







GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
最近,扩散模型已被证明可以生成高质量的合成图像,特别是与引导技术结合使用时,可以在多样性和保真度之间进行权衡。 我们探索了文本条件图像合成问题的扩散模型,并比较了两种不同的引导策略:CLIP 引导和无分类器引导。 我们发现后者在逼真度和标题相似性方面受到人类评估者的青睐,并且通常会产生逼真样本。 来自使用无分类器指导的 35 亿参数文本条件扩散模型的样本比来自 DALL-E 的样本受到人类评估者的青睐,即使后者使用扩展的 CLIP 重排序。 此外,我们发现我们的模型可以进行微调以执行图像修复,从而实现强大的文本驱动图像编辑。 我们在过滤后的数据集上训练一个较小的模型,并在 https://github.com/openai/glide-text2im 上发布代码和权重。
1. 简介
图像(例如插图、绘画和照片)通常可以轻松地使用文本进行描述,但可能需要专门的技能和大量的劳动来创建。 因此,能够从自然语言生成逼真图像的工具可以使人类以前所未有的轻松方式创建丰富多样的视觉内容。 使用自然语言编辑图像的能力进一步允许迭代细化和细粒度控制,这两者对于现实世界的应用都至关重要。
最近的文本条件图像模型能够根据任意格式的文本提示合成图像,并且可以以语义上合理的方式组合不相关的对象(Xu 等人,2017;Zhu 等人,2019;Tao 等人,2020;Ramesh 等人,2021;张等人,2021)。 然而,他们还无法生成逼真的图像来捕获相应文本提示的所有方面。
另一方面,无条件图像模型可以合成逼真图像(Brock et al., 2018; Karras et al., 2019a;b; Razavi et al., 2019),有时具有足够的保真度,以至于人类无法将它们与真实图像区分开来(Zhou et al., 2019)。 在这一研究领域中,扩散模型(Sohl-Dickstein et al., 2015;Song & Ermon, 2020b)已成为一个有前景的生成模型系列,在许多图像生成基准中实现了最先进的样本质量 (Ho 等人,2020 年;Dhariwal 和 Nichol,2021 年;Ho 等人,2021 年)。
为了在类别条件设置中实现逼真,Dhariwal & Nichol (2021) 通过分类器指导增强了扩散模型,这种技术允许扩散模型以分类器的标签为条件。 首先在有噪图像上训练分类器,在扩散采样过程中,使用分类器的梯度将样本引导至标签。 Ho & Salimans (2021) 通过使用无分类器指导(一种在有标签和无标签的扩散模型的预测之间进行插值的指导形式),在没有单独训练的分类器的情况下取得了类似的结果。
受引导扩散模型生成逼真样本的能力和文本到图像模型处理任意形式提示的能力的启发,我们将引导扩散应用于文本条件图像合成问题。
- 首先,我们训练一个 35 亿参数扩散模型,该模型使用文本编码器以自然语言描述为条件。
- 接下来,我们比较两种将扩散模型引导至文本提示的技术:CLIP 引导和无分类器引导。
- 通过人工和自动评估,我们发现无分类器的指导可以产生更高质量的图像。
我们发现,在无分类器指导下生成的模型样本既逼真又反映了广泛的世界知识。 当由人类评委进行评估时,相比于 DALL-E(Ramesh 等人,2021)的样本,在照片真实性评估中,87% 的人选择我们的样本,而在字幕相似性评估中,69% 的人选择我们的样本。
虽然我们的模型可以零样本渲染各种文本提示,但它可能很难为复杂的提示生成逼真的图像。 因此,除了零样本生成之外,我们还为我们的模型提供了编辑功能,这使得人们能够迭代地改进模型样本,直到它们匹配更复杂的提示。 具体来说,我们微调模型以执行图像修复,发现它能够使用自然语言提示对现有图像进行真实的编辑。 模型生成的编辑与周围环境的风格和照明相匹配,包括令人信服的阴影和反射。 这些模型的未来应用可能会帮助人类以前所未有的速度和轻松创建引人注目的自定义图像。
我们观察到,我们得到的模型可以显着减少产生令人信服的虚假信息或 Deepfakes 所需的工作量。 为了防范这些用例,同时帮助未来的研究,我们发布了一个较小的扩散模型和一个在过滤数据集上训练的有噪 CLIP 模型。
我们将我们的系统称为 GLIDE,它表示用于生成和编辑的图像扩散的引导语言(Guided Language to Image Diffusion for Generation and Editing)。 我们将小型过滤模型称为(经过过滤的) GLIDE。
2. 背景
在以下部分中,我们概述了我们将评估的最终模型的组成部分:扩散、无分类器指导和 CLIP 指导。
2.1. 扩散模型
我们考虑 Sohl-Dickstein 等人 (2015) 引入并由 Song & Ermon (2020b) 、Ho 等人(2020)改进的高斯扩散模型。 给定数据分布 x0 ~ q(x0) 的样本,我们通过逐步向样本添加高斯噪声生成潜在变量 x1,...,xT 的马尔可夫链 :
![]()
如果每一步添加的噪声的幅度 1 - α_t 足够小,则后验
![]()
可以很好地用对角高斯近似。 此外,如果整个链中添加的总噪声的幅度 1 - α_1,..., α_T 足够大,则 xT 可以很好地近似为 N(0, I)。 这些属性建议我们学习模型
![]()
来近似真实的后验:
![]()
它可用于通过从高斯噪声 xT ~ N(0, I) 开始并在一系列步骤
![]()
中逐渐减少噪声来生成样本 x0 ~ p_θ(x0)。
虽然 log p_θ(x0) 上存在易于处理的变分下界(variational lower-bound,VLB),但优化替代目标(重新加权 VLB 中的各项)会产生更好的结果。 为了计算这个替代目标,我们通过将高斯噪声 ε 应用于 x0 来生成样本 xt ~ q(xt | x0),然后训练模型以使用标准均方误差损失来预测添加的噪声:
![]()
Ho 等人 (2020) 展示了如何从 ε_θ(xt, t) 导出 μ_θ(xt),并固定 Σ_θ 为常数。 他们还展示了与之前基于去噪评分匹配的模型的等价性(Song & Ermon,2020b;a),评分函数为
![]()
![]()
在后续工作中,Nichol & Dhariwal (2021) 提出了一种学习 Σ_θ 的策略,该策略使模型能够以更少的扩散步骤生成高质量的样本。 我们在本文中采用这种技术来训练模型。
扩散模型也已成功应用于图像超分辨率(Nichol & Dhariwal,2021;Saharia 等人,2021b)。 遵循扩散的标准公式,高分辨率图像 y0 在一系列步骤中逐渐被噪声化。 然而,
![]()
还以下采样输入 x 为条件,该输入 x 通过在通道维度中连接 x(双三次上采样)提供给模型。 这些模型的结果在 FID、IS 和人类比较分数方面优于先前的方法。
2.2. 引导的扩散
Dhariwal & Nichol (2021) 发现,类别条件扩散模型中的样本通常可以通过分类器指导进行改进,其中具有均值 μ_θ(xt | y) 和方差 Σ_θ(xt | y) 的类别条件扩散模型,会受到分类器预测的目标类 y 的对数概率 log p_Φ (y | xt) 的梯度的加性扰动。 由此产生的新扰动平均值 ^μ_θ(xt | y) 由下式给出
![]()
系数 s 称为引导尺度,Dhariwal & Nichol (2021) 发现,增加 s 可以提高样本质量,但会牺牲多样性。
2.3. 无分类器引导
Ho & Salimans (2021) 最近提出了无分类器指导,这是一种指导扩散模型的技术,不需要训练单独的分类器模型。 对于无分类器指导,在训练期间,类别条件扩散模型 ε_θ(xt | y) 中的标签 y 被替换为概率固定的空标签 Ø。 在采样期间,模型的输出沿着 ε_θ(xt | y) 的方向,远离 ε_θ(xt | Ø),如下所示:
![]()
这里 s ≥ 1 是指导尺度。 这种函数形式的灵感来自于隐式分类器
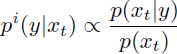
其梯度可以写成真实分数 ε*
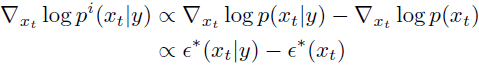
为了使用通用文本提示实现无分类器指导,我们有时在训练期间用空序列(我们也将其称为 Ø)替换文本标题。 然后,我们使用修改后的预测 ^ε 朝向标题 c 引导:
![]()
无分类器指导有两个吸引人的特性。 首先,它允许单个模型在指导过程中利用自己的知识,而不是依赖于单独的(有时更小的)分类模型的知识。 其次,当以分类器难预测的信息(例如文本)作为条件时,它简化了指导。
2.4. CLIP 引导
Radford 等人 (2021) 引入了 CLIP 作为学习文本和图像之间联合表示的可扩展方法。 CLIP 模型由两个独立的部分组成:图像编码器 f(x) 和标题编码器 g(c)。 在训练期间,从大型数据集中对 (x; c) 对进行批量采样,并且该模型优化对比交叉熵损失,如果图像 x 与给定的标题 c是配对的,则鼓励高点积 f(x)·g(c),或者如果图像和标题对应于训练数据中的不同对,则鼓励低点积。
由于 CLIP 提供了图像与标题的接近程度的分数,因此一些作品已使用它来引导 GAN 等生成模型转向用户定义的文本标题(Galatolo 等人,2021;Patashnik 等人,2021;Murdock, 2021 年;Gal 等人,2021 年)。 为了将相同的想法应用于扩散模型,我们可以在分类器指导中用 CLIP 模型替换分类器。 特别是,我们用对应于图像的、图像和标题的编码的点积的梯度,来扰动逆向过程均值:
![]()
与分类器引导类似,我们必须在噪声图像 xt 上训练 CLIP,以在反向过程中获得正确的梯度。 在整个实验中,我们使用经过明确训练的具有噪声感知能力的 CLIP 模型,我们将其称为噪声 CLIP 模型。
之前的工作 Crowson (2021a;b) 表明,尚未在噪声图像上进行训练的公共 CLIP 模型仍然可以用于指导扩散模型。 在附录 D 中,我们表明我们的噪声 CLIP 指导对这种方法表现良好,而不需要数据增强或感知损失等额外技巧。 我们假设使用公共 CLIP 模型的指导会对样本质量产生不利影响,因为采样过程中遇到的带噪声的中间图像对于模型来说是分布外的。
3. 相关工作
许多作品已经解决了文本条件图像生成的问题。
- Xu et al. (2017); Zhu et al. (2019); Tao et al. (2020); Zhang et al. (2021); Ye et al. (2021) 使用公开的图像标题数据集,以文本为条件来训练 GAN。
- Ramesh et al. (2021) 基于 van den Oord et al. (2017) 的方法,合成以文本为条件的图像,其中,在离散潜在代码之上训练一个自回归生成模型。
- 在我们工作的同时,Gu 等人 (2021) 在离散潜在代码之上训练文本条件离散扩散模型,发现所得系统可以产生有竞争力的图像样本。
有几部作品探索了利用扩散模型进行图像修复。
- Meng 等人(2021)发现扩散模型不仅可以修复图像的区域,而且可以根据图像的粗略草图(或一组颜色)来进行修复。
- Saharia 等人 (2021a) 发现,当直接在修复任务上进行训练时,扩散模型可以平滑地修复图像区域,而不会产生边缘伪影。
CLIP 被用来指导图像生成。
- Galatolo et al. (2021); Patashnik et al. (2021); Murdock (2021); Gal et al. (2021) 使用 CLIP 指导 GAN 朝向文本提示生成。 在线人工智能生成的艺术
- 在线人工智能生成的艺术社区利用无噪声 CLIP 引导扩散产生了有希望的早期结果(Crowson,2021a;b)。
- Kim & Ye (2021) 使用文本提示编辑图像,通过微调扩散模型以针对 CLIP 损失,同时重建原始图像的 DDIM (Song et al., 2020a) 潜在表示。
- Zhou 等人 (2021) 训练以扰动的 CLIP 图像嵌入为条件的 GAN 模型,从而产生一个可以以 CLIP 文本嵌入为条件的图像的模型。
- 这些作品都没有探索噪声 CLIP 模型,并且通常依赖于数据增强和感知损失。
有几部作品探索了基于文本的图像编辑。
- Zhang 等人 (2020) 提出了一种双重注意机制,用于使用文本嵌入来修复图像的缺失区域。
- Stap 等人 (2020) 提出了一种使用基于文本的特征向量编辑面部图像的方法。
- Bau 等人 (2021) 将 CLIP 与最先进的 GAN 模型配对,使用文本目标修复图像。
- 在我们工作的同时,Avrahami 等人 (2021) 以文本为条件,使用 CLIP 引导扩散来修复的图像区域。
4. 训练
对于我们的主要实验,我们训练了一个 64*64 分辨率的 35 亿参数文本条件扩散模型,以及另一个 15 亿参数的文本条件上采样扩散模型(将分辨率提高到 256*256)。 对于 CLIP 指导,我们还训练了一个带噪声的 64*64 ViT-L CLIP 模型(Dosovitskiy 等人,2020)。
4.1. 文本条件扩散模型
我们采用 Dhariwal & Nichol (2021) 提出的消融扩散模型 (ablated diffusion model,ADM)模型架构,但以文本为条件信息对其进行增强。 对于每个噪声图像 xt 和相应的文本标题 c,我们的模型预测 p(x_(t-1) | xt, c)。 为了以文本为条件,我们首先将其编码为 K 个标记序列,并将这些标记输入 Transformer 模型(Vaswani 等人,2017)。 该 Transformer 的输出有两种使用方式:首先,使用最终的标记嵌入来代替 ADM 模型中的类别嵌入; 其次,把最后一层 token 嵌入(K 个特征向量的序列)分别投影到整个 ADM 模型中每个注意力层的维度,然后连接到每个层的注意力上下文。
我们在与 DALL-E(Ramesh 等人,2021)相同的数据集上训练我们的模型。 我们使用与 Dhariwal & Nichol (2021) 的 ImageNet 64*64 模型相同的模型架构,但将模型宽度扩展到 512 个通道,从而为模型的视觉部分提供了大约 23 亿个参数。 对于文本编码 Transformer,我们使用 24 个宽度为 2048 的残差块,产生大约 12 亿个参数。
此外,我们还训练了一个 15 亿参数的上采样扩散模型,将分辨率从 64*64 提高到 256*256。 该模型以与基本模型相同的方式以文本为条件,但使用宽度为 1024 而不是 2048 的较小文本编码器。除此之外,该架构与 Dhariwal & Nichol (2021) 的 ImageNet 上采样器相匹配,只是我们将基本通道数增至 384 个。
我们以批量大小 2048 训练基本模型进行 250 万次迭代。我们以批量大小 512 训练上采样模型进行 160 万次迭代。我们发现这些模型以 16 位精度和传统损失缩放(traditional loss scaling)(Micikevicius 等人, 2017)进行稳定训练。 总训练计算量大致等于用于训练 DALL-E 的计算量。
4.2. 微调无分类器指导
初始训练后,我们对基本模型进行了微调以支持无条件图像生成。 此训练过程与预训练完全相同,只是 20% 的文本标记序列被替换为空序列。 这样,模型保留了生成文本条件输出的能力,但也可以无条件生成图像。
4.3. 图像修复
大多数之前使用扩散模型进行修复的工作都没有针对此任务明确训练扩散模型(Sohl-Dickstein 等人,2015;Song 等人,2020b;Meng 等人,2021)。 特别是,扩散模型修复可以通过像往常一样从扩散模型中采样来执行,但在每个采样步骤之后用来自 q(xt | x0) 的样本替换图像的已知区域。 这样做的缺点是模型在采样过程中无法看到整个上下文(只能看到它的噪声版本),有时会在我们的早期实验中导致不期望的边缘伪影。
为了获得更好的结果,我们明确地微调我们的模型以执行修复,类似于 Saharia 等人(2021a)。 在微调过程中,训练示例的随机区域被擦除,剩余部分与掩模通道一起作为附加条件信息输入到模型中。 我们修改模型架构以具有四个额外的输入通道:第二组 RGB 通道和一个掩模通道。 在微调之前,我们将这些新通道的相应输入权重初始化为零。 对于上采样模型,我们始终提供完整的低分辨率图像,但仅提供高分辨率图像的未遮蔽区域。
4.4. 有噪声的 CLIP 模型
为了更好地匹配 Dhariwal & Nichol (2021) 的分类器指导技术,我们使用图像编码器 f(xt, t) 训练噪声 CLIP 模型,该图像编码器接收噪声图像 xt ,并以与原始 CLIP 模型相同的目标进行训练。 我们以 64*64 分辨率训练这些模型,并使用与基本模型相同的噪声计划。
5. 结果
5.1. 定性结果


当在图 5 中直观地比较 CLIP 指导与无分类器指导时,我们发现来自无分类器指导的样本通常看起来比使用 CLIP 指导生成的样本更真实。 我们的其余样本是使用无分类器指导生成的,我们将在下一节中证明这一选择的合理性。


在图 1 中,我们观察到具有无分类器指导的 GLIDE 能够泛化到各种提示。 该模型通常会生成逼真的阴影和反射以及高质量的纹理。 它还能够生成各种风格的插图,例如特定艺术家或绘画的风格,或像素艺术等一般风格。 最后,该模型能够组合多个概念(例如柯基犬、领结和生日帽),同时将属性(例如颜色)绑定到这些对象。



在修复任务中,我们发现 GLIDE 可以使用文本提示真实地修改现有图像,并在必要时插入新对象、阴影和反射(图 2)。 该模型甚至可以在将对象编辑到绘画中时匹配样式。 我们还在图 4 中使用 SDEdit(Meng 等人,2021)进行实验,发现我们的模型能够将草图转换为逼真的图像编辑。 在图 3 中,我们展示了如何迭代地使用 GLIDE 通过零样本生成和一系列修复编辑来生成复杂的场景。
在图 5 中,我们将我们的模型与之前 MS-COCO 标题上的最先进文本条件图像生成模型进行比较,发现我们的模型无需 CLIP 重新排名或精心挑选就可以生成更真实的图像。
有关其他定性比较,请参阅附录 C、D、E。
5.2. 定量结果
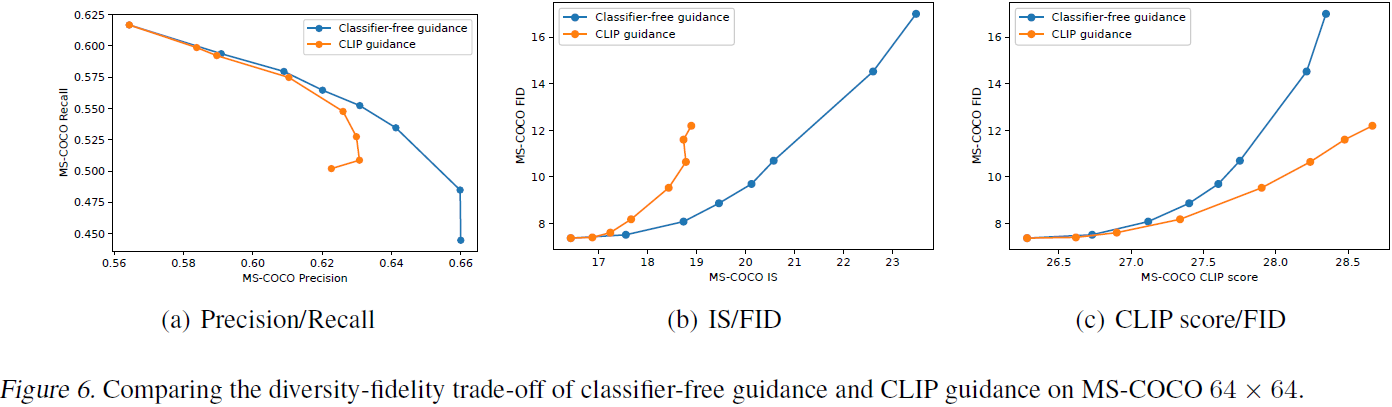
我们首先通过查看质量保真度权衡的帕累托前沿(Pareto frontier)来评估无分类器指导和 CLIP 指导之间的差异。 在图 6 中,我们评估了两种方法在 64*64 分辨率下的零样本 MS-COCO 生成。 我们研究了 Precision/Recall(Kynkàanniemi et al., 2019)、FID(Heusel et al., 2017)、Inception Score(Salimans et al., 2016)和 CLIP Score(标题与图像的嵌入的对齐程度)(Radford et al., 2021)。 当我们增加两个指导尺度时,我们观察到 FID 与 IS、Precision 与 Recall以及 CLIP 分数与 FID 之间的明显权衡。 在前两条曲线中,我们发现无分类器指导是(接近)Pareto 最优的。 当根据 FID 绘制 CLIP 分数时,我们看到了完全相反的趋势; 特别地,CLIP 指导似乎比无分类器指导更能提高 CLIP 分数。
我们假设 CLIP 指导正在寻找评估 CLIP 模型的对抗性示例,而不是在匹配提示时实际上优于无分类器指导。 为了验证这一假设,我们聘请了人类评估员来判断生成图像的样本质量。 在此设置中,人类评估者会看到两张 256*256 张图像,并且必须选择哪个样本 1) 更好地匹配给定的标题,或者 2) 看起来更逼真。 人类评估者还可能表明,两张图像都没有明显优于另一张,在这种情况下,两个模型都会获得一半的胜利。
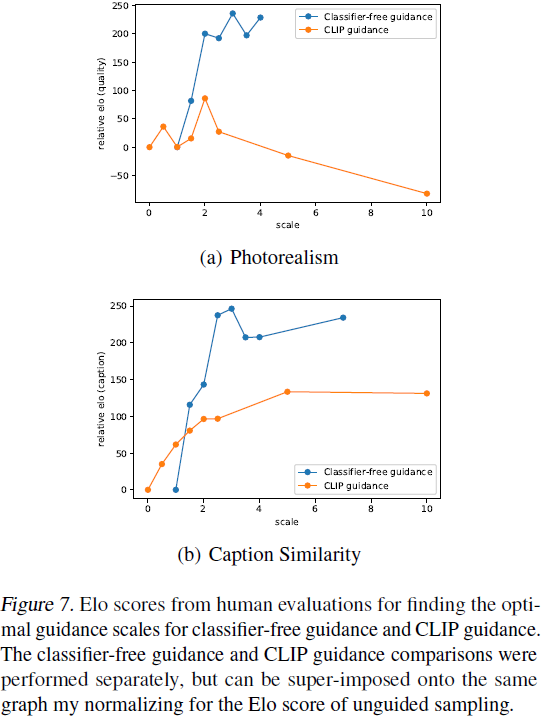
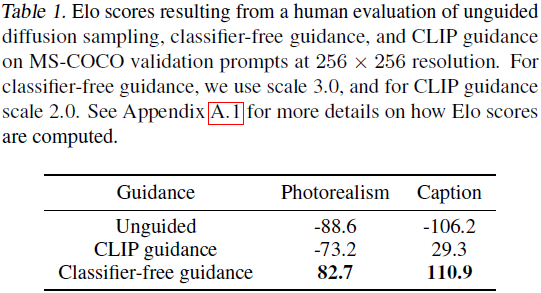
使用我们的人类评估协议,我们首先分别遍历两种方法的指导尺度(图 7),然后将这两种方法与前一阶段的最佳尺度进行比较(表 1)。 我们发现人类不认同 CLIP 评分,且无分类器的指导收获与相应提示更一致的更高质量的样本。
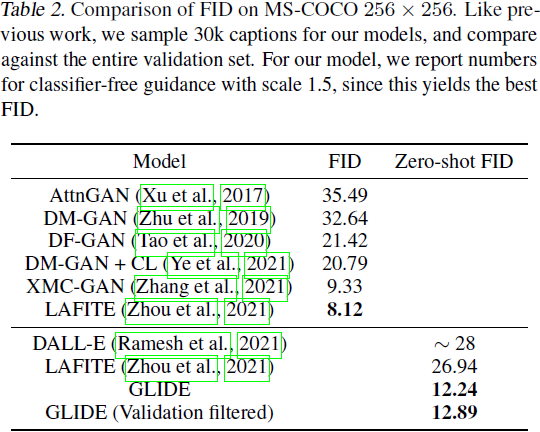
我们还将 GLIDE 与其他文本条件生成图像模型进行了比较。 我们在表 2 中发现,我们的模型在 MS-COCO 上获得了有竞争力的 FID,而无需在此数据集上进行明确的训练。 我们还根据 MS-COCO 验证集的子集计算 FID,该验证集已清除与训练集中的图像相似的所有图像,如 Ramesh 等人(2021)所做的那样,这将验证批次减少了 21%。 我们发现,在这种情况下,我们的 FID 从 12.24 略有增加到 12.89,这在很大程度上可以通过使用较小的参考批次时 FID 偏差的变化来解释。
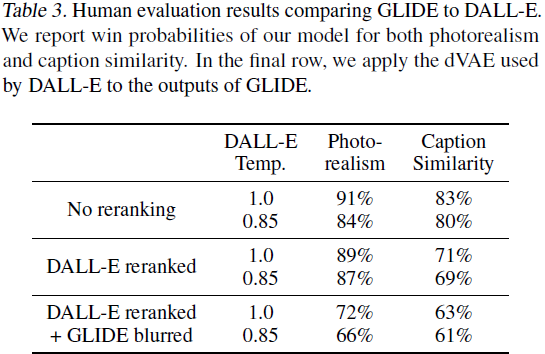
最后,我们使用人类评估协议将 GLIDE 与 DALL-E 进行比较(表 3)。 请注意,GLIDE 的训练计算量与 DALL-E 大致相同,但模型要小得多(35 亿个参数与 120 亿个参数)。 它还需要更少的采样延迟并且无需 CLIP 重新排名。
我们对 DALL-E 和 GLIDE 进行了三组比较。 首先,我们在不使用 CLIP 重新排名的情况下比较这两个模型。 其次,我们仅对 DALL-E 使用 CLIP 重新排名。 最后,我们对 DALL-E 使用 CLIP 重新排序,并通过 DALL-E 使用的离散 VAE 投影 GLIDE 样本。 后者使我们能够评估 DALLE 的模糊样本如何影响人类判断。 我们使用 DALL-E 模型的两个温度进行所有评估。 我们的模型在所有设置中都受到人类评估者的青睐,即使是在非常有利于 DALL-E 的配置中,因为允许 DALL-E 使用更大量的测试时间计算(通过 CLIP 重新排名),同时降低 GLIDE 样本质量(通过 VAE 模糊) )。
有关使用 CLIP 重新排序的 DALL-E 和使用各种指导策略的 GLIDE 的示例网格,请参阅附录 G。
6. 安全注意事项
我们的模型能够生成虚假但真实的图像,并使不熟练的用户能够快速对现有图像进行令人信服的编辑。 因此,在没有保障措施的情况下发布我们的模型将大大降低创建令人信服的虚假信息或 Deepfakes 所需的技能。 此外,由于该模型的样本反映了各种偏见,包括数据集中的偏见,因此应用它可能会无意中延续有害的社会偏见。
为了减轻发布这些模型的潜在有害影响,我们在训练模型发布之前过滤了训练图像。
- 首先,我们从互联网上收集了包含数亿图像的数据集,该数据集在很大程度上与用于训练 CLIP 和 DALL-E 的数据集脱节
- 然后对这些数据应用了多个过滤器。 我们过滤掉了包含人物的训练图像,以降低模型在许多以人为中心的有问题的用例中的能力。
- 我们还担心我们的模型被用来产生暴力图像和仇恨符号,因此我们也过滤掉了其中的几个。
- 有关我们的数据过滤过程的更多详细信息,请参阅附录 F.1。
我们在过滤后的数据集上训练了一个小型 3 亿参数模型,我们将其称为(经过过滤的) GLIDE。 然后,我们研究了如果模型权重是开源的,(经过过滤的)GLIDE如何降低误用的风险。
- 在这项调查过程中,我们使用一组对抗性提示对模型进行特别组合(red teaming),没有发现任何模型能够生成可识别的人类图像的实例,这表明我们的数据过滤器的假-负率(false-negative rate)足够低。
- 我们还探究了(经过过滤的)GLIDE 是否存在某些形式的偏差,发现它保留甚至可能放大数据集中的偏差。 例如,当被要求生成 “女孩玩具” 时,我们的模型会比提示 “男孩玩具” 生成更多的粉色玩具和毛绒动物。 另外,我们还发现,当提示 “宗教场所” 等通用文化意象时,我们的模型往往会强化西方的刻板印象。
- 我们还观察到,使用无分类器指导时,模型的偏差会被放大。
- 最后,虽然我们阻碍了模型生成特定类别图像的能力,但它保留了修复功能,其滥用潜力是进一步跨学科研究的重要领域。 详细示例和图像请参见附录 F.2。
上述调查研究了(经过过滤的)GLIDE 本身,但没有模型存在于真空中。 例如,通常可以组合多个模型以获得一组新的功能。
- 为了探讨这个问题,我们将(经过过滤的)GLIDE 替换为公开可用的 CLIP 引导扩散程序(Crowson,2021a),并研究了所得模型对的生成能力。
- 我们通常发现,虽然 CLIP 模型(在未经过滤的数据上进行训练)允许我们的模型产生一些可识别的面部表情或仇恨图像,但当与公开可用的 ImageNet 扩散模型配对时,相同的 CLIP 模型会产生大致相同质量的图像 。 更多详细信息,请参见附录 F.2。
为了进一步研究 CLIP 引导扩散,我们还训练并发布了在过滤数据集上训练的噪声 ViT-B CLIP 模型。 我们将用于训练(经过过滤的)GLIDE 的数据集与原始 CLIP 数据集的已过滤版本相结合。 为了特别组合这个模型,我们用它来指导(经过过滤的)GLIDE 和公共 64*64 ImageNet 模型。 根据我们尝试的提示,我们发现与现有公共 CLIP 模型生成的暴力图像或人物图像的质量相比,新的 CLIP 模型并没有显着提高此类图像的质量。
我们还测试了 GLIDE(过滤后)直接反刍(regurgitate)训练图像的能力。 在本实验中,我们对训练集中的 30K 提示图像进行了采样,并计算了每个生成图像与 CLIP 潜在空间中原始训练图像之间的距离。 然后我们检查距离最小的对。 该模型没有忠实地再现我们检查的任何对中的训练图像。
7. 局限性

虽然我们的模型通常可以以复杂的方式组成不同的概念,但它有时无法捕获描述极不寻常的对象或场景的某些提示。 在图 8 中,我们提供了这些失败案例的一些示例。
我们未经优化的模型需要 15 秒才能在单个 A100 GPU 上采样一张图像。 这比相关 GAN 方法的采样慢得多,后者在单次前向传递中生成图像,因此更适合在实时应用中使用。
参考
Nichol A, Dhariwal P, Ramesh A, et al. Glide: Towards photorealistic image generation and editing with text-guided diffusion models[J]. arXiv preprint arXiv:2112.10741, 2021.
S. 总结
S.1 主要贡献
本文提出 GLIDE,它表示,用于生成和编辑的图像扩散的引导语言(Guided Language to Image Diffusion for Generation and Editing)。使用消融扩散模型 (ablated diffusion model,ADM)架构,并以文本为条件信息对其进行增强。
比较了两种不同的引导策略:CLIP 引导和无分类器引导,后者在逼真度和标题相似性方面有更好的性能。
GLIDE 的样本比使用重排序策略的 DALL-E 的样本有更好的性能。
S.2 引导
分类器引导。这种技术允许扩散模型以分类器的标签为条件。首先在有噪图像上训练分类器,在扩散采样过程中,使用分类器的梯度将样本引导至标签。
无分类器引导。这是一种在有标签和无标签的扩散模型的预测之间进行插值的指导形式。
CLIP 引导。使用图像编码器和标题编码器,通过鼓励生成图像的嵌入与标题嵌入的高相似度来引导图像生成。

















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









