







HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks
公众号:EDPJ
目录
0. 摘要
作为在训练数据非常有限的情况下训练 GAN 的方法,GAN 的域自适应框架近年来取得了很大进展。在这项工作中,我们通过提出一个极其紧凑的参数空间来微调生成器,从而显着改进这个框架。我们引入了一种新颖的域调制技术,该技术仅允许优化 6000 维向量而不是 StyleGAN2 的 3000 万个权重以适应目标域。 我们将此参数化应用于最先进的领域自适应方法,并表明它具有与完整参数空间几乎相同的表现力。此外,我们提出了一种新的正则化损失,它大大增强了微调生成器的多样性。受优化参数空间大小减小的启发,我们考虑了 GAN 的多域适应问题,即设置同一模型何时可以根据输入 query 适应多个域。我们提出了 HyperDomainNet,它是一个超网络,可以在给定目标域的情况下预测我们的参数化。 我们凭经验证实它可以一次成功地学习多个领域,甚至可以推广到看不见的领域。
1. 简介
GAN 迁移学习方法的标准方法是微调预训练模型的几乎所有权重。在目标域离源域很远的情况下,这可能是合理的,例如当我们将在人脸上预训练的生成器调整到动物或建筑物领域时。但是,在很多情况下,数据域之间的距离不会太远:主要在纹理、风格、几何形状方面有所不同,同时保持相同的内容,如面部或户外场景。对于这种情况,微调源生成器的所有权重似乎是多余的。在将 StyleGAN2 迁移学习到类似领域后,网络的某些部分几乎没有变化。这一观察结果促使我们为 GAN 的域自适应找到一个更高效、更紧凑的参数空间。
在本文中,我们提出了一种新的域调制操作,可以减少用于微调 StyleGAN2 的参数空间。这个想法是针对每个目标域只优化一个向量 d。我们通过每个卷积层的调制操作将这个向量合并到 StyleGAN2 架构中。向量 d 的维度等于 6000,比 StyleGAN2 的原始权重空间小 5000 倍。我们将此参数化应用于最先进的域适应方法 StyleGAN-NADA 和 MindTheGAP。我们表明它具有与全参数化几乎相同的性能,同时更轻量级。为了进一步推进 GAN 的域适应框架,我们提出了一种新的正则化损失,可以提高微调生成器的多样性。
参数化规模的显着减少促使我们考虑 GAN 的多域适应问题,即同一模型何时可以根据输入查询适应多个域。通常,以前的方法只是通过为每个目标域独立地微调单独的生成器来解决这个问题。相比之下,我们建议训练一个超网络,根据目标域预测 StyleGAN2 的向量 d。我们称这个网络为 HyperDomainNet。如果我们需要预测 StyleGAN2 的所有权重,那么这种超网络将无法训练。多域框架的直接好处包括减少训练时间和可训练参数的数量,因为我们训练一个 HyperDomainNet 来同时适应 n 个域,而不是微调 n 个单独的生成器。这种方法的另一个优点是,我们根据经验观察到,如果 n 足够大,它可以推广到未见过的域。
总而言之,我们的主要贡献是:
- 我们通过提出域调制技术减少了 StyleGAN2 生成器域适应的可训练参数的数量。现在我们可以只训练 6 千维向量,而不是为每个新域微调所有 3000 万个 StyleGAN2 权重。
- 我们引入了一种新的正则化损失,它大大提高了自适应生成器的多样性。
- 我们提出了一个 HyperDomainNet,它可以预测输入域的参数化向量并允许 GAN 的多域自适应。它显示了在不可见域上良好的泛化结果。
2. 相关工作
为 GAN 的自适应约束参数空间。生成器在适应目标域的过程中利用来自源域的信息尤为重要。常见的方法是对可训练权重引入一些限制,以便在微调期间对其进行正则化。例如,
- 仅优化预训练权重的奇异值并将其应用于 few-shot 域自适应,但是报告的结果显示这种参数化的表达能力有限。
- 另一种方法通过在微调期间仅优化 BN 统计来限制具有批量归一化 (BN) 层的模型的参数空间,例如 BigGAN。虽然它允许减少可训练参数的数量,但它也大大降低了生成器的表现力。
- 另一种方法是在每个步骤的优化过程中自适应地选择层的子集,如 StyleGAN-NADA 中那样。 它有助于稳定训练,但它不会减少参数空间,因为每一层都可能被微调。
- 另一种方法是像 TargetCLIP 那样优化 StyleGAN 隐空间中的参数,这个空间的大小远小于整个网络的大小。然而,这种方法主要用于域内编辑,并且在适应新域方面表现出较差的质量。
相比之下,我们的参数化具有与完整参数空间相当的表现力和适应质量,而其大小却小了三个数量级。
3. 基础
在这项工作中,我们专注于领域自适应背景下的 StyleGAN 生成器。我们将 StyleGAN2 视为基础模型。作为最先进的领域适应方法,我们使用 StyleGAN-NADA 和 MindTheGAP。
StyleGAN2。StyleGAN2 生成过程由几个部分组成。第一部分是映射网络 M(z),它将来自初始隐空间的随机向量 z ∈ Z 作为输入,Z 通常呈正态分布。它将这些向量 z 变换到中间隐空间 W。每个向量 w ∈ W 进一步馈送到生成器每一层的不同仿射变换 A(w)。这部分的输出形成 StyleSpace S,它由通道风格参数 s = A(w) 组成。生成过程的下一部分是合成网络 G_sys,它将相应层的常量张量 c 和样式参数 s 作为输入,并生成不同分辨率的最终特征图 F = G_sys (c , s)。这些特征映射移动到最后一部分,它由生成输出图像 I = G_tRGB (F) 的 toRGB 层 G_tRGB 组成。
领域适应的问题表述。StyleGAN2 的域适应问题可以表述如下。我们为源域 A 和目标域 B 提供了一个经过训练的生成器 G^A,目标域 B 由一个图像 I_B(一次性自适应)或文本描述 t_B(文本引导自适应)表示。 目的是从 G^A 的权重开始为域 B 微调新生成器 G^B 的权重 θ。 一般形式的优化过程是
![]()
其中 L 是损失函数,n 是 batch 的大小,w_1; ... ; w_n 是随机隐编码, 分别是从 G^B 和 G^A 生成器采样的图像 batch,B、A 是表示由图片或文字描述的域。
CLIP 模型。CLIP 是一种视觉语言模型,分别由文本和图像编码器 E_T 和 E_I 组成,将它们的输入映射到具有单位范数的联合多模态向量空间(该空间通常称为 CLIP 空间)。在这个空间中,embedding 之间的余弦距离反映了相应对象的语义相似性。
StyleGAN-NADA。StyleGAN-NADA 是一项开创性工作,它利用 CLIP 模型对 StyleGAN 进行文本引导域自适应。建议的损失函数是
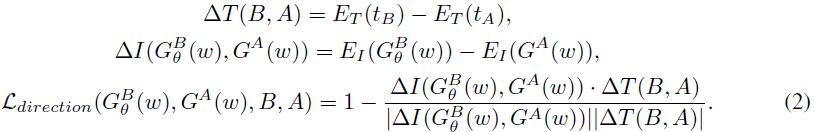
这个想法是将源图像和目标图像 △I(G^B (w) ; G^A (w)) 之间的 CLIP 空间方向与源和目标文本描述 △T(B;A) 之间的方向对齐。 因此,整体优化过程具有以下形式
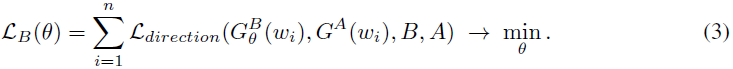
在 StyleGAN-NADA 方法中,L_B (w) 损失仅针对具有 2400 万权重的合成网络 G^B 的权重 θ 进行优化。
MindTheGap。 该方法被提出用于 StyleGAN 的 one-shot 域自适应,即域 B 由单个图像 I_B 表示。原则上,StyleGAN-NADA 方法只需将等式 (2) 中的文本方向 △T(B;A) 替换为图像方向即可。
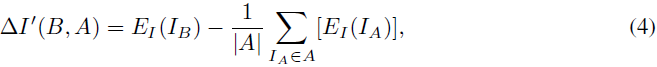
其中,第二项是来自域 A 的图像的平均 embedding。然而,这会导致迁移的图像失去域 A 的初始多样性并变得太接近图像 I_B。 因此,MindTheGap 的关键思想是,通过 GAN 反演方法 II2S,获得图像 I_B 在域 A 的投影 I_A ,使用 I_A 替换等式(4)中的平均 embedding:
![]()
因此,MindTheGap 使用修改的方向损失,重命名为 Lclip_accross 。
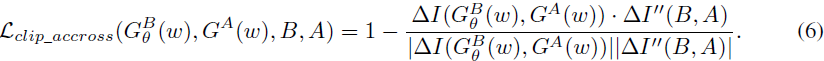
除了此之外,还引入了几个新的正则化器,它们强制生成器 G^B 从其投影 I_A 重建图像 I_B。 它进一步稳定和提高了领域自适应的质量。总的来说,MindTheGAP 损失函数 L_MTG 有四个项来优化 G^B。
4. 方法
4.1 用于域自适应的域调制技术
我们的主要目标是通过探索有效且紧凑的参数空间来改进 StyleGAN 的领域适应性,以将其用于微调 G^B。
正如我们在第 3 节中所述,StyleGAN 有四个组件:映射网络 M(·)、仿射变换 A(·)、合成网络 G_sys(·,·) 和 toRGB 层 G_tRGB (·)。在对目标域进行微调期间,StyleGAN 的主要部分是合成网络 G_sys(·,·)。StyleGAN-NADA 和 MindTheGap 方法也证实了这一点,因为它们仅针对目标域调整 G_sys(·,·) 的权重。
因此,我们的目标是找到一种有效的方法来微调 G_sys( ; ) 的特征卷积的权重。在 StyleGAN2 中,这些卷积利用调制/解调操作来处理输入张量和相应的样式参数 s。 让我们重新审视这些操作的机制:
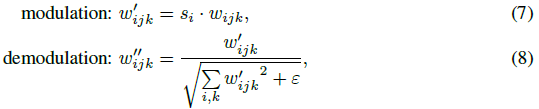
其中 w,w' 和 w'' 分别是原始、调制和解调的权重,s_i 是样式参数 s 的分量,i 和 j 分别枚举输入和输出通道。调制/解调背后的想法是将标准自适应实例归一化 (adaptive instance normalization,AdaIN) 替换为基于输入特征图的预期统计数据的归一化。因此,调制部分基本上是一种自适应缩放操作,就像在 AdaIN 中一样,由样式参数 s 控制。这一观察启发我们将这种技术用于领域适应。
将 GAN 微调到新域的问题与风格迁移的任务非常相关,其目标也是将图像从源域转换到具有指定样式的新域。解决这个任务的当代方法是训练一个以目标风格作为输入条件的图像到图像网络。这种方法的基础是提供有效调节的 AdaIN。特别是,它允许训练任意的风格迁移模型。因此,它激励我们应用 AdaIN 技术使 GAN 适应新领域。
我们引入了一种新的域调制操作,可减少微调 StyleGAN2 的参数空间。这个想法是只优化与样式参数 s 具有相同维度的向量 d。我们通过在等式(7)中的标准调制操作之后附加调制操作将此矢量合并到 StyleGAN 架构中:
![]()
其中 d_i 是引入的域参数 d 的分量(见图 1a)。因此,我们只训练向量 d,而不是优化 G_sys 部分的所有权重 θ。

我们将这些新的参数化应用于 StyleGAN-NADA 和 MindTheGAP 方法,即不是优化对应于 θ 的损失函数,而是优化对应于向量 d 的。向量 d 的维度等于 6000,比 G_sys 部分的原始权重空间 θ 小 4000 倍。
4.2 提高 CLIP 引导的域适应的多样性
基于 CLIP 的域适应方法 StyleGAN-NADA 和 MindTheGap 使用 L_direction(或 Lclip_accross)损失(见等式(2)和(6)),最初是为了处理微调生成器的模式崩溃问题而引入的。然而,我们凭经验观察到,它只能部分解决问题。特别是,它仅在微调过程开始时保留多样性,并在数百次迭代后开始崩溃。这是一个重要的问题,因为对于某些领域,我们需要更多的迭代才能获得可接受的质量。
L_direction(与 Lclip_accross 相同)损失的这种不良行为的主要原因是它计算不位于 CLIP 空间中的 embedding 之间的 CLIP 余弦距离。事实上,余弦距离是位于 CLIP 球体上的对象的自然距离,但对于表示不再位于单位球体上的 CLIP embedding 之间的差异向量 △T、△I,变得不那么明显。因此,L 方向损失背后的想法可能会产生误导,在实践中我们可以观察到它仍然遭受模式崩溃。
我们引入了一种新的正则化器来提高多样性,它只计算 CLIP embedding 之间的 CLIP 余弦距离。 我们称之为域内角度一致性损失,我们定义如下
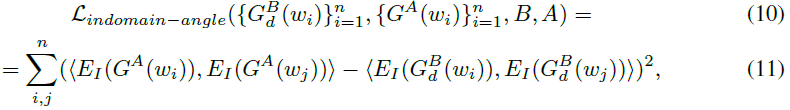
L_indomain-angle loss 的思想是在域自适应之前和之后保留图像之间的 CLIP 成对余弦距离。我们观察到,与原始 L_direction 或 Lclip_accross 损失相比,这种损失显着提高了生成器 G^B 的多样性。
4.3 为通用域自适应设计 HyperDomainNet
所提出的域调制技术使我们能够减少可训练参数的数量,这促使我们解决 StyleGAN2 的多域自适应问题。我们的目标是,在给定输入目标域的情况下,训练预测域参数的 HyperDomainNet。这个问题可以表述如下。我们有一个经过训练的生成器 G^A,用于源域 A 和多个目标域 B_1,...,B_m,可以用单张图片或文字描述来表示。目的是学习可以预测域参数 d = D(B) 的 HyperDomainNet D,它将用于通过域调制操作获得微调生成器 G^B(参见第 4.1 节)。
在这项工作中,关注由文本描述 t_B1,...,t_Bm 表示目标域 B1,...,Bm 时的设置。HyperDomainNet D 将 CLIP 编码器 E_T 获得的文本 embedding 作为输入,并输出域参数 d = D ( E_T ( t_B ))。 训练过程如图 2 所示。
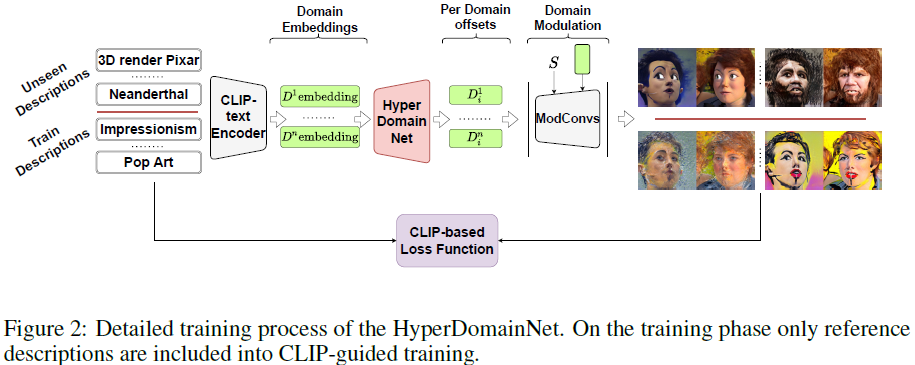
为了训练 HyperDomainNet D,我们使用每个目标域的 L_direction 损失之和。此外,我们引入了与 L 方向相同的 L_tt-direction 损失(“tt”代表 target-target),我们在两个目标域之间而不是目标和源之间计算它。 这个想法是为了使来自 CLIP 空间中不同目标域的图像远离。我们观察到,在没有 L_tt-direction 损失的情况下,HyperDomainNet 倾向于学习域的混合。
在多域自适应设置中,正则化器 L_indomain-angle 变得低效,因为在训练 batch 中包含的来自不同域和来自一个域的样本图像数量可能非常小。因此,我们为 HyperDomainNet 引入了另一种正则化 L_domain-norm,它限制了预测域参数的范数。准确的说等于
![]()
因此,HyperDomainNet 的目标函数由 L_direction、L_tt-direction 和 L_domain-norm 损失组成。 有关这些损失的更详细描述的整体优化过程,请参阅附录 A.2。
5. 实验
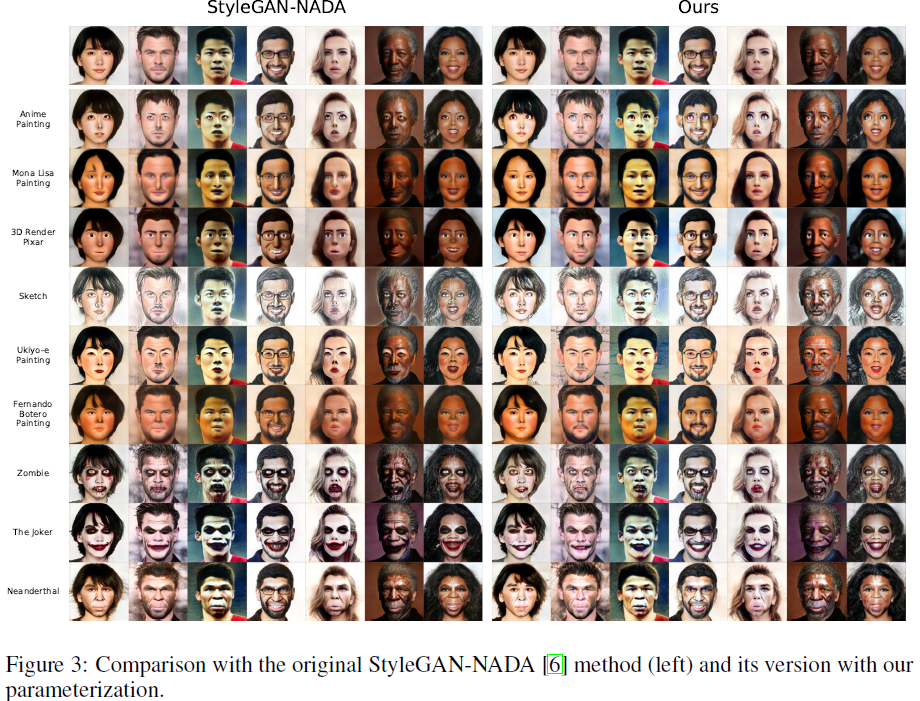
基于文本的域适应。我们将 StyleGAN-NADA 方法与所提出的参数化和原始版本在许多不同的域上进行了比较。在图 3 中,我们看到参数化的性能与原始 StyleGAN-NADA 相当。 我们观察到域调制技术允许生成器适应各种样式和纹理变化。有关更多域的结果,请参阅附录 A.3。我们还在附录 A.3.3 中提供了此设置的定量结果,表明我们的参数化具有与完整参数化相当的性能。
One-Shot 域适应。在这一部分中,我们通过将它们应用于 MindTheGap 来检查我们的参数化和域内角度一致性损失。我们展示了定性和定量结果,并将它们与其他 few-shot 域自适应方法(例如 StyleGAN-NADA、TargetCLIP 和交叉对应方法)进行了比较。为了评估领域适应质量,我们使用标准指标 FID、精度和召回率(Recall)。作为目标域,我们采用具有大约 300 个样本的面部草图 的通用基准数据集。我们考虑 one-shot 自适应设置。我们在表 1 中提供了结果。
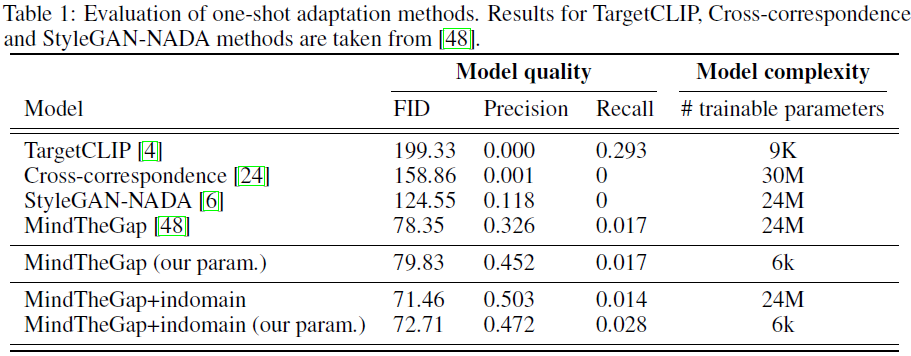
首先,我们看到使用我们的参数化的 MindTheGap 显示了与原始版本相当的结果,同时可训练的参数少了三个数量级。虽然 TargetCLIP 具有与我们的方法相同的参数顺序,但它在 FID 和精度指标方面显示出较差的适应质量,表明它仅适用于域内编辑(另请参见图 19 中附录 A.4 中的定性比较)。其次,我们检查域内角度一致性的有效性。我们表明,它显着提高了原始 MindTheGap 和我们参数化的 MindTheGap 的 FID 和精度指标。

图 4 中提供了 MindTheGap+indomain、我们的参数化的 MindTheGap+indomain(“our”)以及 StyleGAN-NADA 的定性结果。其他方法见附录A.4。 我们观察到 MindTheGap+indomain 和我们的版本显示出相当的视觉质量,并且在多样性和保持与源图像的相似性方面优于 StyleGAN-NADA。
总的来说,我们证明我们的参数化适用于最先进的方法 StyleGAN-NADA 和 MindTheGap,并且可以通过域内角度一致性损失进一步改进。
多域适应。现在我们考虑多域适应问题。我们将 HyperDomainNet 应用于两种不同的场景:(i) 在固定数量的域上进行训练,(ii) 在可能任意数量的域上进行训练。第一个场景很简单,我们在“动漫绘画”(Anime Painting)、“皮克斯”(Pixar)等 20 个不同的领域训练 HyperDomainNet(完整的领域列表请参阅附录 A.2.4)。第二种方案比较复杂。我们固定了大量域(数百个)并计算其 CLIP embedding。在训练期间,我们从初始 embedding 的凸包(convex hull)中采样新的 embedding,并在优化过程中使用它们(参见图 2)。这种技术使我们能够推广到未见过的领域。有关这两种情况的更多详细信息,请参阅附录 A.2。

图 5 提供了两种情况下 HyperDomainNet 的结果。左边是第一种设置的结果,右边是第二种方案中不可见域的结果。有关更多域和生成的图像,请参阅附录 A.2。我们看到,在第一个场景中,HyperDomainNet 显示的结果与我们为每个域训练单独模型时的结果相当(见图 3)。它表明所提出的 HyperDomainNet 优化过程是有效的。第二种情况的结果看起来很有希望。我们可以观察到 HyperDomainNet 已经学习了非常多样化的领域,并且对未见过的领域显示出合理的适应结果。
我们还在附录 A.2.6 中提供了关于我们用于训练 HyperDomainNet 的 loss 项的消融研究。它从数量和质量上证明了,所提出的 loss 对于在多域适应问题的设置中有效训练 HyperDomainNet 至关重要。
6. 结论
为了解决域自适应的模式崩溃,我们引入了一种新的域内角度一致性损失 L_indomain-angle,它保留了域自适应前后图像之间的 CLIP 成对余弦距离。我们证明它提高了基于文本和 one-shot 域适应的微调生成器的多样性。
当我们旨在同时适应多个领域时,我们还考虑了 StyleGAN2 的多领域适应问题。在我们提出参数化之前,这是不可行的,因为我们应该为每个域预测 StyleGAN2 的所有权重。由于我们有效的参数化,我们提出了 HyperDomainNet,它可以预测给定输入域的 StyleGAN2 的 6000 维域向量 d。 我们凭经验证明它可以成功训练到 20 个领域,这是 StyleGAN2 首次同时适应多个领域。我们还通过对域描述应用不同的增强来为大量域(超过 200 个)训练 HyperDomainNet(详见附录 A.2)。我们在实践中证明,在这样的设置中,HyperDomainNet 可以泛化到未见过的域。
局限性和社会影响。我们方法的主要局限性在于它不适用于目标域与源域相距甚远的情况。在这样的设置中,我们不能限制参数空间,所以我们应该使用全参数化。
GAN 域适应和一般 GAN 训练的潜在负面社会影响包括不同形式的虚假信息,例如,名人或高级官员的深度造假(deepfake)、社交平台上的假头像。 然而,这是整个领域的问题,这项工作并没有扩大这种影响。
参考
Alanov, Aibek, Vadim Titov, and Dmitry P. Vetrov. "Hyperdomainnet: Universal domain adaptation for generative adversarial networks." Advances in Neural Information Processing Systems 35 (2022): 29414-29426.
A. 附录
A.1 实验设置
A.1.1 实现细节
我们使用 PyTorch 深度学习框架实施的实验。对于 StyleGAN2 架构,我们使用流行的 PyTorch 实现。我们附上所有重现我们实验的源代码作为补充材料的一部分。我们还提供配置文件来运行每个实验。
A.2 HyperDomainNet (HDN) 的训练
A.2.1 Training Losses
正如我们在第 4.3 节中描述的那样,我们使用三个损失 L_direction、L_tt-direction 和 L_domain-norm 来训练 HDN D。
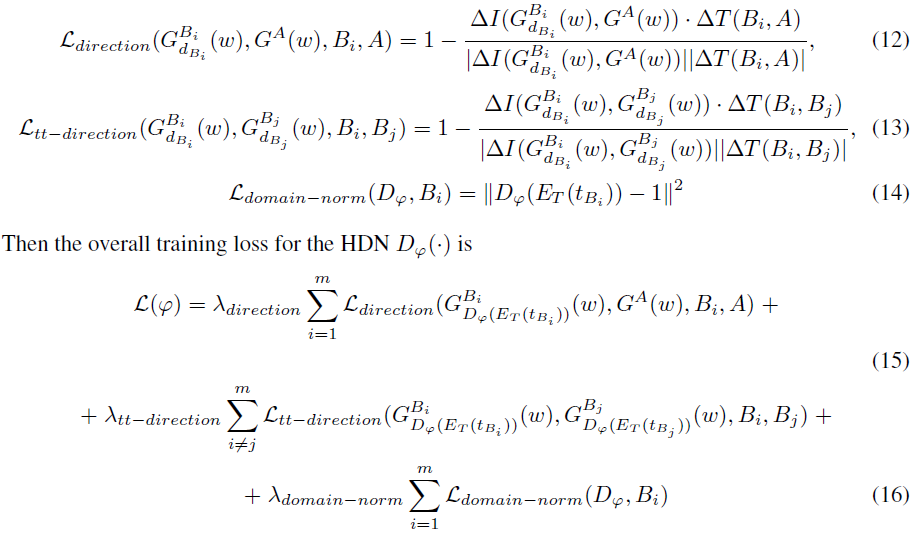
A.2.2 HDN的架构
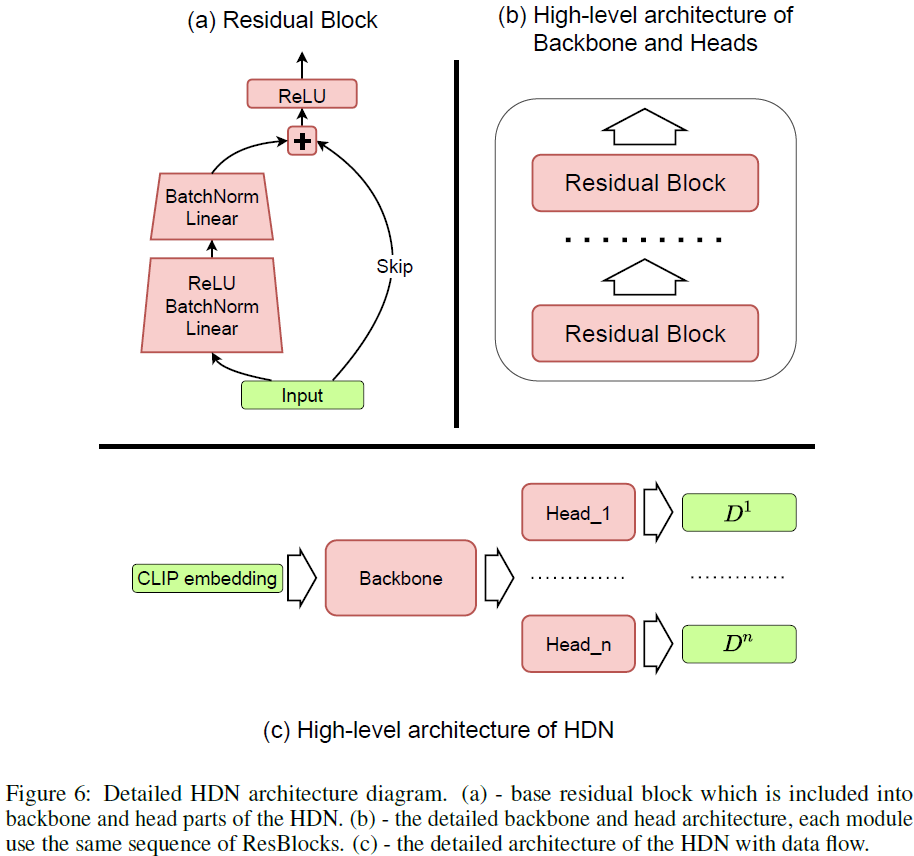
我们为 HDN 使用标准的类似 ResNet 的架构。它的主干部分有 10 个 ResBlocks 和由 17 个头组成的部分。头的数量等于合成网络 G_sys 中 StyleGAN2 层的数量。每个头有 5 个 ResBlocks 并输出相应 StyleGAN2 层的域向量。我们在图 6 中说明了 HDN 的总体架构。它有 43M 个参数。我们对所有实验使用相同的架构。
A.2.5 消融实验
我们对附录 A.2.1 中定义的 domain-norm 和 tt-direction 损失项进行定量和定性消融研究。

对于定性分析,我们考虑了 HyperDomainNet 的三个领域(动漫绘画、蒙娜丽莎绘画、浮世绘风格的绘画),该网络在 20 个不同的领域(参见附录 A.2.4 中的完整列表)进行了训练。 我们提供了这些域在 HyperDomainNet 训练损失中使用损失项的视觉比较(见图 7)。我们可以看到,如果没有额外的损失项,模型在每个域内都会显着崩溃。添加 domain-norm 后,它解决了域内崩溃的问题,但它开始将域相互混合,因此我们为不同的文本描述获得了相同的样式。在使用 tt-direction 损失后,我们最终可以在这些域上有效地训练 HyperDomainNet 而不会崩溃。
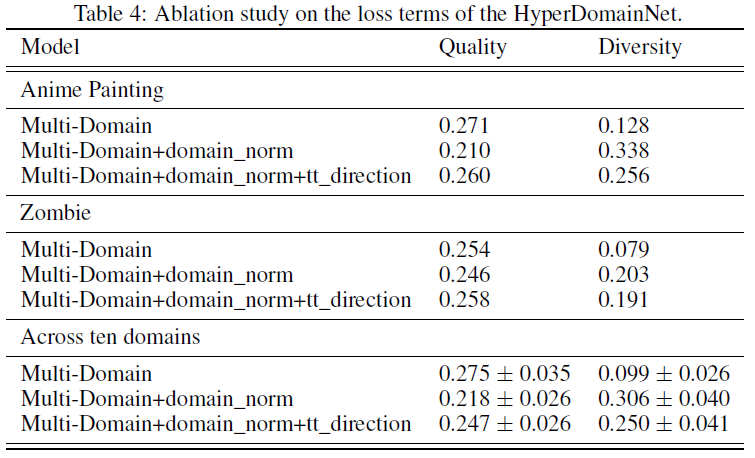
对于定量结果,我们使用附录 A.3.3 中介绍的指标质量和多样性。结果在表 4 中提供。我们看到没有损失项的初始模型获得了良好的质量,但多样性非常低。Domain-norm 显着提高了(降低质量的)多样性。tt-direction 在这两个指标之间提供了良好的平衡,我们也在图 7 中对其进行了定性分析。
A.2.7 对潜在任意数量域的训练
提高 HDN 的泛化能力具有挑战性,因为它倾向于在训练域上过度拟合,而对于未见过的域,它会预测非常接近训练域的域。解决这个问题的一种方法是大大扩展训练集。为此,我们使用了三种技术:(i)通过组合不同的训练域来生成许多训练域; (ii) 从初始训练 embedding 的凸包中采样 CLIP embedding; (iii) 在给定余弦相似性的情况下对初始 CLIP embedding 进行重采样(resampling)。 我们进一步讨论每种技术。
通过组合生成训练域。我们可以通过指示图像的不同属性来描述域,例如图像风格(例如印象派、波普艺术)、图像类型(例如照片、绘画)、艺术家风格(例如莫迪利亚尼)。我们还可以通过组合这些属性(例如莫迪利亚尼绘画、印象派照片)来构建新的领域。因此,我们采用 32 种图像样式、13 种图像类型和 7 位艺术家,通过采用这些属性的所有组合,我们得出了 1040 个域。
从凸包生成 CLIP embedding。在附录 A.2.4 中的 HDN 常规训练中,我们使用目标域的 CLIP embedding t_B1 = E_T (B1), ..., t_Bm = E_T (Bm)。为了覆盖更多的 CLIP 空间,我们建议使用来自初始的凸包 embedding 的新 embedding t'_B1, ..., t'_Bm:
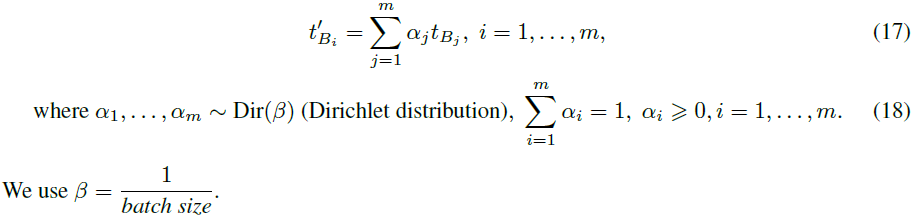
给定余弦相似度的初始 CLIP embedding 重采样。为了进一步扩展我们在 HDN 训练期间覆盖的 CLIP 空间,我们对受限于余弦相似度的目标域 t_B1, ..., t_Bm 的初始 CLIP embedding 重采样。因此,在从凸包生成之前,我们用新的 ^t_B1, ..., ^t_Bm 替换初始 embedding,使得 cos(t_B1,^tB1 ) = λ. 为了获得这些 embedding,我们使用以下操作:
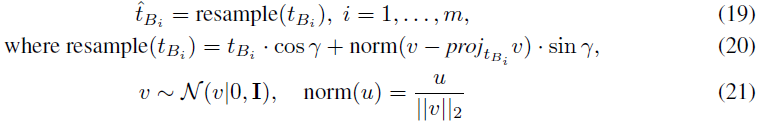
它允许我们覆盖初始凸包之外的 CLIP 空间部分。我们观察到它提高了 HDN 的泛化能力。
A.3 基于文本域自适应的结果
A.3.3 定量结果
我们通过以直接的方式评估“质量”和“多样性”指标来为基于文本的域适应提供定量比较。
作为“质量”指标,我们估计调整后的图像与目标域的文本描述的接近程度。也就是说,我们计算图像 CLIP embedding 和文本描述 embedding 之间的平均余弦相似度:

作为 E_I 编码器,我们仅使用在训练期间未应用的 ViT-L/14 图像编码器(在训练中我们使用 ViT-B/16、ViT-B/32 图像编码器)。
作为“多样性”指标,我们估计所有自适应图像之间的平均成对余弦距离:

结果在表 5 中提供。
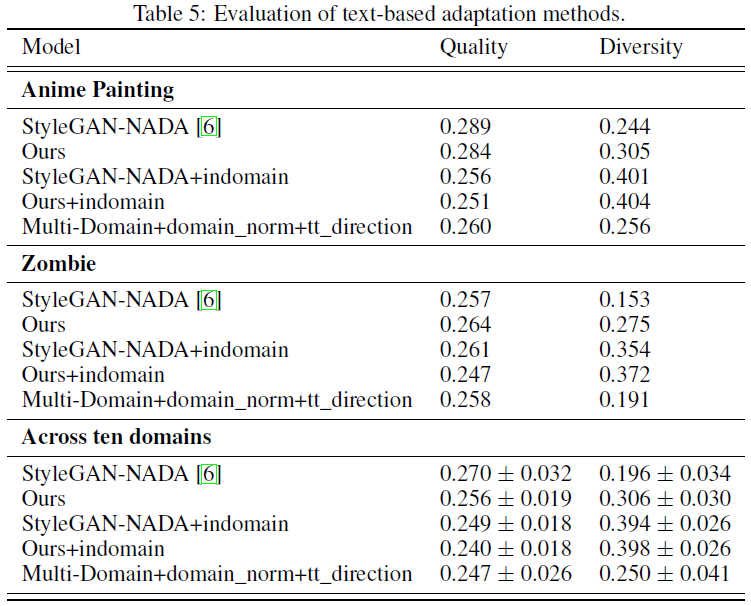
从这些结果中我们可以看出,我们的模型在质量方面与 StyleGAN-NADA 的表现相当,同时具有更好的多样性。我们还可以观察到,域内角度 loss 显着提高了 StyleGAN-NADA 和我们模型的多样性,同时略微降低了质量。
对于多领域适应模型,我们看到它具有比 StyleGAN-NADA 和我们的更低的多样性和可比的质量,同时适应所有这些领域。
总结
1. 核心思想
调制/解调背后的想法是将标准自适应实例归一化 (adaptive instance normalization,AdaIN) 替换为基于输入特征图的预期统计数据的归一化。因此,调制部分基本上是一种自适应缩放操作,就像在 AdaIN 中一样,由样式参数 s 控制。域调制流程如图 1 所示。
![]()
这个想法是只优化与样式参数 s 具有相同维度的向量 d。因此,我们只训练向量 d,而不是优化 StyleGAN 合成网络 G_sys 部分的所有权重 θ(d < θ)。该方法极大程度的减少了需要优化的参数。
我们的目标是,在给定输入目标域的情况下,学习可预测域参数 d = D(B) 的 HyperDomainNet D。
2. Training Loss
我们使用三个损失 L_direction(域自适应 loss)、L_tt-direction(提高多样性)和 L_domain-norm(提高多域自适应的多样性)来训练 HyperDomainNet D。
L_domain-norm:在机器学习中,添加正则化项的作用是为了防止样本数目过少时发生过拟合。在多域自适应时,因为目标域的样本数目较少,为了避免过拟合(目标域贴近),需要添加域参数 d = D(B) 的正则化项,从而使目标域相互远离,即,提高了目标域的多样性。
这里有一点我不理解。对于多域自适应,域参数 d 代表目标域的风格,而正则化项限制了域参数的大小。那么对于不同的域,它们的域参数的差别并不大,所以如何使目标域远离?这有点违反直觉,而作者也并未在文献中给出说明。
3. 泛化
提高 HDN 的泛化能力具有挑战性,因为它倾向于在训练域上过拟合:对于未见过的域,它会预测非常接近训练域的域。解决这个问题的一种方法是大大扩展训练集(Data Augmentation)。为此,我们使用了三种技术:
- 通过组合不同的训练域来生成许多训练域;
- 从初始训练 embedding 的凸包中采样 CLIP embedding;
- 在给定余弦相似性的情况下对初始 CLIP embedding 进行重采样(resampling)。

















 7359
7359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









