







目录
(2).LeetCode - 1741.查找每个员工花费的总时间
(1).LeetCode - 1795 每个产品在不同商店的价格
1.批量处理函数 - apply()
DataFrame和Series等对象需要执行批量处理操作时,可以借用apply()函数来实现。
apply()的核心功能是实现“批量”调度处理,至于批量做什么,由用户传入的函数决定(自定义或现成的函数)。函数传递给apply(),apply()会帮用户在DataFrame和Series等对象中(按行或按列)批量执行传入的函数。
def apply(
self,
func: AggFuncType,
axis: Axis = 0,
raw: bool = False,
result_type: Literal["expand", "reduce", "broadcast"] | None = None,
args=(),
by_row: Literal[False, "compat"] = "compat",
engine: Literal["python", "numba"] = "python",
engine_kwargs: dict[str, bool] | None = None,
**kwargs,
):参数
func
函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据 结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数 会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回
axis
axis 参数可提供的有两个,该参数默认为0,
0 表示函数处理的是每一列;
1 表示处理的是每一行
raw
bool 类型,
默认为 False;
False 表示把每一行或列作为 Series 传入函数中;
True 表示接受的是 ndarray 数据类型
result_type
这个参数可以是{'expand', 'reduce', 'broadcast', None}中的其中之一,默认为 None
当axis(轴)=1 时,这个参数才生效
* 'expand' : list-like results will be turned into columns.
类似列表的结果将会被转化为列
* 'reduce' : returns a Series if possible rather than expanding
list-like results. This is the opposite of 'expand'.
如果可能的话,返回一个Series,而不是展开类似列表的结果。这与“扩展”相反。
* 'broadcast' : results will be broadcast to the original shape
of the DataFrame, the original index and columns will be
retained.
结果将传播到DataFrame的原始形状,原始索引和列将被保留。
The default behaviour (None) depends on the return value of the
applied function: list-like results will be returned as a Series
of those. However if the apply function returns a Series these
are expanded to columns.
默认行为(None)取决于所应用函数的返回值:类似列表的结果将作为
这些结果的Series返回。但是,如果应用函数返回一个Series,
则这些Series将扩展为列。args
除了数组/序列之外,还要传递给“func”的额外参数
如: df.apply(lambda x: df[''] + a + b, axis=1, args=(2, 3))
by_row
False 或者 "compat", 默认为 "compat"
应用
(1).LeetCode - 1873.计算特殊奖金
def calculate_special_bonus(employees: pd.DataFrame) -> pd.DataFrame:
# 生成新的series
employees['bonus'] = employees.apply(
func=lambda x: x['salary'] if x['employee_id'] % 2 and not x['name'].startswith('M') else 0,
axis = 1
)
return employees[['employee_id','bonus']]2.分组函数groupby()
见名知意
def groupby(
self,
by=None,
axis: Axis | lib.NoDefault = lib.no_default,
level: IndexLabel | None = None,
as_index: bool = True,
sort: bool = True,
group_keys: bool = True,
observed: bool | lib.NoDefault = lib.no_default,
dropna: bool = True,
):
......
......
return DataFrameGroupBy(
obj=self,
keys=by,
axis=axis,
level=level,
as_index=as_index,
sort=sort,
group_keys=group_keys,
observed=observed,
dropna=dropna,
)该函数返回了一个DataFrameGroupBy对象
参数
by/ axis/ level/ as_index

axis
DataFrame.groupby中的“axis”关键字已弃用,并将在将来的版本中删除。
as_index
默认为True
Return object with group labels as the index.
返回以组标签作为索引的对象,若是希望以Dataframe表格的风格显示,则将其改成False
接下来在LeetCode题目中学习它的应用
应用
(1).LeetCode - 184.部门工资最高的员工
def department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:
# 左连接部门表
df = employee.merge(department, left_on='departmentId', right_on='id', how='left')
# 重命名
df.rename(columns={'name_x': 'Employee', 'name_y': 'Department', 'salary': 'Salary'}, inplace=True)
# 对部门ID分组,并获取Salary列,再使用transform函数获取该列的最大值
max_salary = df.groupby('Department')['Salary'].transform(func=max)
df = df[df['Salary'] == max_salary]
return df[['Department', 'Employee', 'Salary']]DataFrameGroupBy对象的transform方法
def transform(self, func, *args, engine=None, engine_kwargs=None, **kwargs):
可用于Series或DataFrame
其中func即为接收的处理函数;axis即为作用的轴向;另有*args和**kwargs用于接收func函数的可变长参数及字典参数。
此题transform函数处理了一个Series,处理函数为max,返回了该Series中的最大值
(2).LeetCode - 1741.查找每个员工花费的总时间
def total_time(employees: pd.DataFrame):
# 先计算出total_time列
employees['total_time'] = employees[['in_time', 'out_time']].apply(func=lambda x: x['out_time'] - x['in_time'], axis=1)
# 分组并求和
ans = employees.groupby(by=[ 'emp_id', 'event_day'], as_index=False).sum() # type:pd.DataFrame
# 重命名列名
return ans[['event_day', 'emp_id', 'total_time']].rename(columns={'event_day': 'day'})3.透视函数melt()
将Dataframe从宽格式"融化"为长格式
返回一个DataFrame对象
def melt(
self,
id_vars=None,
value_vars=None,
var_name=None,
value_name: Hashable = "value",
col_level: Level | None = None,
ignore_index: bool = True,
) -> DataFrame参数
id_vars
不进行重塑的列
value_vars
进行重塑的列。指定后会将该列重塑为两列,一是值全为列名的列,二是该列原本的值,如果不指定要重塑的列,则会默认为除id_vars之外所有的列
B variable value
1 --------> B 1
2 B 2
3 B 3
var_name
为variable指定列名(可选)
value_name
为value指定列名(可选)
col_level
当dataframe.columns为二维时使用这个参数,暂时不考虑
ignore_index
默认为True,保留原始索引(1, 2, 3, 4, 5);若为False,则索引值会重复(1, 2, 3, 1, 2 ,3)
应用
(1).LeetCode - 1795 每个产品在不同商店的价格
def rearrange_products_table(products: pd. DataFrame ) -> pd. DataFrame :
df = products.melt(id_vars=['product_id'], var_name='store', value_name='price')
df = df.dropna(axis=0)
return df
4.滚动窗口函数rolling()
DataFrame.rolling(window, min_periods=None,
center=False, win_type=None, on=None,
axis=_NoDefault.no_default, closed=None, step=None,
method='single')返回pandas.api.typing.Window对象或者pandas.api.typing.Rolling对象
如果传递了win_type,则返回 Window 的一个实例。否则,返回Rolling的一个实例。
参数
window
类型:int, timedelta, str, offset, 或者 BaseIndexer subclass
int : 固定窗口大小的观测数量n。相当于包括当前位置往前n个为一个窗口,如果当前位置往前的元素数量不够n个,那么进行聚合后的值就会为NaN
timedelta、str 或 offset : 表示每个窗口的时间段。每个窗口将是一个变量,其大小取决于时间段内包含的观察结果。这仅适用于日期时间类索引
axis
axis 关键字已弃用。对于axis = 'columns',请先转置 DataFrame
应用
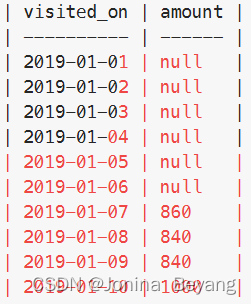
(1).LeetCode - 1321 餐馆营业额变化增长
import pandas as pd
def restaurant_growth(customer: pd.DataFrame) -> pd.DataFrame:
df1 = customer.groupby(['visited_on'])['amount'].sum()
df_amount = df1.rolling(window=7).sum().round(2).reset_index()
df_average_amount = df1.rolling(window=7).mean().round(2).reset_index()
ans = pd.merge(df_amount,df_average_amount, on='visited_on')
ans = ans.dropna().rename(columns={'amount_x': 'amount', 'amount_y': 'average_amount'})
return df_amount
这里单独打印一下df_amount,可以看到不够窗口长度的都显示为NaN















 4954
4954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









