






BBN: Bilateral-Branch Network with Cumulative Learningfor Long-Tailed Visual Recognition
重平衡的方式能通过调节分类器来达到令人满意的识别精度,但是也会一定程度上损失表征能力,因此作者提出BBN,兼顾特征学习和分类器学习,每个分支有自己独立的任务,并且有新的学习策略:先学习整体模式,然后逐渐关注尾部数据。
文章目录
- BBN: Bilateral-Branch Network with Cumulative Learningfor Long-Tailed Visual Recognition
- 1. Introduction
- 2. Related work
- 3. How class re-balancing strategies work?
- 4. Methodology
- 5. Experiments
- 总结
1. Introduction
介绍了作者的任务
-
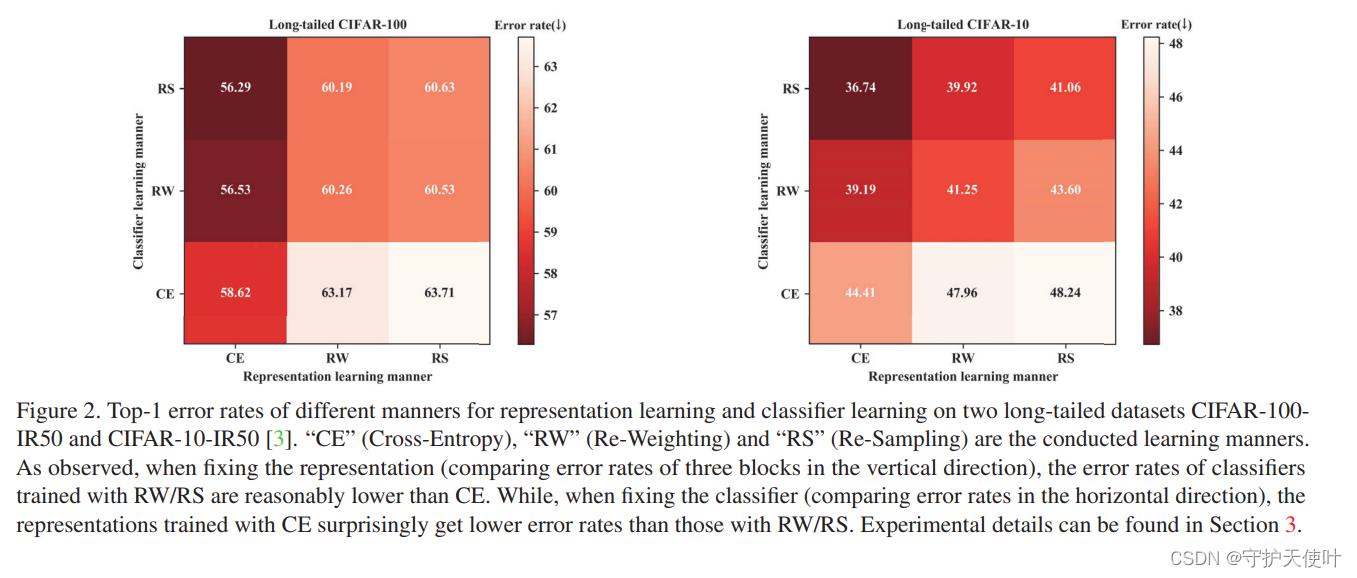
作者探求了类重平衡方法的机制,说明了这样的方法在促进分类器学习的同时也会影响到特征学习。下图中可以看出特征学习使用CE分类器学习使用RS时Error rate最低,如果在特征学习阶段使用类重平衡效果很差。
-
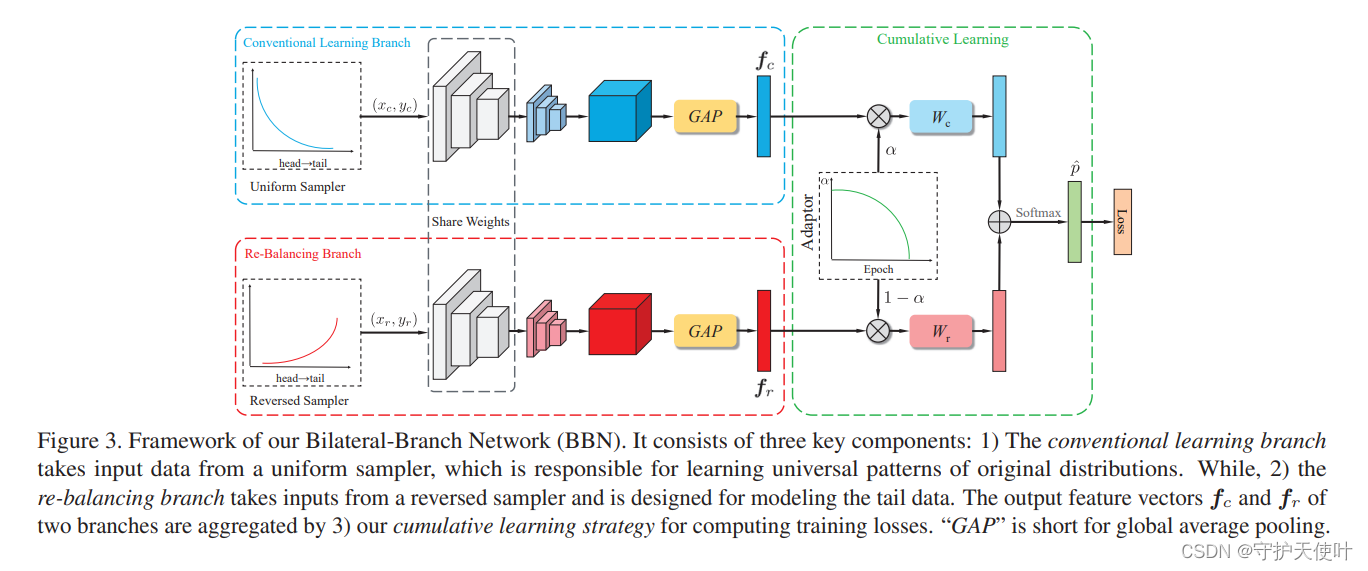
提出了BBN(Bilateral-Branch Network)进一步提高长尾识别的性能,提出一个新的cumulative learning策略来调整两条分支的学习,与BBN模型的训练结合。
Conventional Learning Branch用Uniform Sampler,Re-Balancing Branch用Reversed Sampler,两个分支通过CNN提取特征得到特征图,然后通过全局平均池化得到各自的特征向量,之后在Cumulative Learning通过一个参数 α \alpha α来平衡两者,得到最终用来预测的特征向量 p ^ \hat{p} p^。
-
做实验评估所提出的模型的性能。
2. Related work
介绍了常见的类重平衡技术、提到了其他相关方法。
介绍了一种数据增强:Mixup。
Class re-balancing strategies
重采样(Re-sampling):过采样少数类,重复增加少数类,会造成少数类过拟合;欠采样多数类,丢弃部分多数类,会造成特征的丢失,精度下降。
重加权(Re-weighting):损失函数中给尾部类训练样本更大的权重,但处理大规模真实世界的数据集时优化会变得很困难。因此有人提出了更有效的一个参数,而不是基于频数来重加权,还有LDAM。
另外还有两阶段的方式,第一阶段先用不平衡数据集训练,第二阶段在较低的学习率下微调。还有其他的处理长尾问题的例子,像度量学习、元学习、知识迁移学习。
Mixup
这是种数据增强的策略,将一对图像和标签结合起来生成新的样本。Manifold Mixup就是将Mixup应用到了Manifold特征空间的随机一对样本上。
3. How class re-balancing strategies work?
分析了重平衡策略的工作机制
将深度分类模型分类两个部分:特征提取器和分类器,深度分类网络的训练过程就分成了特征学习和分类器学习,类重平衡策略能使训练集分布接近测试集分布,更多关注尾部类,借此来提高分类精度。作者提出一个假设:类重平衡策略能促进分类器的学习,但是其歪曲了原始分布,可能会损害普遍特征的学习。
作者为了证明假设,用两阶段的实验方式学习特征和分类器,第一阶段用单纯训练方式和几种重平衡方式训练,得到不同方式下的特征提取器。第二阶段固定特征提取器的参数,用前面提到的几种方式分别训练分类器。然后通过控制变量法比较不同方式下特征提取和分类器的性能。
在cifar10和cifar100上实验,如图2所示
Classifier: RW/RS比用CE好
Representations: CE比RW/RS好
4. Methodology
介绍提出的BBN结构
4.1. Overall framework
BBN(Bilateral-Branch Network)有三部分组成:Conventional learning branch、re-balancing branch、cumulative learning。
两个branch使用相同的残差网络,除了最后一个残差块,别的地方都共享权重。Conventional learning branch用Uniform Sampler训练,得到的特征向量是
f
c
ϵ
R
D
f_c \epsilon \mathbb{R}^D
fcϵRD,其使用的分类器为
W
c
ϵ
R
D
×
C
W_c\epsilon \mathbb{R}^{D\times C}
WcϵRD×C;re-balancing branch用reversed samplers训练,得到的特征向量是
f
r
ϵ
R
D
f_r \epsilon \mathbb{R}^D
frϵRD,其使用的分类器为
W
r
ϵ
R
D
×
C
W_r\epsilon \mathbb{R}^{D\times C}
WrϵRD×C。
cumulative learning使用trade-off参数来控制两个特征向量
f
c
、
f
r
f_c、f_r
fc、fr的权重。加权之后的特征向量
α
f
c
、
(
1
−
α
)
f
r
\alpha f_c、(1-\alpha)f_r
αfc、(1−α)fr将被送入各自的分类器,两边得到的输出再按对应元素相加的方式整合到一起,得到最终的logit:
z
=
α
W
c
⊤
f
c
+
(
1
−
α
)
W
r
⊤
f
r
z = \alpha W_c^{\top} f_c + (1-\alpha) W_r^{\top} f_r
z=αWc⊤fc+(1−α)Wr⊤fr
用softmax计算预测概率:
p
i
^
=
e
z
i
∑
j
=
1
C
e
z
j
\hat{p_i} = \frac{e^{z_i}}{\sum_{j = 1}^{C} e^{z_j}}
pi^=∑j=1Cezjezi
若用
E
(
⋅
,
⋅
)
E(\cdot,\cdot)
E(⋅,⋅)来表示交叉熵损失函数,输出的概率分布为
p
^
=
[
p
1
^
,
p
2
^
,
.
.
.
,
p
C
^
]
⊤
\hat{p} = \left [ \hat{p_1}, \hat{p_2},...,\hat{p_C} \right ]^{\top}
p^=[p1^,p2^,...,pC^]⊤,则BBN模型的损失函数表示为:
L
=
α
E
(
p
^
,
y
c
)
+
(
1
−
α
)
E
(
p
^
,
y
r
)
\mathcal{L} = \alpha E(\hat{p},y_c) + (1-\alpha) E(\hat{p},y_r)
L=αE(p^,yc)+(1−α)E(p^,yr)
4.2. Proposed bilateral-branch structure
Data samplers.
conventional learning branch的训练数据来自uniform sampler,一个epoch中,训练集中的训练样本只会以同等概率采样一次,uniform sampler保留了原始分布的特征,因此有利于特征学习。re-balancing branch的训练数据来自reversed sampler,旨在缓解数据集的不平衡,提高分类精度。
reversed sampler方式,每个类的采样概率与样本大小的倒数成正比,某个类样本数越多,该类的采样概率越小。用
N
i
N_i
Ni表示
i
i
i类的样本数,
N
m
a
x
N_{max}
Nmax表示所有类的样本数,reversed sampler的步骤如下:
1)根据样本数计算类
i
i
i的采样概率
p
i
p_i
pi:
P
i
=
w
i
∑
j
=
1
C
w
j
P_i = \frac{w_i}{\sum_{j = 1}^C w_j}
Pi=∑j=1Cwjwi
其中
w
i
=
N
m
a
x
N
i
w_i = \frac{N_{max}}{N_i}
wi=NiNmax。
2)根据
P
i
P_i
Pi随机采样一个类。
3)从类
i
i
i中均匀得到一个样本。
重复上述采样过程,以得到一个mini-batch的训练数据。
Weights sharing.
BBN中用ResNet作为骨干网络,除了最后一个残差块,其他地方都共享权重,这样有两个好处:
1)conventional learning branch学得到的好的特征表示,利于re-balancing branch的学习。
2)能减少推断阶段的计算。
4.3. Proposed cumulative learning strategy
Cumulative learning能控制两个分支生成的特征向量的权重和分类损失,从而在两个分支之间转移关注点,这个组件会使得模型首先学习整体特征,然后逐渐关注尾部类特征。用一个参数
α
\alpha
α乘特征
f
c
f_c
fc,用
1
−
α
1-\alpha
1−α乘特征
f
r
f_r
fr,参数
α
\alpha
α与epoch有关,用
T
m
a
x
T_{max}
Tmax表示总共训练的epoch数,用
T
T
T表示当前的epoch,则参数
α
\alpha
α可表示为:
α
=
1
−
(
T
T
m
a
x
)
2
\alpha = 1- \left( \frac{T}{T_{max}} \right)^2
α=1−(TmaxT)2
能看出随着训练的进行,
α
\alpha
α逐渐减小,训练的关注点逐渐从conventional learning转移到re-balancing learning,逐渐从特征学习转向分类器的学习。
不同于两阶段微调分类器的策略,参数
α
\alpha
α能使得在整个训练过程中,处理不同任务的两个分支都能不断地更新,能避免训练一个目标时影响另一个目标。
4.4. Inference phase
推断阶段,把测试样本分别送入两个branch,得到两个特征向量 f c ′ 、 f r ′ f'_c、f'_r fc′、fr′,将参数 α \alpha α设置成0.5,然后对两个特征做加权处理后送入各自的分类器,得到两个logit,元素对应相加后得到最终logit,然后归一,得出分类概率。
5. Experiments
介绍一下实验设置和结果
5.1. Datasets and empirical settings
Long-tailed CIFAR-10 and CIFAR-100. CIFAR-10 和 CIFAR-100,各自包含60000张图片,50000张用来训练,10000张用来测试。使用长尾的版本,用不平衡因子 β \beta β是最多样本数比最少样本数,来描述长尾的不平衡程度, β = N m a x N m i n \beta = \frac{N_{max}}{N_{min}} β=NminNmax,实验中我们用到的不平衡因子是10、50、100。
iNaturalist 2017 and iNaturalist 2018. 这两个数据集时真实世界中极度不平衡的大规模数据集。iNaturalist 2017包含了579184张图片,有5089个类别;iNaturalist 2018包含了473513张图片,有8142个类别。iNaturalist数据集除了极度不平衡之外,还面临着细粒度分类的问题。(coarse-grained classification是粗粒度分类,是猫还是狗;fine-grained是类内细分,狗是拉布拉多还是边牧。)
5.2. Implementation details
Implementation details on CIFAR. 对于长尾数据集CIFAR-10 和 CIFAR-100,我们应用一种数据增强策略:从原始图像或其水平翻转中随机裁剪一个32 × 32的块,每边填充4像素。使用ResNet-32作为骨干网络,使用标准的随机梯度下降算法,momentum设置为 0.9 0.9 0.9,权重衰减为 2 × 1 0 − 4 2 \times10^{-4} 2×10−4。模型在单卡NVIDIA 1080Ti GPU上训练200轮,batch大小设置为128。初始学习率为 0.1 0.1 0.1。前5个epoch学习率使用线性warm-up的方案,在第120轮和第160轮的时候衰减0.01。
Implementation details on iNaturalist. 为了公平比较,2017和2018两个版本的数据集上我们都使用ResNet-50作为骨干网络,使用相同的训练策略,batch大小为128,在四个NVIDIA 1080Ti GPU上训练。首先将较短的边设置为256来调节图片尺寸,然后从图片或其水平翻转上裁剪一个 224 × 224 224\times224 224×224的块。训练过程中,学习率在60轮和80轮的时候衰减0.1。
5.3. comparison methods
实验中,我们将BBN方法与三种方法做比较
- Baseline methods. 用纯粹的交叉熵损失和focal损失训练。注意,为了作比较,也使用了一系列mixup算法。
- Two-stage fine-tuning strategies. 为了证实cumulative learning strategy的有效性,我们也和Two-stage fine-tuning strategies做了比较。第一阶段用CE在不平衡数据集上训练,第二阶段用class re-balancing的方式训练。CE-DRW和CE-DRS分别指的是第二阶段用re-weighting和re-sampling的两阶段方法的Baseline。
- State-of-the-art methods. 对于SOTA的方式,我们与LDAM和CB-Focal比较
5.4. Main results
5.4.1 Experimental results on long-tailed CIFAR
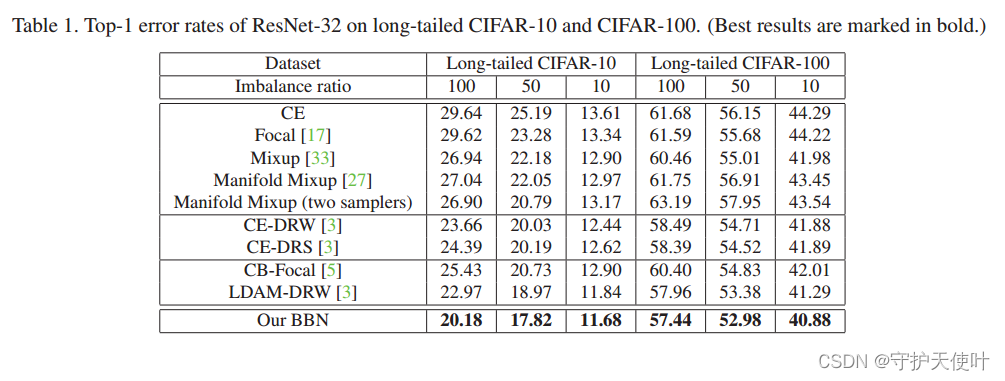
用三种不同的学习率10,50,100,在长尾CIFAR数据集上做多组实验。表1展示了多种方法的error rate。在和其他方法比较的时候,在所有数据集上,BBN达到的都是最好的效果。
5.4.2 Experimental results on iNaturalist
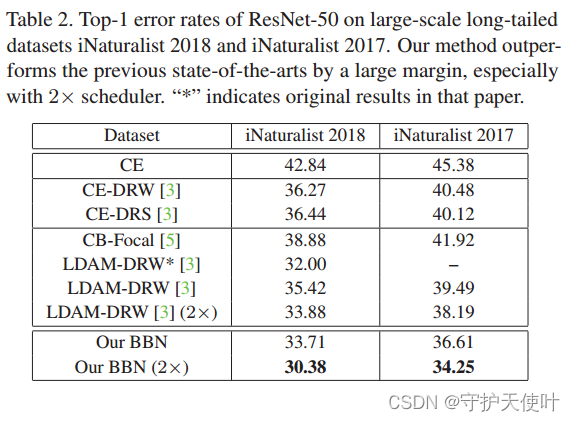
表2展示了在iNaturalist 2017 and iNaturalist 2018上的结果,BBN依旧很牛。BBN用2个scheduler,比不用好。
5.5. Ablation studies
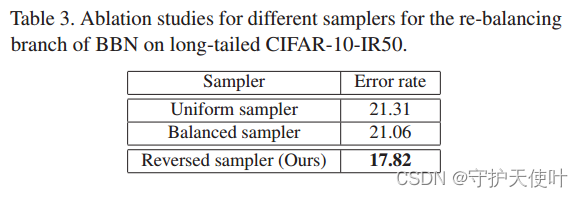
5.5.1 Different samplers for the re-balancing branch
为了更好的理解BBN,我们在re-balancing branch上用不同的采样器进行实验。表3是用不同采样器训练的error rate。
uniform sampler保留了和原始长尾数据集一样的分布;balanced sampler每个类被采样的概率是相同的,每个mini-batch都是平衡的标签分布。从表中可以看出,我们提出的reserved sampler比uniform和balanced的效果要好,这表明BBN方式通过reserved sampler给了尾部类很多关注。
5.5.2 Different cumulative learning strategy
为了促进理解我们提出的cumulative learning strategy,我们在数据集CIFAR-10-IR50上,用不同策略来生成trade-off参数
α
\alpha
α。
我们测试了
α
\alpha
α的产生与过程相关/不相关的策略,如表5所示。与过程相关:通过训练epoch数调整
α
\alpha
α,如线性衰减,余弦衰减。与过程无关策略:用相等的权重,或者从离散分布中产生(例如
β
\beta
β分布,该分布在一个数周围延两边递减)。

表4能看出,三种衰减策略比其他策略效果好,这能证明我们的motivation:先学习conventional learning branch,再学习re-balancing branch。
α
\alpha
α沿抛物线增加(conventional learning之前就re-balancing)性能最差,这也从另一方面印证了我们的motivation。
5.6 Validation experiments of our proposals
5.6.1 Evaluations of feature quality
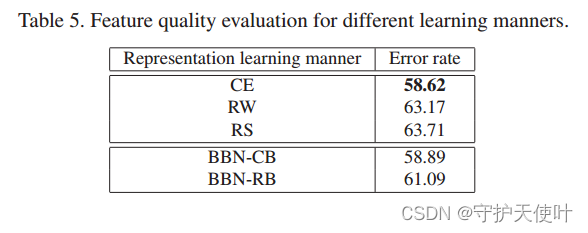
Section3已经证实,在长尾数据分布上用纯粹的CE训练能得到好的特征表示。这一节通过按照Section3的实验设置,来探索BBN特征表示的性能。
先在CIFAR-100-IR50上训练BBN,固定两个branch学习的参数,然后在CIFAR-100-IR50上分开训练两个branch各自的分类器,最后分别测试两个branch的error rate。
如表5所示,conventional learning branch得到的representations和用纯粹用CE训练的差不多,这表明BBN极大保留了从长尾数据集上学来的表征能力。注意:re-balancing branch比RW/RS效果更好可能因为BBN两个branch有一部分共享参数。
5.6.2 Visualization of classifier weights
之前有人发现,分类器权重的
ℓ
2
\ell_2
ℓ2-norm能表现分类的偏向,如:某个类的分类器权重的
ℓ
2
\ell_2
ℓ2-norm越大,则越偏向于把样本分到该类。作者可视化了在CIFAR-10-IR50数据集上训练的10个类分类器的
ℓ
2
\ell_2
ℓ2-norm,如图4所示。包含了conventional learning branch分类器的权重(BBN-CB)、re-balancing branch分类器的权重(BBN-RB)、两个branch结合后的权重(BBN-ALL),另外还有CE、RW、RS方式下训练的分类器权重。
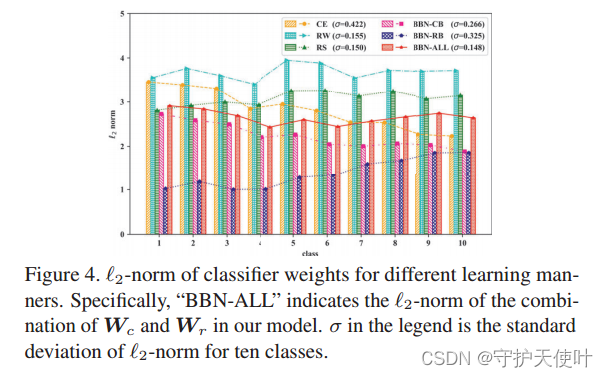
显然,BBN-ALL的各类
ℓ
2
\ell_2
ℓ2-norm基本相等,且标准差最小,
σ
=
0.148
\sigma = 0.148
σ=0.148。CE的
ℓ
2
\ell_2
ℓ2-norm分布和长尾分布一致。RW/RS的
ℓ
2
\ell_2
ℓ2-norm分布看起来较平坦,但方差比BBN-ALL的大。BBN-CB和CE的
ℓ
2
\ell_2
ℓ2-norm分布相似,这也能证明BBN-CB的任务是学习普遍特征,BBN-RB的
ℓ
2
\ell_2
ℓ2-norm分布和原始的长尾分布相反,也能表明他能关注到尾部类。















 1600
1600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









