







文章目录
为什么在cv中研究Transformer
研究背景
Transformer在CV领域刚开始崭露头脚,Transformer提出后在NLP方向取得良好成果,其全Attention结构,不仅增强了特征提取的能力,还保持了并行计算的特点,可以快速的完成NLP领域内多数任务,极大推动其发展。但是,几乎并未过多应用在CV方向。在此之前只有Obiect detection种的DETR大规模使用Transformer,其他包括Semantic Segmentation在内的领域并未实质性应用,纯粹Transformer结构的网络则是没有。
Transformer优势


1、并行运算;2、全局视野;3、灵活的堆叠能力
Transformer+classfiaction
ViT
原文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
ViT历史意义
1、展示了在CV中使用纯Transformer结构的可能
2、该领域开山之作
摘要
虽然Transformer体系结构已经成为自然语言处理任务的事实上的标准,但它在计算机视觉上的应用仍然有限。在视觉方面,注意力要么与卷积网络结合使用,要么用于替代卷积网络的某些组件,同时保持其整体结构不变。我们证明这种对cnn的依赖是不必要的,一个纯变压器直接应用于图像块序列可以很好地执行图像分类任务。在对大量数据进行预训练并将其传输到多个中小型图像识别基准(ImageNet、CIFAR-100、VTAB等)时,与最先进的卷积网络相比,Vision Transformer (ViT)获得了优异的结果,而训练所需的计算资源却大大减少。
摘要总结:1、Transformer在NLP中已经成为经典;2,在CV中,Attention机制只是作为一个补充在使用;3、我们使用纯Transformer结构就可以在图像分类任务上取得不错结果;4、在足够大的数据上训练后,ViT可以拿到和CNN的SODA不相上下的结果
ViT结构
核心思想:切分重排

Attention
核心思想:加权平均(计算相似度)

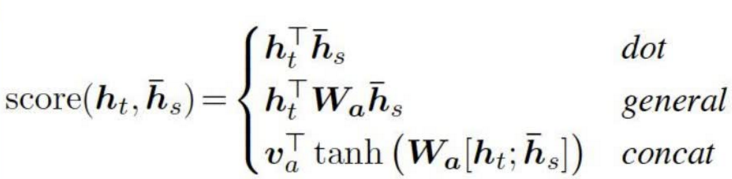
优点:1、并行运算;2、全局视野
MultiHead-Attention
核心思想:相似度计算,有多少W(Q,K,A)就重复运算多少次,结果concat一下
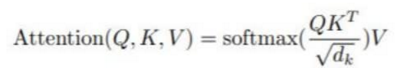
Q:query;K:key;V:Value

输入端适配
核心思想:直接把图片切分,然后编号输入网络
为什么有Patch0: ** 需要一个整合信息的向量**:如果只有原始输入的向量,会产生选取量的问题,即用哪个向量来分类都不好,全用计算量又很大,所以加入一个可学习的vector也就是Patch0来整合信息。
位置编码(Positional Encoding)
图像切分重排后失去了位置信息,并且Transformer的内部运算是空间信息无关的,所以需要把位置信息编码重新传进网络,ViT使用了一个可学习的vector来编码,编码vector和patch vector直接相加组成输入。
训练方法
大规模使用Pre-Train,先在大数据集上预训练,然后到小数据集上Fine Tune
迁移过去后,需要把原本的MLP Head换掉,换成对应类别数的FC层(和过去一样)
处理不同尺寸输入的时候需要对Positional Encoding的结果进行插值。
Attention距离和网络层数的关系
Attention的距离可以等价为Conv中的感受野大小 可以看到越深的层数,Attention跨越的距离越远 但是在最底层,也有的head可以覆盖到很远的距离 这说明他们确实在负责Global信息整合
论文总结
模型结构 ——Transformer Encoder
输入端适配——切分图片再重排
位置编码 ——可学习的vector来表示
纯Transformer做分类任务
简单的输入端适配即可使用
做了大量的实验揭示了纯
Transformer做CV的可能性。
















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











