









- Distributed Sampling-Based Model Predictive Control via Belief Propagation for Multi-Robot Formation Navigation
- RAL 2024.4
- Chao Jiang 美国 University of Wyoming
预备知识
马尔可夫随机场(Markov Random Field, MRF)
马尔可夫随机场(MRF)是用于建模多个随机变量之间相互依赖关系的概率图模型。具有以下特点:
- MRF通过无向图表示,节点代表随机变量,边表示变量之间的相互依赖关系。
- 每个节点的条件分布仅依赖于其邻居节点,而不依赖于其他节点。
- 其核心思想是通过局部相互作用来捕捉全局行为。
信念传播(Belief Propagation, BP)
信念传播是一种在图模型(如MRF)上进行推断的算法。它可以用于计算边缘概率分布或最大后验概率估计。主要有两种形式:
- 标准(BP):适用于树结构或无环图。在这些图中,BP可以精确地计算边缘概率分布。
- 循环(Loopy BP):适用于包含环的图。虽然在有环的图中BP不一定收敛或给出精确解,但在实践中它常常表现良好,能提供近似解。
步骤:
- 初始化:将每个节点的初始信念设置为其先验概率。
- 节点之间交换消息,包括关于一个节点的信念如何影响另一个节点。
- 边缘概率计算:通过聚合消息计算每个节点的边缘概率。
Q1 Background:本文试图解决一个什么样的问题?
- 具有复杂系统动力学和不确定性模型的随机最优控制问题
- 多机器人最优轨迹优化问题
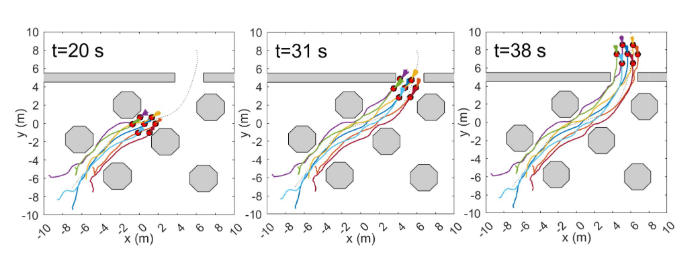
👉20x20的带有静态障碍物的方形环境。轮式机器人数量N=7。初始位置均匀随机分布在左下角的5×5m区域,初始航向从[0,2π)采样。
👉编队目标:使6个机器人将自己定位成正六边形,1个机器人位于编队中心。每个机器人与其最近邻居的距离为1.2m。最大通信范围dmax=1.5 m,最小机器人间距离dmin=0.6 m。最大控制vmax=1.2 m/s。
Q2 What’s Known:之前解决这个问题有哪些方法?
- 基于优化的方法:动态规划 | SCP | MPC
- 缺点:依赖梯度,需要计算导数,不太适合非光滑动力学或成本函数。随着函数的复杂性(例如,非凸性、局部极小值)的增加,这些方法可能变得低效,甚至无法找到可行解。使用基于梯度的优化的现有MPC方法在平滑优化问题中大多是成功的。
- 基于采样的方法:路径积分控制 | 交叉熵 | 信息论MPC | 变分推理MPC
- 定义:使用由前向预测或模拟产生的随机轨迹样本来实现最优控制。
- 优点:不依赖于模型的精确梯度的计算,接受更通用的动力学。随机前向搜索提供了一种解释不确定性的原则性方法,使算法不太容易出现局部极小值。
Q3 What’s New:本文是用什么样的方法如何解决这个问题的?
👉基于分布式采样的MPC算法:将多机器人最优控制公式化为图形模型上的概率推理(probabilistic inference over graphical model),并利用信念传播(leverages belief propagation通过分布式计算实现推理。可以产生基于采样的随机优化的各种分布式最优控制算法。
👉具体Method如下:
建模
-
Model:经典的轮式机器人 - 两轮驱动非完整Robot
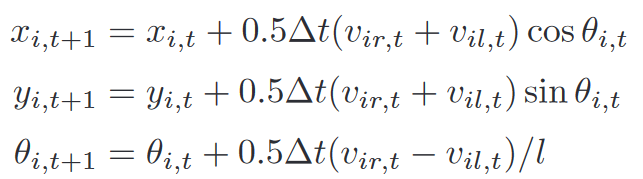
x x x, y y y是2D位置, θ \theta θ是航向角, v l v_l vl和 v r v_r vr代表左轮输入速度和右轮输入速度, l l l是左右轮距离 -
Proximity Graph
无向图,如果 i i i 和 j j j 的欧几里得距离 ≤ d m a x d_{max} dmax(通信范围限制),则 i i i, j j j存在边,且它们俩互为邻居。
所以边集是时变的: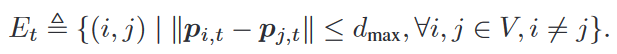
-
避碰和避障
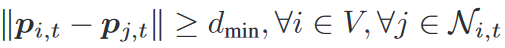
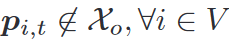
X o \mathcal{X}_o Xo是障碍物占用的位置(膨胀后) -
导航和编队保护
保持编队移动到目标位置,同时避碰
即跟踪参考轨迹 ∥ x i , t − x r , t ∥ , ∀ t ∈ [ 0 , T ] \|x_{i,t}-x_{r,t}\|,\forall t\in[0,T] ∥xi,t−xr,t∥,∀t∈[0,T],参考轨迹 x r , t x_{r,t} xr,t 通过全局运动规划器获得(环境图全局给定),编队由相对位置 Δ p i j \Delta p_{ij} Δpij确定,当所需编队保持不变时,以下等式成立:
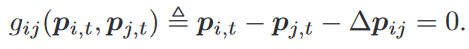
-
MPC轨迹优化问题
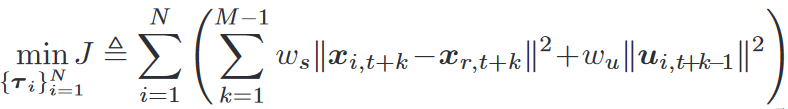
τ i ≜ { x i , t + k , u i , t + k } k = 0 M − 1 \tau_i\triangleq\{x_{i,t+k},u_{i,t+k}\}_{k=0}^{M-1} τi≜{xi,t+k,ui,t+k}k=0M−1是状态控制序列, N N N是智能体数量, M M M是控制时域
key:使用什么样的方法求解这个MPC轨迹优化问题
推理问题
- 目标:找到最优轨迹上的概率分布,从而找到每个机器人的最优控制。
- 概述:首先将多机器人团队建模为一个马尔可夫随机场(MRF)的概率图形模型,然后通过局部消息传递将信念传播(BP)用于分布式推理。最后,开发了一种基于采样的MPC算法来获得每个机器人的最优控制。
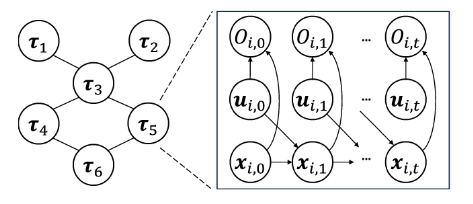
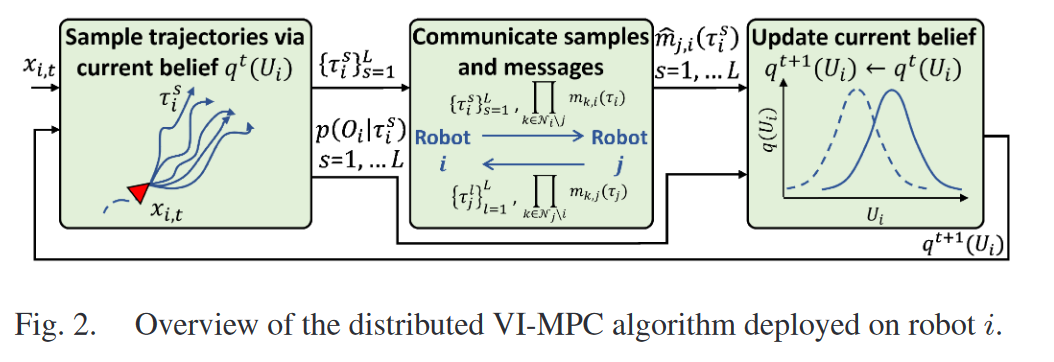
- 采样轨迹
输入: t t t时刻状态 x x x和当前的置信分布 q ( U ) q(U) q(U)
根据 q ( U ) q(U) q(U)对轨迹 τ \tau τ进行采样,得到 L L L个样本
计算每个样本轨迹的观测似然 p ( O ∣ τ ) p(O|\tau) p(O∣τ)- 传递样本轨迹和消息
i i i 发送轨迹样本给邻居 j j j,并接受邻居 j j j的轨迹样本
i i i 计算并传递消息 m k , i ( τ ) m_{k,i}(\tau) mk,i(τ)( i i i除了 j j j外的所有邻居 k k k对轨迹 τ i \tau_i τi的估计
i i i 接受 j j j 计算的消息( j j j除了 i i i外的所有邻居 k k k对轨迹 τ j \tau_j τj的估计- 更新当前置信分布
根据收到的所有邻居机器人的消息和当前时刻的观测信息更新当前的置信分布 q ( U ) q(U) q(U)

Q4 What’s the Contribution:本文还有什么其他的贡献吗?
- 主要贡献是完全分布式框架,每个机器人只需要局部信息。它将基于采样的优化方法[6]、[7]、[8]、[9]、[10]扩展到多机器人问题。
- 对比CMPC,计算速度快
- 对比基于ADMM求解的MPC,计算速度快且成功率高(分别为82%和98%)
Q5 What’s the Inspiration
- 模型比较常规,文章重点在于怎么求解问题,把基于采用的随机最优控制(变分推理)用到了求解DMPC问题中,核心思想还是每个机器人根据其他机器人的信息和自己的观测不断调整和优化自身的轨迹,达到全局最优的控制目标。
- 求解都比较数学,MRF和BP的地方没太看懂,这部分对我的工作没太大用处,但如果有人能看懂这个数学部分把他做到无人机再加个真机实验应该能写个好文章


















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









