







1. DenseNet 网络介绍
本章实现的项目是DenseNet 网络对花数据集的五分类,下载链接:
DenseNet 网络是在 ResNet 网络上的改进,大概的网络结构如下:

1.1 卷积的简单介绍
图像识别任务主要利用神经网络对图像进行特征提取,最后通过全连接层将特征和分类个数进行映射。传统的网络是利用线性网络对图像进行分类,然而图像信息是二维的,一般来说,图像像素点和周围邻域像素点相关。而线性分类网络将图像强行展平成一维,不仅仅忽略了图像的空间信息,而全连接层会大大增加网络的参数

为了更好把握图像像素的空间信息,提出了 CNN 卷积神经网络,利用卷积核(滤波器)对图像进行窗口化类似处理,这样可以更好的把握图像的空间信息。

这里定义两个名词:
1. 空间信息是指图像的宽高
2. 语义信息是类似手、脚一类图像本身具体的信息,神经网络中在 channel 中表现
CNN 卷积神经网络一般处理流程,将图像的宽高缩减,增加图像的channel 信息。这是因为我们往往更在乎图像的语义信息,所以正常神经网络都是将图像 size 缩半,channel 翻倍,一个通道提取一个语义,尺寸缩半是因为最大池化层之类的操作,可以增加网络的抗干扰能力。例如经典的VGG 网络就是每一层特征图size减半,channel 翻倍

如果想要提取更多的语义信息,就代表 channel 要更多
而网络的层数代表语义的高低之分,加入第一层可以每个channel 提取耳朵、鼻子。那么网络层数越深,提取的语义更高级,例如第二层每个channel 提取到狗的鼻子、猫的耳朵。所以,网络层数的多少代表能提取多么 "高级" 的语义信息
例如下图:浅层特征图提取的是边缘信息,深层的特征图可能是汽车的车牌啊、车轮啊啥的

网络的加宽,代表增加 channel 个数,提取更多特征
网络的加深,代表增加网络层数,提取更高级的语义信息
1.2 网络加宽、加深的危害
那么网络是不是越深越好?或者说网络宽度,channel 个数是不是越多越好?
答案是否定的,要不然早就有统一的网络可以实现图像识别的统一
网络层数越多、通道越多,网络会很繁重,参数的增多代表每次运行需要计算的量越大。虽然现在硬件的发展这点的影响越来越低,不过我们还是强调网络参数的多少
除了计算量大外,网络训练需要反向传播(矩阵反向传播:聊聊关于矩阵反向传播的梯度计算、从零实现反向传播:手动完成反向传播的多层线性网络对sin的回归)
反向传播每次的梯度发生一点改变,在更深的网络中会发生雪崩效应。例如1.2 好多层乘在一起,数字会越来愈大,如果0.2的话,好多层乘在一起,梯度几乎就变成0了,参数没法训练,网络也失去了意义,更多说还要乘更小的学习率了。前者叫梯度爆炸,后者叫梯度消失
1.3 ResNet 和 DenseNet
为了解决梯度爆炸或者梯度消失的问题,resnet 提出了resnet残差块结构,如下:

ResNet 中提出了 shortcut 结构,将上层的特征和本层特征融合,这样上层提取的浅层语义信息和高维的语义信息相加。这样网络理论上可以叠加的无限深!
关于网络层数的加深,这里有两种解释:
- 浅层的语义信息和高纬度的信息一直叠加,这样但凡网络有无限层,哪怕图像的语义信息已经没有全是0了,这样低维度的信息还在(例如浅层语义信息为1,高纬度的语义信息没有,为0,这样1+0=0,还是可以保存浅层的信息),哪怕后续的层数全被浪费掉,浅层的信息还在不是吗?
- 因为shortcut 结构的存在,反向梯度的传播可以不用乘上很小的梯度,直接反向传递到上一层,这样梯度消失的问题也解决了,所以网络理论上可以增加无限深
有些人任务resnet 的成功就是 shortcut 的存在让网络可以成功反向传播,让网络可以训练的 "动"
不过,本人觉得第一种可以更好解释resnet为什么可以提取到更好的特征,也可以解释为什么resnet 的效果如此优越
OK,网络的加深的问题解决了,那么网络的宽度,也就是卷积核的个数如何设定?
这样没有标准,所以不少消融试验就是验证不同 channel 个数来找到最好的参数设定
那么如果不仅仅融合上一层的信息,而是将前面浅层全部融合会怎么样呢?
这就是DenseNet 的由来,密集连接
2. DenseNet 网络的使用
代码就不解释了
本章是DenseNet 网络对于数据集花的五分类:基于迁移学习的 DenseNet 图像分类项目
代码的使用很简单,只需要将数据集按照如下摆放即可,不需要更改任何参数。例如train和predict 中的分类个数啊,代码会自动生成,并且类别标签的 json 文件也会自动生成

结果展示:

可以看到,迁移学习下,精度达到了0.9 左右,比之前的resnet还是高很多的
训练过程展示:

混淆矩阵:


训练的超参数更改:
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--lrf', type=float, default=0.01)
parser.add_argument('--freeze-layers', type=bool, default=False) # 是否冻结权重
关于项目的其他问题:详细见README文件

3. 关于数据集
项目的迁移,关于如何利用自定义数据集进行训练
3.1 图像损坏问题
因为有的图像损坏,代码会报警告,这里提供代码进行移除
注意,需要自己建立 corrupt_image 文件,和data在同一目录即可,代码会将data下损坏的图像移除,保存在 corrupt_image 文件中
from PIL import Image
import os
import shutil
import warnings # 将图片损坏信息转为错误
warnings.filterwarnings("error", category=UserWarning)
def main():
# 训练集
path = 'data/train'
path_dir = [os.path.join(path, x) for x in os.listdir(path)]
image_list = [] # 所有图片
for i in path_dir:
for j in os.listdir(i):
image = os.path.join(i,j)
image_list.append(image)
for i in image_list: # 遍历图片
try:
Image.open(i)
except:
print('corrupt img', i)
shutil.move(i, 'corrupt_image')
# 测试集
path = 'data/test'
path_dir = [os.path.join(path, x) for x in os.listdir(path)]
image_list = [] # 所有图片
for i in path_dir:
for j in os.listdir(i):
image = os.path.join(i,j)
image_list.append(image)
for i in image_list: # 遍历图片
try:
Image.open(i)
except IOError:
print('corrupt img', i)
shutil.move(i, 'corrupt_image')
if __name__ == '__main__':
main()
3.2 划分好的数据集
只需要按照下述摆放即可,文件名不可更改!!只需要将train或者test下的子文件夹改成自己数据集的名称即可
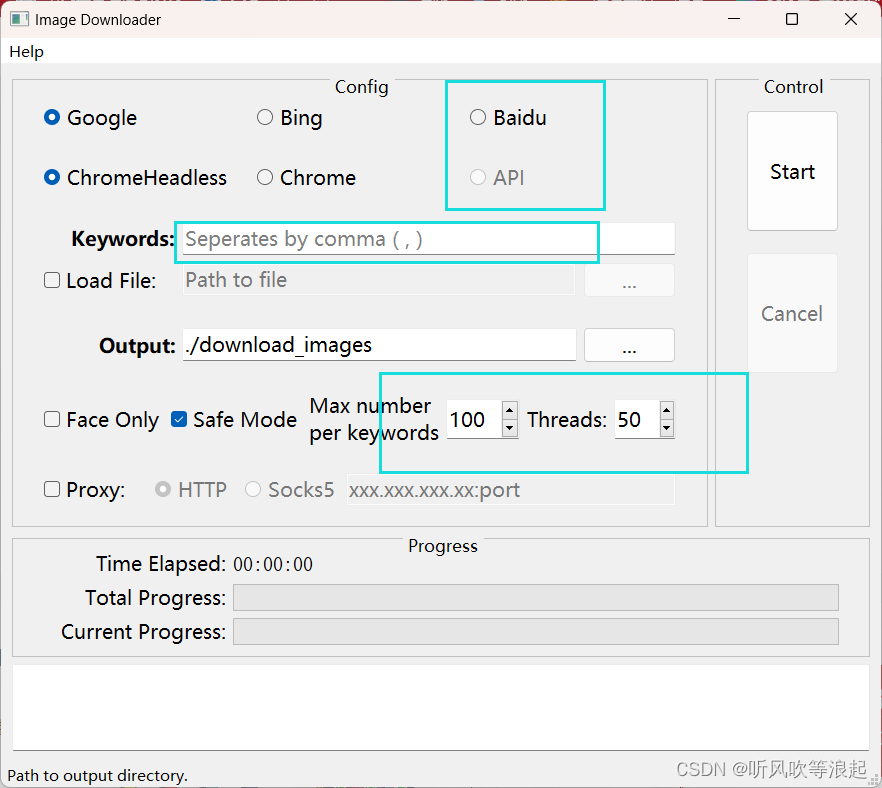
3.3 爬取图片
展示如下:
选中 Baidu API ,将keywords 改成想要下载的就行,Max number为下载个数,Threads 最好设定小一点,否则可能会下载数目不到Max number
代码会自动在该目录下生成 Keywords 目录,下面是 Max number 个Keywords 图像
这里对明星分类展示:



额,老薛好像分类错了....
4. 链接
详细信息看 README 文件
如果只想单纯的跑通DenseNet 网络,下载这个:基于迁移学习的 DenseNet 图像分类项目
如果没有数据集,需要脚本抓取网络关键词图像,看这个:python 项目:利用爬虫抓取特定关键字图片代码,可以用作深度学习图像分类的数据集
如果已经用了数据集,且按照文件夹摆放好,但不知道图像是否损坏,看这个:
DenseNet 对网络爬取的数据集进行分类,包含对图片是否损坏的检测
如果什么都没有,想自己搞个分类网络玩玩,看这个:DenseNet 网络对自定义数据集的训练(从网络download图片开始到划分训练集+测试集,再到网络训练的完整项目)
这个只需要在UI窗口输入关键词即可,脚本会自动抓取网络图片。因为中文爬取的效果好,只需要将文件夹重新改为英文即可,图像是否损坏啊,数据集划分啊,数据集摆放啊,代码会一键运行。至于分类个数,train、predict 脚本是否更改都是完全不需要的,代码会自动生成!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











