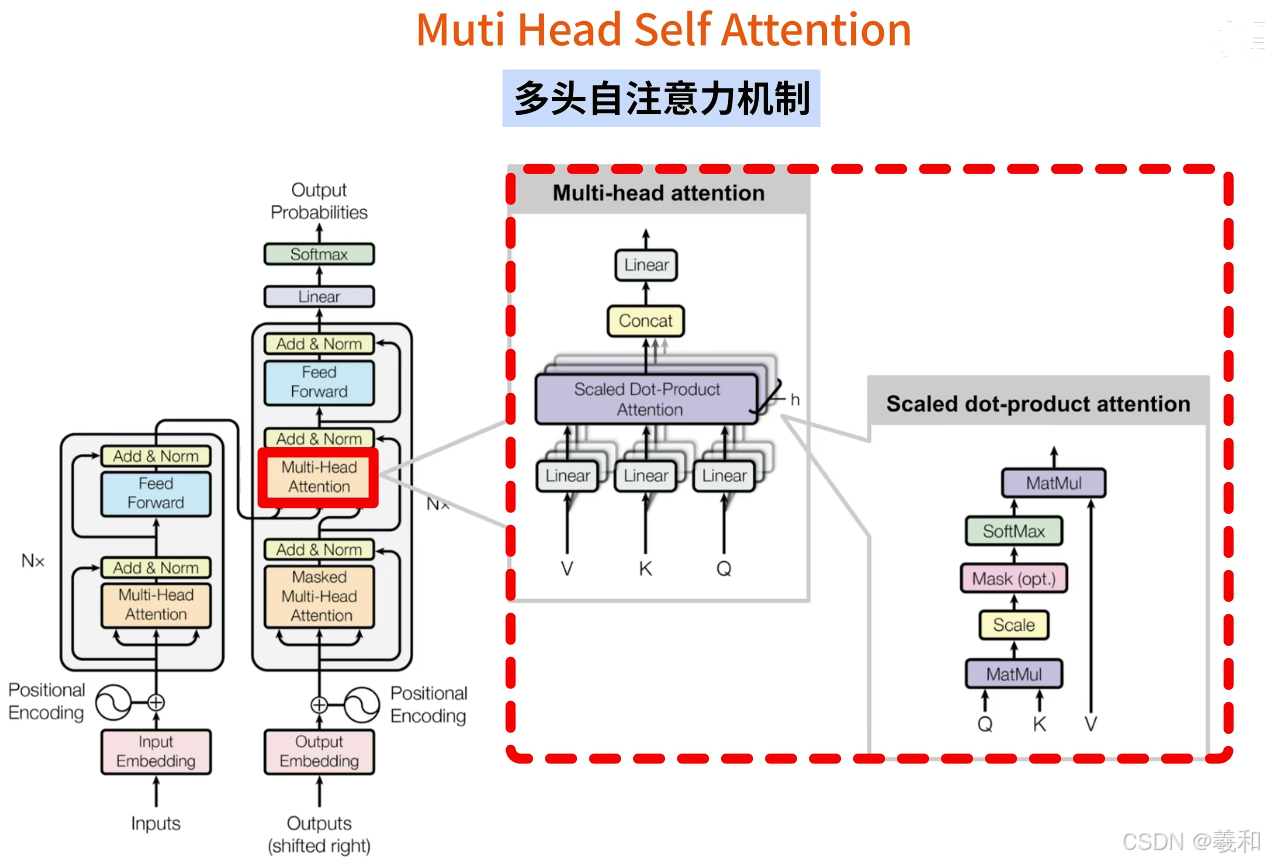
其中自注意力机制会分别使用QKV,三个线性层对输入数据进行特征变换,并使用scaled dot product attention的计算方法,将特征变化后的QKV进行结合。
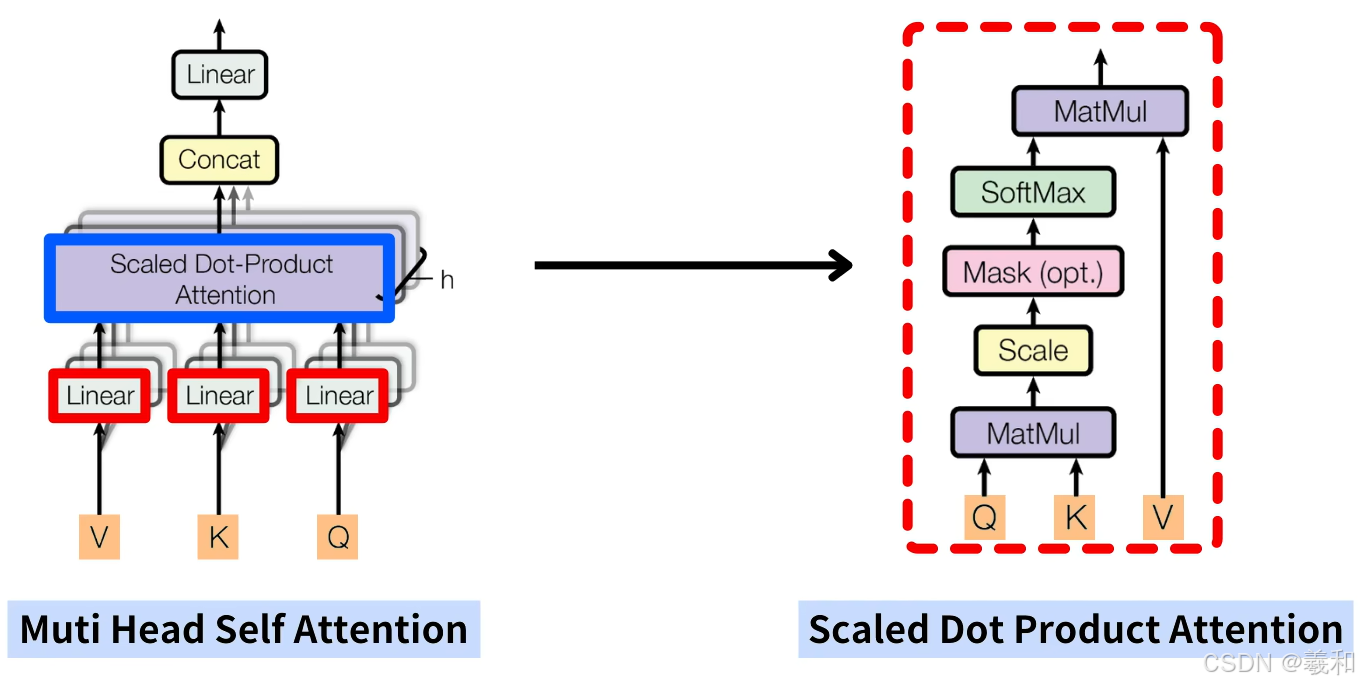
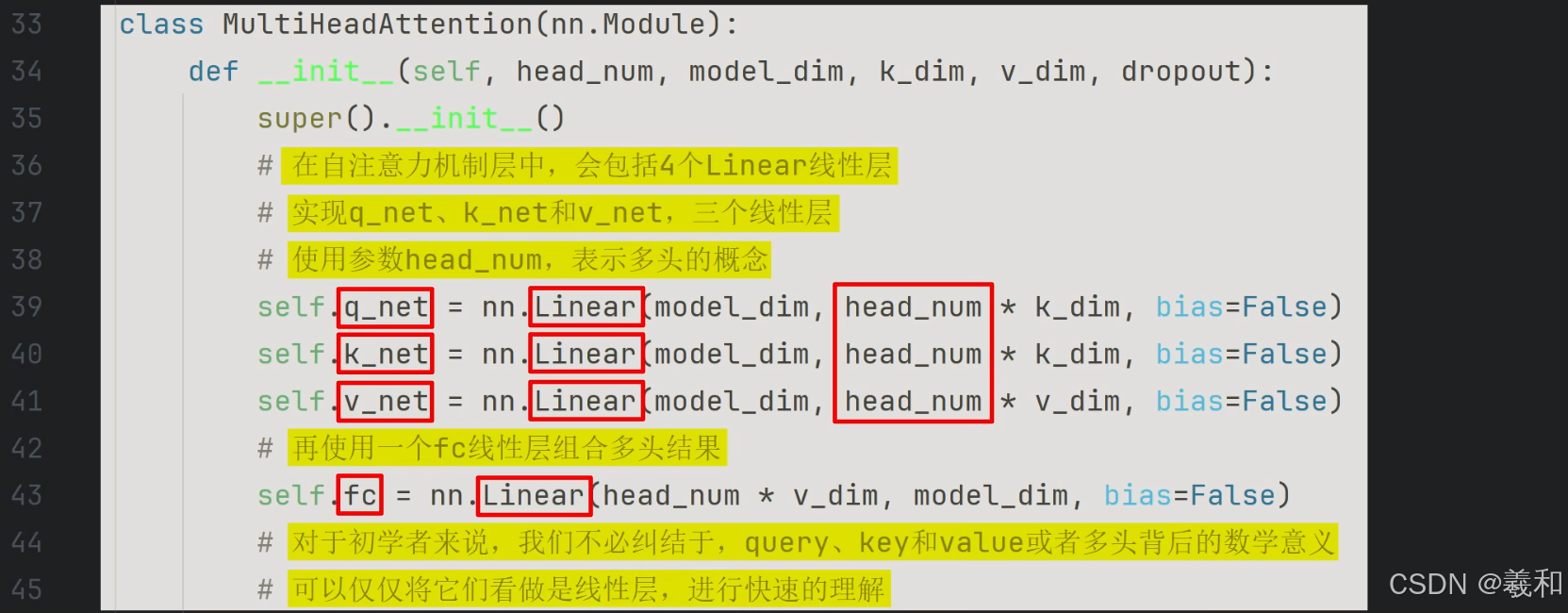
多头顾名思义就是同时通过多个自注意力机制进行特征提取,图不同深度的颜色就代表了多头,h表示了多头的数量,完成多头的计算后,再使用一个线性层,将多组自注意力机制的计算结果进行结合再输出。共包含四个线性层。
以编码器中的“自注意力机制层”说明自注意力机制的计算过程,首先输入的数据是经过位置编码后,Are you ok?用黄色的词向量矩阵XX会分别和三个线性层,q k 和v 做线性变换,得到三组结果。这个过程实际上并没有什么特别的,就是最基础的线性层计算。
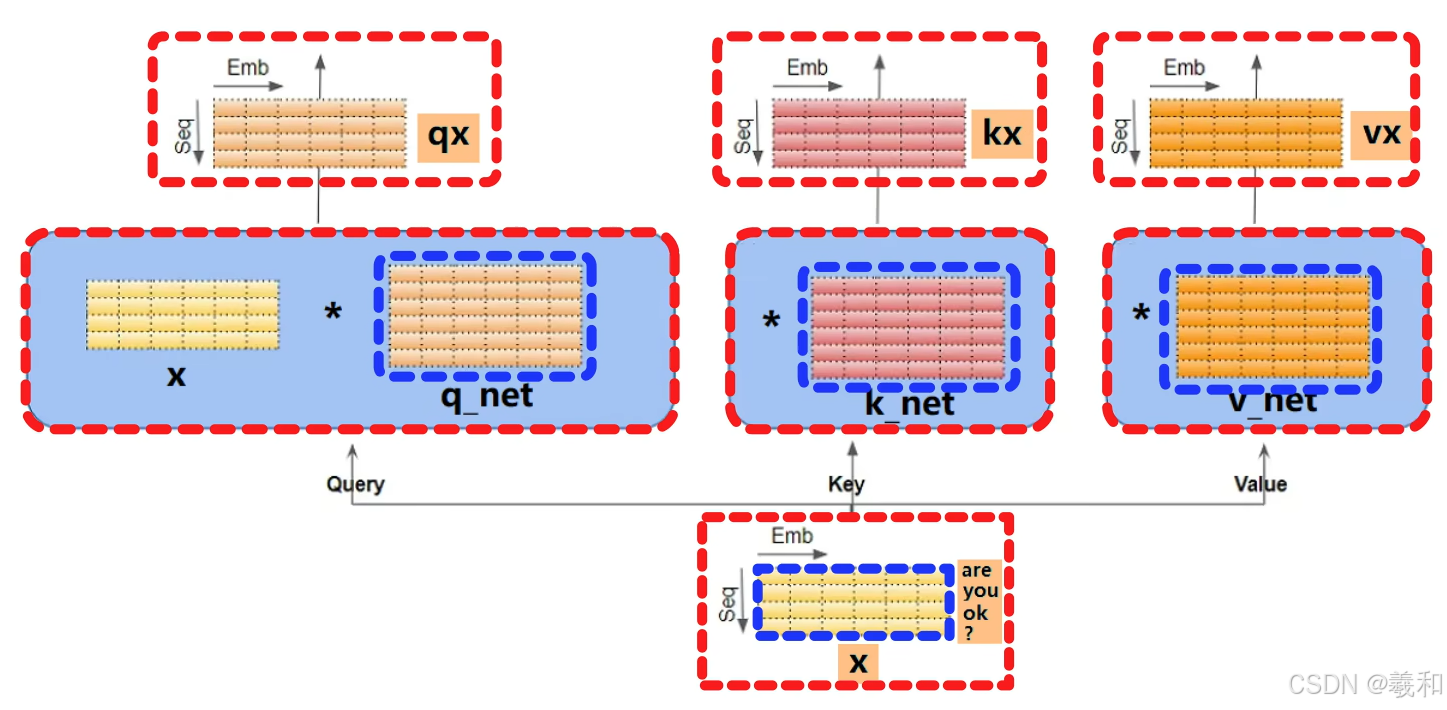
代入到QKV的计算公式中,计算注意力机制的输出,本质上对QKV3组信息进行选择和融合,得到一个最终的注意力结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









