







文章目录
- 所有现代操作系统都可以“同时”运行若干进程。
- 只有一个处理器的系统只能在给定时刻运行一个程序。
- 在多处理器系统中可以真正并行运行的进程数目取决于物理CPU的数目。
- 为什么内核和处理器可以给我们建立多任务的错觉,即可以并行运行多个程序?
- 短时间内系统运行的应用程序不停切换。切换时间间隔很短,短到用户无法察觉。
- 这种系统管理方式引起了几个问题,内核必须解决下面这些问题
- 除非明确地要求,否则应用程序不能彼此干扰。由于
Linux是一个多用户系统,它也必须确保程序不能读取或修改其他程序的内存,否则就很容易访问其他用户的私有数据。(可以使用存储保护实现,将在第3章进行处理) - CPU时间必须在各种应用程序之间尽可能公平地共享。
- 除非明确地要求,否则应用程序不能彼此干扰。由于
- 本章主要介绍内核共享CPU时间的方法,以及如何在进程之间切换。这里有两个任务,其执行是相对独立的。
- 内核必须决定为各个进程分配多长时间,何时切换到下一个进程。这又引出了哪个进程是下一个的问题。此类决策是平台无关的。
- 在内核从进程
A切换到进程B时,必须确保进程B的执行环境与上一次撤销其处理器资源时完全相同。例如,处理器寄存器的内容和虚拟地址空间的结构必须与此前相同。(这项工作与处理器极度相关。不能只用C语言实现,还需要汇编代码的帮助) - 上面两个任务是称之为调度器的内核子系统的职责。
CPU时间如何分配取决于调度器策略,这与用于在各个进程之间切换的任务切换机制完全无关。
1、进程优先级
-
进程可分为实时进程和非实时进程,而实时进程又可以分为硬实时进程和软实时进程。
- 硬实时进程:有严格的时间限制,某些任务必须在指定的时限内完成。
- 一个例子:飞控软件
- 注意,这并不意味着所要求的时间范围特别短,而是要保证在极端的情况下也决不会超过某一时间范围。
- Linux在主流的内核中不支持硬实时进程,而一些修改版本比如
RTLinux则支持。
- 软实时进程:是硬实时进程的一种弱化形式。尽管仍然需要快速得到结果,但稍微晚一点不会造成重大后果。
- 普通进程:大多数进程,没有特定时间约束。但仍然可以根据重要性来分配优先级。
- 硬实时进程:有严格的时间限制,某些任务必须在指定的时限内完成。
-
CPU时间分配简图
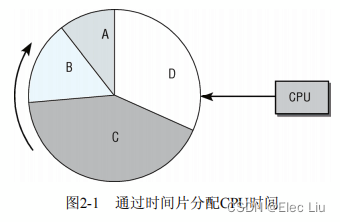
- 进程的运行按时间片调度,分配给进程的时间片份额与其相对重要性相当。
- 系统中时间的流动对应于圆盘的转动,CPU由圆周旁的“扫描器”表示。
- 这种方案称之为
抢占式多任务处理(preemptive multitasking),各个进程都分配到一定的时间段可以执行。时间段到期后,内核会从进程收回控制权,让一个不同的进程运行,而不考虑前一进程所执行的上一个任务。 - 被抢占进程的运行时环境,即所有CPU寄存器的内容和页表,都会保存起来,因此其执行结果不会丢失。在该进程恢复执行时,其进程环境可以完全恢复。时间片的长度会根据进程重要性(以及因此而分配的优先级)的不同而变化。
-
上图的CPU时间分配简图是不准确的,因为它没有考虑下面几个重要问题
- 进程在某些时间可能因为无事可做而无法立即执行,这样会导致CPU资源的巨大浪费,所以这样的进程应该避免。图中假定的所有进程都是可以立即运行的,显然不现实。
- Linux支持不同的调度类别(在进程之间完全公平的调度和实时调度),调度时也必须考虑到这一点。
- 此外,在有重要的进程变为就绪状态可以运行时,有一种选项是抢占当前的进程,图中也没有反映出这一点。
-
调度器代码的更新迭代
Linux2.5使用的是O(1)调度器。O(1)调度器一个特别的性质是,它可以在常数时间内完成其工作,不依赖于系统上运行的进程数目。Linux2.6.23使用的是完全公平调度器(CFS,completely fair scheduler),该调度器的关键特性是,它试图尽可能地模仿理想情况下的公平调度。此外,它不仅可以调度单个进程,还能够处理更一般性的调度实体(scheduling entity)。例如,该调度器分配可用时间时,可以首先在不同用户之间分配,接下来在各个用户的进程之间分配。
2、进程生命周期
- 进程可能有以下几种状态。
- 运行:该进程此刻正在执行。
- 等待:进程能够运行,但没有得到许可,因为CPU分配给另一个进程。调度器可以在下一次任务切换时选择该进程。
- 睡眠:进程正在睡眠无法运行,因为它在等待一个外部事件。调度器无法在下一次任务切换时选择该进程。
- 系统将所有进程保存在一个进程表中,无论其状态是运行、睡眠或等待。但睡眠进程会特别标记出来,调度器会知道它们无法立即运行(具体实现,请参考
3节)。睡眠进程会分类到若干队列中,因此它们可在适当的时间唤醒,例如在进程等待的外部事件已经发生时。 - 下图描述了进程的几种状态及其转换。

- 路径①:如果进程必须等待事件,则其状态
运行改变为睡眠。 - 路径②:在调度器决定从该进程收回CPU资源时(可能的原因稍后讲述),过程状态从
运行改变为等待, - 路径③:在所等待的事件发生后,处于
睡眠状态进程先变回到等待状态,然后重新回到正常循环。 - 路径④:在分配CPU时间之后,进程由
等待状态改变为运行 - 路径⑤:在程序执行终止(例如,用户关闭应用程序)后,过程状态由
运行变为终止
- 路径①:如果进程必须等待事件,则其状态
- 上文没有列出
僵尸状态,下面是关于僵尸状态的解释:- 什么是
僵尸状态?- 进程已经死亡,但仍然以某种方式活着。实际上,说这些进程死了,是因为其资源(内存、与外设的连接,等等)已经释放,因此它们无法也决不会再次运行。说它们仍然活着,是因为进程表中仍然有对应的表项。
僵尸状态产生的原因- 条件1:程序必须由另一个进程或一个用户杀死(通常是通过发送
SIGTERM或SIGKILL信号来完成,这等价于正常地终止进程); - 条件2:进程的父进程在子进程终止时必须调用或已经调用
wait4(读做wait for)系统调用。 这相当于向内核证实父进程已经确认子进程的终结。该系统调用使得内核可以释放为子进程保留的资源。 - 只有在条件1发生(程序终止)而条件2不成立的情况下(
wait4),才会出现“僵尸”状态
- 条件1:程序必须由另一个进程或一个用户杀死(通常是通过发送
僵尸进程残留带来的影响- 在进程终止之后,其数据尚未从进程表删除之前,进程总是暂时处于
僵尸状态。 - 有时候(例如,如果父进程编程极其糟糕,没有发出
wait调用),僵尸进程可能稳定地寄身于进程表中,直至下一次系统重启。 - 从进程工具(如
ps或top)的输出,可以看到僵尸进程。因为残余的数据在内核中占据的空间极少,所以这几乎不是问题。
- 在进程终止之后,其数据尚未从进程表删除之前,进程总是暂时处于
- 什么是
补充A:抢占式多任务处理
- Linux进程管理的结构还需要另外两种进程状态选项:用户状态和核心态,什么是用户状态和核心态?
- 进程通常都处于用户状态,只能访问自身的数据,无法干扰系统中的其他应用程序,甚至也不会注意到自身之外其他程序的存在。
- 如果进程想要访问系统数据或功能(后者管理着所有进程之间共享的资源,例如文件系统空间),则必须切换到核心态。
- 用户状态切换到核心态的方法有哪些?
- 第一种方法:系统调用。系统调用是由用户应用程序有意调用的。
- 第二种方法:中断。发生中断时,其发生或多或少是不可预测的,用户状态切换到核心态的过程是自动触发的。处理中断的操作,通常与中断发生时执行的进程无关。
- 内核的抢占调度模型建立了一个层次结构,用于判断哪些进程状态可以由其他状态抢占。
- 普通进程总是可能被抢占,甚至是由其他进程抢占。在一个重要进程变为可运行时,例如编辑器接收到了等待已久的键盘输入,调度器可以决定是否立即执行该进程,即使当前进程仍然在正常运行。对于实现良好的交互行为和低系统延迟,这种抢占起到了重要作用。
- 如果系统处于核心态并正在处理系统调用,那么系统中的其他进程是无法夺取其CPU时间的。调度器必须等到系统调用执行结束,才能选择另一个进程执行,但中断可以中止系统调用(在进行重要的内核操作时,可以停用几乎所有的中断)。
- 中断可以暂停处于用户状态和核心态的进程。中断具有最高优先级,因为在中断触发后需要
尽快处理。
- Linux内核支持
内核抢占(kernel preemption)选项。该选项支持在紧急情况下切换到另一个进程,甚至当前是处于核心态执行系统调用(中断处理期间是不行的)。
3、进程表示
Linux内核涉及进程和程序的所有算法都围绕一个名为task_struct的数据结构建立,该结构定义在include/sched.h中。task_struct包含很多成员,将进程与各个内核子系统联系起来,下面是task_struct的定义(简化版本):
<sched.h>struct task_struct { volatile long state; /* -1表示不可运行,0表示可运行,>0表示停止 */ void *stack; atomic_t usage; unsigned long flags; /* 每进程标志,下文定义 */ unsigned long ptrace; int lock_depth; /* 大内核锁深度 */ int prio, static_prio, normal_prio; struct list_head run_list; const struct sched_class *sched_class; struct sched_entity se; unsigned short ioprio; unsigned long policy; cpumask_t cpus_allowed; unsigned int time_slice; #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT) struct sched_info sched_info; #endif struct list_head tasks; /* * ptrace_list/ptrace_children链表是ptrace能够看到的当前进程的子进程列表。 */ struct list_head ptrace_children; struct list_head ptrace_list; struct mm_struct *mm, *active_mm; /* 进程状态 */ struct linux_binfmt *binfmt; long exit_state; int exit_code, exit_signal; int pdeath_signal; /* 在父进程终止时发送的信号 */ unsigned int personality; unsigned did_exec:1; pid_t pid; pid_t tgid; /* * 分别是指向(原)父进程、最年轻的子进程、年幼的兄弟进程、年长的兄弟进程的指针。 *(p->father可以替换为p->parent->pid) */ struct task_struct *real_parent; /* 真正的父进程(在被调试的情况下) */ struct task_struct *parent; /* 父进程 */ /* * children/sibling链表外加当前调试的进程,构成了当前进程的所有子进程 */ struct list_head children; /* 子进程链表 */ struct list_head sibling; /* 连接到父进程的子进程链表 */ struct task_struct *group_leader; /* 线程组组长 */ /* PID与PID散列表的联系。 */ struct pid_link pids[PIDTYPE_MAX]; struct list_head thread_group; struct completion *vfork_done; /* 用于vfork() */ int __user *set_child_tid; /* CLONE_CHILD_SETTID */ int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ unsigned long rt_priority; cputime_t utime, stime, utimescaled, stimescaled; unsigned long nvcsw, nivcsw; /* 上下文切换计数 */ struct timespec start_time; /* 单调时间 */ struct timespec real_start_time; /* 启动以来的时间 */ /* 内存管理器失效和页交换信息,这个有一点争论。它既可以看作是特定于内存管理器的, 也可以看作是特定于线程的 */ unsigned long min_flt, maj_flt; cputime_t it_prof_expires, it_virt_expires; unsigned long long it_sched_expires; struct list_head cpu_timers[3]; /* 进程身份凭据 */ uid_t uid,euid,suid,fsuid; gid_t gid,egid,sgid,fsgid; struct group_info *group_info; kernel_cap_t cap_effective, cap_inheritable, cap_permitted; unsigned keep_capabilities:1; struct user_struct *user; char comm[TASK_COMM_LEN]; /* 除去路径后的可执行文件名称 -用[gs]et_task_comm访问(其中用task_lock()锁定它) -通常由flush_old_exec初始化 */ /* 文件系统信息 */ int link_count, total_link_count; /* ipc相关 */ struct sysv_sem sysvsem; /* 当前进程特定于CPU的状态信息 */ struct thread_struct thread; /* 文件系统信息 */ struct fs_struct *fs; /* 打开文件信息 */ struct files_struct *files; /* 命名空间 */ struct nsproxy *nsproxy; /* 信号处理程序 */ struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked, real_blocked; sigset_t saved_sigmask; /* 用TIF_RESTORE_SIGMASK恢复 */ struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; int (*notifier)(void *priv); void *notifier_data; sigset_t *notifier_mask; #ifdef CONFIG_SECURITY void *security; #endif /* 线程组跟踪 */ u32 parent_exec_id; u32 self_exec_id; /* 日志文件系统信息 */ void *journal_info; /* 虚拟内存状态 */ struct reclaim_state *reclaim_state; struct backing_dev_info *backing_dev_info; struct io_context *io_context; unsigned long ptrace_message; siginfo_t *last_siginfo; /* 由ptrace使用。*/ ... };- 该结构非常复杂,可将其分解成各个部分:
- 状态和执行信息,如待决信号、使用的二进制格式(和其他系统二进制格式的任何仿真信息)、进程
ID号(pid)、到父进程及其他有关进程的指针、优先级和程序执行有关的时间信息(例如CPU时间)。 - 有关已经分配的虚拟内存的信息。
- 进程身份凭据,如用户
ID、组ID以及权限等。可使用系统调用查询(或修改)这些数据。 - 使用的文件包含程序代码的二进制文件,以及进程所处理的所有文件的文件系统信息,这些都必须保存下来。
- 线程信息记录该进程特定于
CPU的运行时间数据(该结构的其余字段与所使用的硬件无关)。 - 在与其他应用程序协作时所需的进程间通信有关的信息。
- 该进程所用的信号处理程序,用于响应到来的信号。
- 状态和执行信息,如待决信号、使用的二进制格式(和其他系统二进制格式的任何仿真信息)、进程
- 本章将介绍
task_struct中对进程管理的实现特别重要的一些成员,暂时忽略其他变量。
- 该结构非常复杂,可将其分解成各个部分:
state指定了进程的当前状态,可使用下列值(这些是预处理器常数,定义在<sched.h>中)。-
TASK_RUNNING意味着进程处于可运行状态。这并不意味着已经实际分配了CPU。进程可能会一直等到调度器选中它。该状态确保进程可以立即运行,而无需等待外部事件。 -
TASK_INTERRUPTIBLE是针对等待某事件或其他资源的睡眠进程设置的。在内核发送信号给该进程表明事件已经发生时,进程状态变为TASK_RUNNING,它只要调度器选中该进程即可恢复执行。 -
TASK_UNINTERRUPTIBLE用于因内核指示而停用的睡眠进程。它们不能由外部信号唤醒,只能由内核亲自唤醒。 -
TASK_STOPPED表示进程特意停止运行,例如,由调试器暂停。 -
TASK_TRACED本来不是进程状态,用于从停止的进程中,将当前被调试的那些(使用ptrace机制)与常规的进程区分开来。下列常量既可以用于
struct task_struct的进程状态字段,也可以用于exit_state字段,后者明确地用于退出进程。 -
EXIT_ZOMBIE如上所述的僵尸状态。 -
EXIT_DEAD状态则是指wait系统调用已经发出,而进程完全从系统移除之前的状态。只有多个线程对同一个进程发出wait调用时,该状态才有意义。
-
- Linux提供资源限制(
resource limit,rlimit)机制,对进程使用系统资源施加某些限制。该机制利用了task_struct中的rlim数组,数组项类型为struct rlimit。这部分内容在《UNIX环境高级编程》7.11节中已经介绍到,可以结合起来一起看。
<resource.h>struct rlimit { unsigned long rlim_cur; unsigned long rlim_max; }rlim_cur是进程当前的资源限制,也称之为软限制(soft limit)。rlim_max是该限制的最大容许值,因此也称之为硬限制(hard limit)- 系统调用
setrlimit来增减当前限制,但不能超出rlim_max指定的值。getrlimits用于检查当前限制。

- 因为限制涉及内核的各个不同部分,内核必须确认子系统遵守了相应限制。这也是为什么在本书以后几章里我们会屡次遇到
rlimit的原因。 - 如果某一类资源没有使用限制(几乎所有资源的默认设置),则将
rlim_max设置RLIM_INFINITY。例外情况包括下面所列举的。- 打开文件的数目(
RLIMIT_NOFILE,默认限制在1024)。 - 每用户的最大进程数(
RLIMIT_NPROC),定义为max_threads/2。max_threads是一个全局变量,指定了在把1/8可用内存用于管理线程信息的情况下,可以创建的线程数目。在计算时,提前给定了20个线程的最小可能内存用量。
- 打开文件的数目(
init进程的限制在系统启动时即生效,定义在include/asm-generic-resource.h中的INIT_RLIMITS。- 可以用过以下方式查看当前的
rlimit值。lh@LH_LINUX:~$ cat /proc/self/limits Limit Soft Limit Hard Limit Units Max cpu time unlimited unlimited seconds Max file size unlimited unlimited bytes Max data size unlimited unlimited bytes Max stack size 8388608 unlimited bytes Max core file size 0 unlimited bytes Max resident set unlimited unlimited bytes Max processes 31574 31574 processes Max open files 1024 1048576 files Max locked memory 65536 65536 bytes Max address space unlimited unlimited bytes Max file locks unlimited unlimited locks Max pending signals 31574 31574 signals Max msgqueue size 819200 819200 bytes Max nice priority 0 0 Max realtime priority 0 0 Max realtime timeout unlimited unlimited us
3.1、进程类型
- 典型的
UNIX进程包括:由二进制代码组成的应用程序、单线程(计算机沿单一路径通过代码,不会有其他路径同时运行)、分配给应用程序的一组资源(如内存、文件等)。新进程是使用fork和exec系统调用产生的。相关内容在《UNIX环境高级编程》8.3和8.10节中已经介绍到。fork生成当前进程的一个相同副本,该副本称之为子进程。原进程的所有资源都以适当的方式复制到子进程,因此该系统调用之后,原来的进程就有了两个独立的实例。这两个实例的联系包括:同一组打开文件、同样的工作目录、内存中同样的数据(两个进程各有一份副本),等等。此外二者别无关联。(Linux使用了写时复制机制,直至新进程对内存页执行写操作才会复制内存页面,这比在执行fork时盲目地立即复制所有内存页要更高效。父子进程内存页之间的联系,只有对内核才是可见的,对应用程序是透明的。)exec从一个可执行的二进制文件加载另一个应用程序,来代替当前运行的进程。换句话说,加载了一个新程序。因为exec并不创建新进程,所以必须首先使用fork复制一个旧的程序,然后调用exec在系统上创建另一个应用程序。
Linux还提供了clone系统调用。clone的工作原理基本上与fork相同,但新进程不是独立于父进程的,而可以与其共享某些资源。可以指定需要共享和复制的资源种类,例如,父进程的内存数据、打开文件或安装的信号处理程序。此外,clone用于实现线程(需要用户空间库才能提供完整的实现)。
3.2、命令空间
- 命名空间提供了虚拟化的一种轻量级形式,使得我们可以从不同的方面来查看运行系统的全局属性。
- 可参考链接Linux的命名空间中的第
1节来大致了解其基本概念,参考Linux Namespace 是什么,可以用来做什么?进一步了解。
3.2.1、概念
Linux许多资源是全局管理的。- 系统中的所有进程按照惯例是通过
PID标识的,这意味着内核必须管理一个全局的PID列表。而且,所有调用者通过uname系统调用返回的系统相关信息(包括系统名称和有关内核的一些信息)都是相同的。 - 用户ID的管理方式类似,即各个用户是通过一个全局唯一的UID号标识。
- 系统中的所有进程按照惯例是通过
- 全局
ID使得内核可以有选择地允许或拒绝某些特权。UID为n的用户,不允许杀死属于用户m的进程(m≠ n)。但这不能防止用户看到彼此,即用户n可以看到另一个用户m也在计算机上活动。
- 有些情况下,对资源进行全局管理并不是想要的。
- 提供
Web主机的供应商打算向用户提供Linux计算机的全部访问权限,包括root权限在内,使用KVM或VMWare提供的虚拟化环境是一种解决问题的方法,但资源分配做得不是非常好。计算机的各个用户都需要一个独立的内核,以及一份完全安装好的配套的用户层应用。
- 提供
- 命名空间提供了一种不同的解决方案,所需资源较少。
- 在上述虚拟化的系统中,一台物理计算机可以运行多个内核,可能是并行的多个不同的操作系统。
- 命名空间则只使用一个内核在一台物理计算机上运作,前述的所有全局资源都通过命名空间抽象起来。这使得可以将一组进程放置到容器中,各个容器彼此隔离。隔离可以使容器的成员与其他容器毫无关系。但也可以通过允许容器进行一定的共享,来降低容器之间的分隔。例如,容器可以设置为使用自身的PID集合,但仍然与其他容器共享部分文件系统。
- 本质上,命名空间建立了系统的不同视图。此前的每一项全局资源都必须包装到容器数据结构中,只有资源和包含资源的命名空间构成的二元组仍然是全局唯一的
- 虽然在给定容器内部资源是自足的,但无法提供在容器外部具有唯一性的ID,下图展示了这种情况
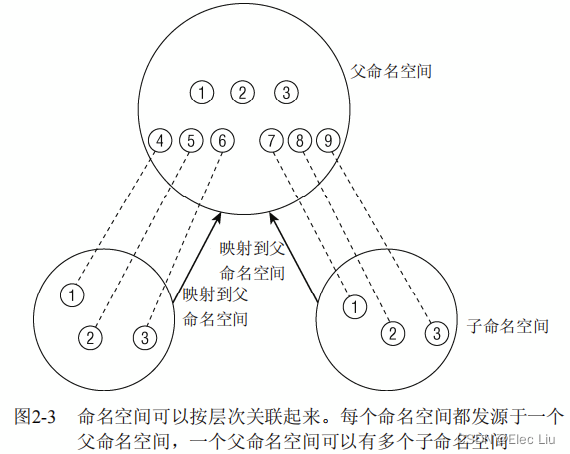
- 考虑系统上有3个不同命名空间的情况。命名空间可以组织为层次。一个命名空间是父命名空间,衍生了两个子命名空间。
- 假定容器用于虚拟主机配置中,其中的每个容器必须看起来像是单独的一台
Linux计算机。因此其中每一个都有自身的init进程,PID为0,其他进程的PID以递增次序分配。两个子命名空间都有PID为0的init进程,以及PID分别为2和3的两个进程。由于相同的PID在系统中出现多次,PID号不是全局唯一的。 - 虽然子容器不了解系统中的其他容器,但父容器知道子命名空间的存在,也可以看到其中执行的所有进程。
- 图中子容器的进程映射到父容器中,PID为
4到9。尽管系统上有9个进程,但却需要15个PID来表示,因为一个进程可以关联到多个PID。至于哪个PID是“正确”的,则依赖于具体的上下文。 - 如果命名空间包含的是比较简单的量,也可以是非层次的,例如下文讨论的UTS命名空间。在这种情况下,父子命名空间之间没有联系。
- 新的命名空间可以用下面两种方法创建
- 在用
fork或clone系统调用创建新进程时,有特定的选项可以控制是与父进程共享命名空间,还是建立新的命名空间。 unshare系统调用将进程的某些部分从父进程分离,其中也包括命名空间
- 在用
- 在进程已经使用上述的两种机制之一从父进程命名空间分离后,从该进程的角度来看,改变全局属性不会传播到父进程命名空间,而父进程的修改也不会传播到子进程,至少对于简单的量是这样。而对于文件系统来说,情况就比较复杂,其中的共享机制非常强大,带来了大量的可能性,具体的情况会在第8章讨论。
3.2.2、实现
- 命名空间的实现需要两个部分
- 每个子系统的命名空间结构,将此前所有的全局组件包装到命名空间中。
- 将给定进程关联到所属各个命名空间的机制。
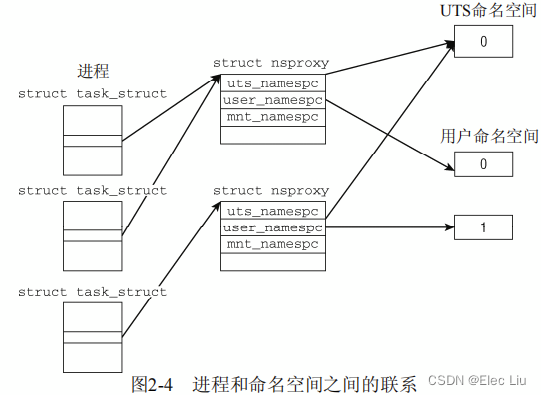
- 子系统此前的全局属性现在封装到命名空间中,每个进程关联到一个选定的命名空间。每个可以感知命名空间的内核子系统都必须提供一个数据结构,将所有通过命名空间形式提供的对象集中起来。
struct nsproxy用于汇集指向特定于子系统的命名空间包装器的指针(本章们主要讲解UTS和用户命名空间):
<nsproxy.h>struct nsproxy { atomic_t count; /*UTS命名空间包含了运行内核的名称、版本、底层体系结构类型等信息。 UTS是UNIX Timesharing System的简称。*/ struct uts_namespace *uts_ns; /*保存在struct ipc_namespace中的所有与进程间通信(IPC)有关的信息。*/ struct ipc_namespace *ipc_ns; /*已经装载的文件系统的视图,在struct mnt_namespace中给出。*/ struct mnt_namespace *mnt_ns; /*有关进程ID的信息,由struct pid_namespace提供。*/ struct pid_namespace *pid_ns; /*struct user_namespace保存的用于限制每个用户资源使用的信息*/ struct user_namespace *user_ns; /*struct net_ns包含所有网络相关的命名空间参数,具体内容在第12章中*/ struct net *net_ns; }; - 由于在创建新进程时可使用
fork建立一个新的命名空间,因此必须提供控制该行为的适当的标志。每个命名空间都有一个对应的标志:
<sched.h>
每个进程都关联到自身的命名空间视图:#define CLONE_NEWUTS 0x04000000 /* 创建新的utsname组 */ #define CLONE_NEWIPC 0x08000000 /* 创建新的IPC命名空间 */ #define CLONE_NEWUSER 0x10000000 /* 创建新的用户命名空间 */ #define CLONE_NEWPID 0x20000000 /* 创建新的PID命名空间 */ #define CLONE_NEWNET 0x40000000 /* 创建新的网络命名空间 */
<sched.h>
因为使用了指针,多个进程可以共享一组子命名空间。这样,修改给定的命名空间,对所有属于该命名空间的进程都是可见的。struct task_struct { ... /* 命名空间 */ struct nsproxy *nsproxy; ... } - 对命名空间的支持必须在编译时启用,而且必须逐一指定需要支持的命名空间。但对命名空间的一般性支持总是会编译到内核中。 这使得内核不管有无命名空间,都不必使用不同的代码。除非指定不同的选项,否则每个进程都会关联到一个默认命名空间,这样可感知命名空间的代码总是可以使用。但如果内核编译时没有指定对具体命名空间的支持,默认命名空间的作用则类似于不启用命名空间,所有的属性都相当于全局的。
init_nsproxy定义了初始的全局命名空间,其中维护了指向各子系统初始的命名空间对象的指针:
<kernel/nsproxy.c>
<init_task.h>struct nsproxy init_nsproxy = INIT_NSPROXY(init_nsproxy);#define INIT_NSPROXY(nsproxy) { \ .pid_ns = &init_pid_ns, \ .count = ATOMIC_INIT(1), \ .uts_ns = &init_uts_ns, \ .mnt_ns = NULL, \ INIT_NET_NS(net_ns) \ INIT_IPC_NS(ipc_ns) \ .user_ns = &init_user_ns, \ }
3.2.2.1、UTS命名空间
- UTS命名空间几乎不需要特别的处理,因为它只需要简单量,没有层次组织。所有相关信息都汇集到下列结构的一个实例中:
<utsname.h>struct uts_namespace { struct kref kref; struct new_utsname name; };kref是一个嵌入的引用计数器,可用于跟踪内核中有多少地方使用了struct uts_namespace的实例(回想第1章,其中讲述了更多有关处理引用计数的一般框架信息)。uts_namespace所提供的属性信息本身包含在struct new_utsname中:
<utsname.h>
各个字符串分别存储了系统的名称(Linux…)、内核发布版本、机器名,等等。使用struct new_utsname { char sysname[65]; char nodename[65]; char release[65]; char version[65]; char machine[65]; char domainname[65]; };uname工具可以取得这些属性的当前值。
- 初始设置保存在
init_uts_ns中
init/version.cstruct uts_namespace init_uts_ns = { ... .name = { .sysname = UTS_SYSNAME, .nodename = UTS_NODENAME, .release = UTS_RELEASE, .version = UTS_VERSION, .machine = UTS_MACHINE, .domainname = UTS_DOMAINNAME, }, };- 相关的预处理器常数在内核中各处定义。例如,
UTS_RELEASE在<utsrelease.h>中定义,该文件是连编时通过顶层Makefile动态生成的。 UTS结构的某些部分不能修改。例如,把sysname换成Linux以外的其他值是没有意义的,但改变机器名是可以的。
- 相关的预处理器常数在内核中各处定义。例如,
- 内核如何创建一个新的
UTS命名空间呢?- 这属于
copy_utsname函数的职责。在某个进程调用fork并通过CLONE_NEWUTS标志指定创建新的UTS命名空间时,则调用该函数。 - 在这种情况下,会生成先前的
uts_namespace实例的一份副本,当前进程的nsproxy实例内部的指针会指向新的副本。如此而已! - 由于在读取或设置
UTS属性值时,内核会保证总是操作特定于当前进程的uts_namespace实例,在当前进程修改UTS属性不会反映到父进程,而父进程的修改也不会传播到子进程。
- 这属于
3.2.2.2、用户命名空间
-
用户命名空间在数据结构管理方面类似于
UTS:在要求创建新的用户命名空间时,则生成当前用户命名空间的一份副本,并关联到当前进程的nsproxy实例。但用户命名空间自身的表示要稍微复杂一些:
<user_namespace.h>struct user_namespace { struct kref kref; struct hlist_head uidhash_table[UIDHASH_SZ]; struct user_struct *root_user; };kref是一个引用计数器,用于跟踪多少地方需要使用user_namespace实例- 对命名空间中的每个用户,都有一个
struct user_struct的实例负责记录其资源消耗。 - 各个实例可通过散列表
uidhash_table访问。
-
对我们来说
user_struct的精确定义是无关紧要的。只要知道该结构维护了一些统计数据(如进程和打开文件的数目)就足够了。我们更感兴趣的问题是:每个用户命名空间对其用户资源使用的统计,与其他命名空间完全无关,对root用户的统计也是如此。这是因为在克隆一个用户命名空间时,为当前用户和root都创建了新的user_struct实例:
kernel/user_namespace.cstatic struct user_namespace *clone_user_ns(struct user_namespace *old_ns) { struct user_namespace *ns; struct user_struct *new_user; ... ns = kmalloc(sizeof(struct user_namespace), GFP_KERNEL); ... ns->root_user = alloc_uid(ns, 0); /* 将current->user替换为新的 */ new_user = alloc_uid(ns, current->uid); switch_uid(new_user); return ns; }alloc_uid是一个辅助函数,对当前命名空间中给定UID的一个用户,如果该用户没有对应的user_struct实例,则分配一个新的实例。- 在为
root和当前用户分别设置了user_struct实例后,switch_uid确保从现在开始将新的user_struct实例用于资源统计。实质上就是将struct task_struct的user成员指向新的user_struct实例 - 如果内核编译时未指定支持用户命名空间,那么复制用户命名空间实际上是空操作,即总是会使用默认的命名空间。
3.3、进程ID号
- UNIX进程总是会分配一个号码用于在其命名空间中唯一地标识它们。该号码被称作进程ID号,
简称PID。用fork或clone产生的每个进程都由内核自动地分配了一个新的唯一的PID值。
3.3.1、进程ID

- 每个进程除了PID这个特征值之外,还有其他的ID。有下列几种可能的类型,具体看《UNUX环境高级编程》(9)进程关系的对应章节。
- 线程组:在一个进程中,以标志
CLONE_THREAD来调用clone建立的该进程的不同的执行上下文。(这是本书对线程组的定义,线程组的其他性质可以参照上面提供的链接,记得学习clone()的用法) - 进程组:独立进程可以合并成进程组(使用
setpgrp系统调用)。进程组成员的task_struct的pgrp属性值都是相同的,即进程组组长的PID。进程组简化了向组的所有成员发送信号的操作。 - 会话:几个进程组可以合并成一个会话。会话中的所有进程都有同样的会话
ID,保存在task_struct的session成员中。SID可以使用setsid系统调用设置,它可以用于终端程序设计。
- 线程组:在一个进程中,以标志
- 命名空间增加了
PID管理的复杂性。回想一下,PID命名空间按层次组织。在建立一个新的命名空间时,该命名空间中的所有PID对父命名空间都是可见的,但子命名空间无法看到父命名空间的PID。但这意味着某些进程具有多个PID,凡可以看到该进程的命名空间,都会为其分配一个PID。 这必须反映在数据结构中。我们必须区分局部ID和全局ID。- 全局ID:是在内核本身和初始命名空间中的唯一
ID号,在系统启动期间开始的init进程即属于初始命名空间。对每个ID类型,都有一个给定的全局ID,保证在整个系统中是唯一的。 - 局部ID:属于某个特定的命名空间,不具备全局有效性。对每个ID类型,它们在所属的命名空间内部有效,但类型相同、值也相同的ID可能出现在不同的命名空间中。
- 全局ID:是在内核本身和初始命名空间中的唯一
- 全局
PID和TGID直接保存在task_struct中,分别是task_struct的pid和tgid成员:
<sched.h>struct task_struct { /*这两项都是pid_t类型,该类型定义为__kernel_pid_t,后者由各个体系结构分别定义。 通常定义为int,即可以同时使用2^32个不同的ID*/ ... pid_t pid; pid_t tgid; ... } - 会话和进程组
ID不是直接包含在task_struct本身中,但保存在用于信号处理的结构中。task_struct->signal->__session表示全局SID,而全局PGID则保存在task_struct->signal->__pgrp。辅助函数set_task_session和set_task_pgrp可用于修改这些值。- 辅助函数
set_task_session
<sched.h>static inline void set_task_session(struct task_struct *tsk, pid_t session) { tsk->signal->__session = session; } - 辅助函数
set_task_pgrp
<sched.h>static inline void set_task_pgrp(struct task_struct *tsk, pid_t pgrp) { tsk->signal->__pgrp = pgrp; }
- 辅助函数
3.3.2、管理ID
- 除了
PID和TGID,内核还需要找一个办法来管理所有命名空间内部的局部量,以及其他ID(如TID和SID)。这需要几个相互连接的数据结构,以及许多辅助函数。
补充B:《深入理解Linux内核》中关于该节的描述(3.3.2.1节可读性较差)
-
顺序扫描进程链表并检查进程描述符的
pid字段虽然可行但十分低效。为了加速查找,引入了4个散列表。需要4个散列表是因为进程描述符包含了不同类型的PID字段,而且每种类型的PID需要它自己的散列表。

-
内核初始化期间动态地为4个散列表分配空间,并把它们的地址存入
pid_hash数组。(对照图3-6进行理解)用pid_hashfn宏把PID转换为表索引,其展开为:#define pid_hashfn(x) hash_long((unsigned long) x, pidhash_shift)- 变量
pidhash_shift用来存放表索引的长度(以位为单位的长度,这里的例子是11位)。很多散函数都使用hash_long(),在32为体系结构它基本等价于:/*这种三列函数是基于表索引乘于一个适当的大数,于是结果溢出, 就把留在32为变量中的值作为模数操作的结果*/ unsigned long hash_long(unsigned long val,unsigned int bits){ /*该数字为魔数常亮,最接近黄金比例的2^32的一个素数,即该数最接近2^32 x (根号5 -1)/2*/ unsigned long hash = val * 0x9e370001UL; return hash >> (32 - bits); } - 因为我们的例子中
pidhash_shift为11,所以pid_hashfn的取值范围是0~2^11 - 1=2047
- 变量
-
使用散列表可能会造成哈希碰撞,可以复习一下散列表的内容。Linux使用链表(拉链法)来解决哈希碰撞:每一个表项是由冲突的进程描述符组成的双向链表。下图实现了具有两个链表的PID散列表。

- 图中
PID为2890和29584的两个进程散列到这个表的第200个元素,而进程号为29385的进程散列到这个表的第1466个元素。
- 图中
-
PID散列表解决了许多难题,因为它们可以为包含在一个散列表中的任何
PID号定义进程链表,最主要的数据结构是四个pid结构的数组,它在进程描述符的pid字段中,下表显示了pid结构的字段。

下图给出了PIDTYPE_TGID类型散列表的例子。

pid_hash数组的第二个元素存放散列表的地址,也就是用hlist_head结构的数组表示链表的头。在散列表的第71项为起点形成的链表中,有两个PID号为246和4351的进程描述符。PID的值存放在pid结构的nr字段中,而pid结构在进程描述符中(由于线程组的号和他的首创者的PID相同,因此这些PID的值也在进程描述符的pid字段中)。我们考虑一下线程组4351的PID链表:散列表中的进程描述符的pid_list字段中存放链表的头,同时每个PID链表中指向前一个元素和后一个元素的指针也存放在每个链表元素的pid_list字段中。- 这个图很好理解,建议和
task_struct结构体放在一起进行比较,想象一下对应的连接关系。 - 这里只描述了
PIDTYPE_TGID类型散列表的例子,对应于pids[1],其他散列表也是一样的原理。
-
注意:该补充章节选自《深入理解Linux内核》,与《深入Linux内核架构》有差别。差别如下:《深入Linux内核架构》缺少
PIDTYPE_TGID,因为线程组ID无非是线程组组长的PID。《深入Linux内核架构》增加了命令空间的介绍,相应的数据结构定义地更加繁琐。
3.3.2.1、数据结构
(下文将使用ID指代提到的任何进程ID。在必要的情况下,会明确地说明ID类型(例如,TGID,即线程组ID))。
-
一个小型的子系统称之为
PID分配器(pid allocator)用于加速新ID的分配。此外,内核需要提供辅助函数,以实现通过ID及其类型查找进程的task_struct的功能,以及将ID的内核表示形式和用户空间可见的数值进行转换的功能。 -
在介绍表示
ID本身所需的数据结构之前,需要先讨论PID命名空间的表示方式。
<pid_namespace.h>struct pid_namespace { ... /*每个PID命名空间都具有一个进程,其发挥的作用相当于全局的init进程。init的一个目的是 对孤儿进程调用wait4,命名空间局部的init变体也必须完成该工作。child_reaper保存了 指向该进程的task_struct的指针。child_reaper中reaper译为收割者,收割机,骷髅状死神。*/ struct task_struct *child_reaper; ... /*level表示当前命名空间在命名空间层次结构中的深度。初 始命名空间的level为0,该命名空间的子空间level为1,下一层的子空间level为2,依次递推。 level的计算比较重要,因为level较高的命名空间中的ID,对level较低的命名空间来说是可见的。 从给定的level设置,内核即可推断进程会关联到多少个ID。建议回顾一下命名空间的相关内容*/ int level; /*parent是指向父命名空间的指针*/ struct pid_namespace *parent; };- 实际上
PID分配器也需要依靠该结构的某些部分来连续生成唯一ID,暂时先不关注
- 实际上
-
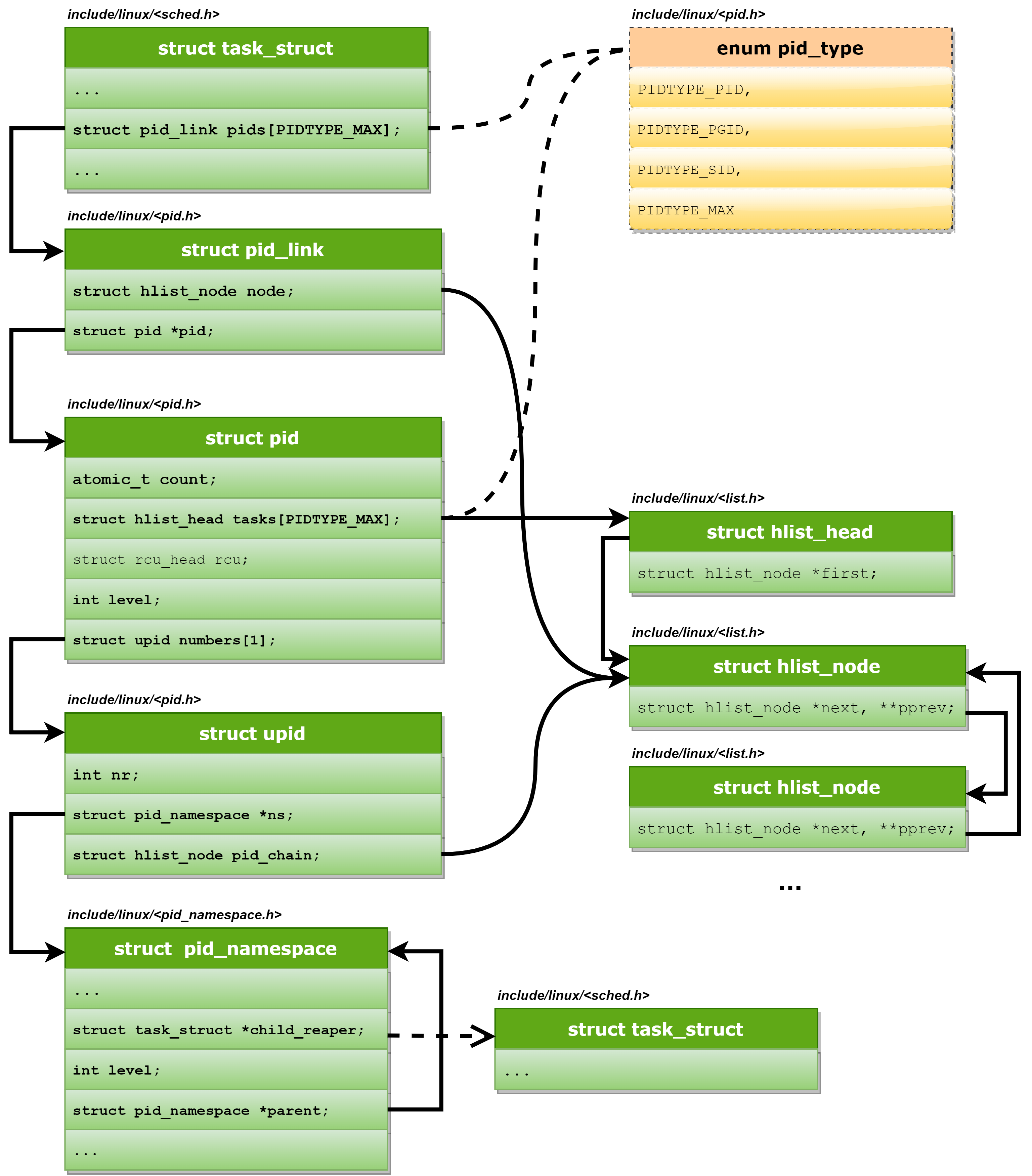
PID的管理围绕两个数据结构展开:struct pid和struct upid,注意,一定要和task_struct中的pid区分开,后者真的就只是一个pid数值。而前置针对的PID的内部表示,包含了非常多的信息。
<pid.h>/*内核对PID的内部表示*/ struct pid { /*引用计数器*/ atomic_t count; /* 使用该pid的进程的列表, 每个数组项都是一个散列表头。 对应于一个ID类型。这样做是必要的,因为一个ID可能用于几个进程。 所有共享同一给定ID的task_struct实例,都通过该列表连接起来。PIDTYPE_MAX表示ID类型的数目:*/ struct hlist_head tasks[PIDTYPE_MAX]; /*level表示可以看到该进程的命名空间的数目(换言之,即包含该进程的命名空间在命名空间层次结构中的深度)*/ int level; /*numbers是一个upid实例的数组,每个数组项都对应于一个命名空间。注意该数组形式上只有一个 数组项,如果一个进程只包含在全局命名空间中,那么确实如此。由于该数组位于结构的末尾,因此 只要分配更多的内存空间,即可向数组添加附加的项。*/ struct upid numbers[1]; }; /*表示特定的命名空间中可见的信息*/ struct upid { /*表示ID的数值*/ int nr; /*指向该ID所属的命名空间的指针*/ struct pid_namespace *ns; /*所有的upid实例都保存在一个散列表中,稍后我们会看到该结构。 pid_chain用内核的标准方法实现了散列溢出链表。*/ struct hlist_node pid_chain; }; /*枚举类型中定义的ID类型不包括线程组ID!这是因为线程组ID无非是线程组组长的PID 而已,因此再单独定义一项是不必要的。*/ enum pid_type { PIDTYPE_PID, PIDTYPE_PGID, PIDTYPE_SID, PIDTYPE_MAX };
由于所有共享同一ID的task_struct实例都按进程存储在一个散列表中,因此需要在struct task_struct中增加一个散列表元素:
<sched.h>struct task_struct { ... /* PID与PID散列表的联系。 */ struct pid_link pids[PIDTYPE_MAX]; ... };辅助数据结构
pid_link可以将task_struct连接到表头在struct pid中的散列表上
<pid.h>struct pid_link { /*用作散列表元素*/ struct hlist_node node; /*指向进程所属的pid结构实例*/ struct pid *pid; };为在给定的命名空间中查找对应于指定
PID数值的pid结构实例,使用了一个散列表。
kernel/pid.c/*hlist_head是一个内核的标准数据结构,用于建立双链散列表。pid_hash用作一个hlist_head数组。 数组的元素数目取决于计算机的内存配置,大约在2^4=16和2^12=4096之间。 pidhash_init用于计算恰当的容量并分配所需的内存。*/ static struct hlist_head *pid_hash;假如已经分配了
struct pid的一个新实例,并设置用于给定的ID类型。它会如下附加到task_struct:
kernel/pid.cint fastcall attach_pid(struct task_struct *task, enum pid_type type, struct pid *pid) { struct pid_link *link; link = &task->pids[type]; link->pid = pid; hlist_add_head_rcu(&link->node, &pid->tasks[type]); return 0; }- 这里建立了双向连接:
task_struct可以通过task_struct->pids[type]->pid访问pid实例。而从pid实例开始,可以遍历tasks[type]散列表找到task_struct。hlist_add_head_rcu是遍历散列表的标准函数,此外还确保了遵守RCU机制(参见第5章)。因为,在其他内核组件并发地操作散列表时,可防止竞态条件(race condition)出现。
- 这里建立了双向连接:















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











