







 本文介绍了如何使用Python脚本下载、解压和批量裁剪CHIRPS全球降雨数据,涉及IDM下载工具、文件管理与解压缩,以及GDAL库进行地理空间数据处理。
本文介绍了如何使用Python脚本下载、解压和批量裁剪CHIRPS全球降雨数据,涉及IDM下载工具、文件管理与解压缩,以及GDAL库进行地理空间数据处理。
前言
最近需要下载气象数据——CHIRPS,借助之前学的批量下载哨兵轨道数据和批量解压,特此写一个脚本提取所需要的数据
一、CHIRPS是什么?
CHIRPS(Climate Hazards Group InfraRed Precipitation with Station data)是一个全球范围的降雨数据集,结合了0.05°分辨率的卫星图像和原位站数据,形成网格化的降雨时间序列,用于趋势分析和季节性干旱监测。数据从1981年开始,可以分为每日/每月/每年,其中又可以细分为每若干月、每若干年等等,详细介绍网站:https://www.chc.ucsb.edu/data/chirps
数据下载网站:https://data.chc.ucsb.edu/products/CHIRPS-2.0/
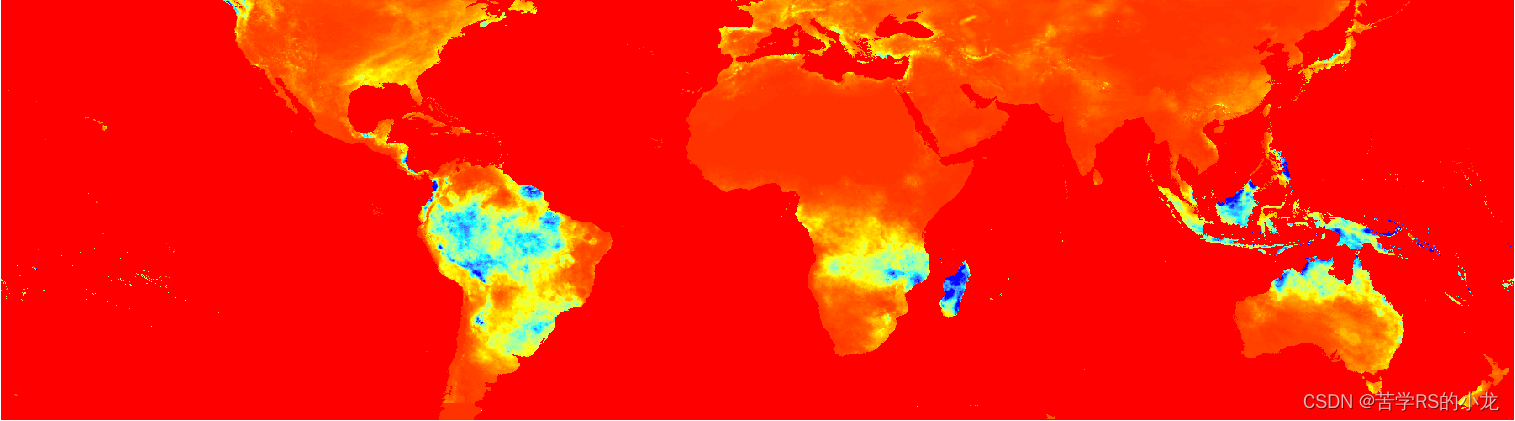
数据为全球范围数据,坐标系为WGS:84
二、实现步骤
1.下载数据
CHIRPS数据的下载与哨兵轨道数据下载方式略有差别,为了加快下载速度我调用了IDM进行数据的下载,这里需要自行安装一个IDM应用程序,正常来说IDM是有使用期限的,分享一个绿色版的链接,如有需要请自己网盘下载。
idm官方命令参数介绍,如下:
idman /s
或 idman /d URL [/p 本地_路径] [/f 本地_文件_名] [/q] [/h] [/n] [/a]
参数:
/d URL - 下载一个文件,等等。
IDMan.exe /d "http://www.internetdownloadmanager.com/path/File Name.zip"
/s - 开始任务调度里的队列
/p 本地_路径 - 定义要保存的文件放在哪个本地路径
/f 本地local_文件_名 - 定义要保存的文件到本地的文件名
/q - IDM 将在成功下载之后退出。这个参数只为第一个副本工作
/h - IDM 将在成功下载之后挂起您的连接
/n - 当不要 IDM 询问任何问题时启用安静模式
/a - 添加一个指定的文件 用 /d 到下载队列,但是不要开始下载
参数 /a, /h, /n, /q, /f 本地_文件_名, /p 本地_路径 工作只在您指定文件下载 /d URL
实现代码如下:
IDM = "E:\IDM\IDM\IDMan.exe"
command = ' '.join([IDM, '/d', DownUrl, '/p', DownPath, '/f', FileName, '/a'])
os.system(command)
call([IDM, '/s'])
需要改的地方为IDM这个变量,这个变量后面的路径为你安装该程序的位置,command是一种类似命令行的调用,call代表开始下载,代码无误应该是下图所示的样子,然后打开IDM可以看到下载队列了。
2.解压缩
在写这部分代码时自己发现一个问题,那就是python调用IDM进行下载后无法实时返回下载情况,1中的代码主要实现:添加下载链接、开始下载,没有返回的信息,而对文件进行解压时就必然要对文件路径进行遍历。因此在IDM执行下载与文件解压之间需要有一段缓冲时间,这里我用通过需要下载文件的个数与实际已经下载好的文件个数进行对比,返回布尔值来决定是否进行下一步的操作,代码如下(示例):
def Judge_check(array,path):
file_list = os.listdir(path)
file_array = []
for file in file_list:
if os.path.splitext(file)[-1] == '.gz':
file_array.append(file) #统计已 .gz结尾的文件'=
if len(array) == len(file_array):
return True
else:
nowtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
print("文件尚未下载完全,缺失%d个,120S后重新读取,%s"%((len(array)-len(file_array)),nowtime))
return False
def Check_file(array,path):
file_list = os.listdir(path)
file_array = []
for file in file_list:
if os.path.splitext(file)[-1] == '.gz':
file_array.append(file) #统计 .gz结尾的文件
if file in array:
print("%s完成下载"%file)
if len(file_array) == len(array):
print("所需时间段内气象数据下载完毕,共计%d个文件"%len(file_list))
#exit(
......
for i in range(1000):
Judge = Judge_check(Chirps_Time_Info,out_path)
if Judge == True :
Check_file(Chirps_Time_Info,out_path)
break
else:
time.sleep(120)#120S后重新读取文件夹下文件信息
continue
这里用到一个for循环,通过Judge函数判断文件路径下有多少个已经下载的文件夹,如果没满足要求就返回False并等待120秒后跳出此处循环(continue)再次进行Judge函数判断,直至二者数量对的上返回True,并执行Check函数,Check函数主要统计以.gz结尾的文件信息

然后再执行解压缩操作,具体通过调用gzip库以及shutil库中的函数进行,这里我卡住挺久,具体原因就是IDM下载时会新建一个文件夹,文件夹下才是我们需要的数据,因此路径不是os.path.join(path,file)而是os.path.join(path,file,file),如果用os.path.join(path,file)那么在open(gz_out_path, “wb+”)就会报错,具体原因就是只有文件才能写入,文件夹是不能写入的
for file in file_list :#!!只有文件才能写入
if os.path.splitext(file)[-1] == '.gz':
gz_path = os.path.join(path,file,file)
f_file = file.replace(".gz", "")# 获取文件的名称,去掉后缀名
gz_out_path = os.path.join(path,'Chirps',f_file)
#读取解压后的文件,并写入去掉后缀名的同名文件
if os.path.exists(gz_out_path) == False:
with gzip.open(gz_path,"rb") as f_in:
with open(gz_out_path, "wb+") as f_out :
shutil.copyfileobj(f_in,f_out)
print("%s解压完成"%file)
3.批量裁剪
这步主要依靠Gdal库和shape库实现,还有一些小的问题,但是不影响最终结果,后续改进的话可以采用更为方便的Geopandas库实现,原理应该是类似arcgis的掩膜提取功。
教训:如果不加cropToCutline=True,那么是矢量裁剪后的tif影像会有偏移…困扰了自己一晚上
ds = gdal.Warp(out_raster,# 裁剪图像保存完整路径(包括文件名)
in_raster,# 待裁剪的影像
format = 'GTiff',# 保存图像的格式
cutlineDSName = in_shape, # 矢量文件的完整路径
cutlineWhere=in_shape,# optionally you can filter your cutline (shapefile) based on attribute values
cropToCutline=True, # 将目标图像的范围指定为cutline 矢量图像的范围
dstSRS='EPSG:4326', # 参考:WGS84
#cutlineWhere="FIELD = 'whatever'", # clip specific feature
#以shp的范围输出
outputBounds=r.bbox,
copyMetadata=True,
dstNodata = 0) # select the no data value you like
ds=None #do other stuff with ds object, it is your cropped dataset. in this case we only close t
小问题就是他会报错,显示:SQL Expression Parsing Error: syntax error, unexpected $undefined, expecting end of string,但是不影响数据,注释掉cutlineWhere=in_shape即可不报错(我也忘记为什么之前加上了)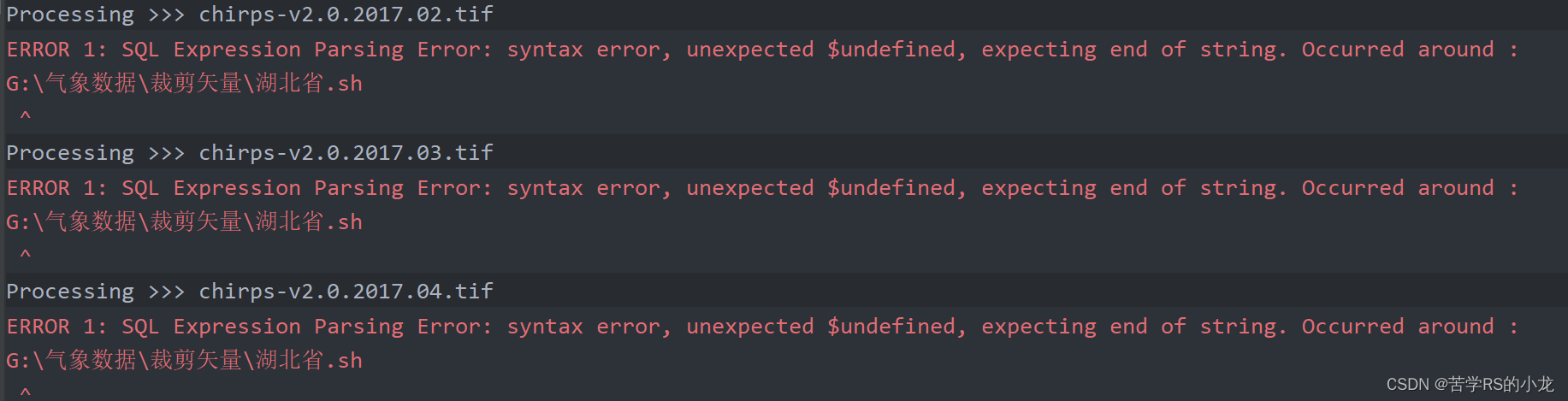
三、完整代码如下
import urllib.request
from bs4 import BeautifulSoup
import re
import os
import requests
from subprocess import call
import gzip
import shutil #复制文件
import time
import datetime
import shapefile
from osgeo import gdal
import sys
""" Notice
# URL https://data.chc.ucsb.edu/products/CHIRPS-2.0/global_monthly/tifs/chirps-v2.0.1981.02.tif.gz
数据是WGS84
"""
def download(dest_dir, url):
print(url)
print(dest_dir)
headers={
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "max-age=0",
"Host": "data.chc.ucsb.edu",
"sec-ch-ua": "\" Not A;Brand\";v=\"99\", \"Chromium\";v=\"100\", \"Google Chrome\";v=\"100\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows \"",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
try:
request = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(request)
urllib.request.urlretrieve(url,dest_dir)
except:
error_url.append(url)
print("\tError retrieving the URL:", dest_dir)
else: # 没有异常
if url in error_url: #在错误列表里
error_url.remove(url)
def IDMdownload(DownUrl, DownPath, FileName):
IDM = "E:\IDM\IDM\IDMan.exe"
command = ' '.join([IDM, '/d', DownUrl, '/p', DownPath, '/f', FileName, '/a'])
os.system(command)
call([IDM, '/s'])
def Judge_check(array,path):
file_list = os.listdir(path)
file_array = []
for file in file_list:
if os.path.splitext(file)[-1] == '.gz':
file_array.append(file) #统计已 .gz结尾的文件'=
if len(array) == len(file_array):
return True
else:
nowtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
print("文件尚未下载完全,缺失%d个,120S后重新读取,%s"%((len(array)-len(file_array)),nowtime))
return False
def Check_file(array,path):
file_list = os.listdir(path)
file_array = []
for file in file_list:
if os.path.splitext(file)[-1] == '.gz':
file_array.append(file) #统计 .gz结尾的文件
if file in array:
print("%s完成下载"%file)
if len(file_array) == len(array):
print("所需时间段内气象数据下载完毕,共计%d个文件"%len(file_list))
#exit(
def ungzip(path):
file_list = os.listdir(path)
store_path = os.path.join(path + './Chirps')
if os.path.exists(store_path) == False: #布尔逻辑词不能用字符
os.mkdir(path + './Chirps')
for file in file_list :#!!只有文件才能写入,文件夹是不能写入的
if os.path.splitext(file)[-1] == '.gz':
gz_path = os.path.join(path,file,file)
f_file = file.replace(".gz", "")# 获取文件的名称,去掉后缀名
gz_out_path = os.path.join(path,'Chirps',f_file)
#读取解压后的文件,并写入去掉后缀名的同名文件
if os.path.exists(gz_out_path) == False:
with gzip.open(gz_path,"rb") as f_in:
with open(gz_out_path, "wb+") as f_out :
shutil.copyfileobj(f_in,f_out)
print("%s解压完成"%file)
else:
print("%s已解压完成,无需再次解压"%file)
continue
f_out.close()
f_in.close()
else:
continue #跳过循环
def warpclip(in_shape,in_dir,out_dir):
in_shape = in_shape #shp路径
in_dir = in_dir # 输入栅格图像地址
out_dir = out_dir # 输出裁剪影像地址
file_list = os.listdir(in_dir) #获取输入图像文件夹的地址
r = shapefile.Reader(in_shape,encoding='gb18030') #获取shp的范围并解决utf-8不行
for file in file_list:
if file.endswith('.tif'):
print('Processing >>> ' + file)
in_raster = gdal.Open(os.path.join(in_dir, file))
out_raster = os.path.join(out_dir,file)
ds = gdal.Warp(out_raster,# 裁剪图像保存完整路径(包括文件名)
in_raster,# 待裁剪的影像
format = 'GTiff',# 保存图像的格式
cutlineDSName = in_shape, # 矢量文件的完整路径
#cutlineWhere=in_shape,# optionally you can filter your cutline (shapefile) based on attribute values
#cutlineWhere="FIELD = 'whatever'", # clip specific feature
#以shp的范围输出
cropToCutline=True, # 将目标图像的范围指定为cutline 矢量图像的范围
dstSRS='EPSG:4326', # 参考:WGS84
outputBounds=r.bbox,
copyMetadata=True,
dstNodata = 0) # select the no data value you like
ds=None #do other stuff with ds object, it is your cropped dataset. in this case we only close the dataset.
else:
print("This file is not '.tif' file ...")
if __name__ == '__main__':
timestart = datetime.datetime.now()
error_url = []
out_path = r'G:\气象数据'
shp_path = r'G:\气象数据\裁剪矢量\湖北省.shp'
StartTime = '2016'
EndTime = '2022'
url = 'https://data.chc.ucsb.edu/products/CHIRPS-2.0/global_monthly/tifs/' #月平均数据
html=requests.get(url).content
dom = BeautifulSoup(html,"lxml") # 解析html文档
#我们只要获取标签a的href值,并加上http://即可构造出下载链接。
a_list = dom.findAll("a") # 找出<a>
CHIRPS_lists = [a['href'] for a in a_list if a['href'].endswith('.gz')] # 找到chirps.gz数据
Chirps_Time_Info = []
for chirps in CHIRPS_lists:
savefile = os.path.join(out_path,chirps)
Chirps_Time = re.split(r'[_,.,\s ]\s*', chirps)[-4] #将Chirps文件的时间信息分割
if Chirps_Time <= EndTime and Chirps_Time >= StartTime :
Chirps_Time_Info.append(chirps)
#download(savefile,'https://data.chc.ucsb.edu/products/CHIRPS-2.0/global_monthly/tifs/'+chirps)
IDMdownload('https://data.chc.ucsb.edu/products/CHIRPS-2.0/global_monthly/tifs/'+chirps,savefile,chirps)
print("------------------------------------")
print("%s文件已添加至下载列表"%chirps)
print("------------------------------------")
#通过循环判断路径下文件是否下载完成,如果完成则进行Check,若未完成则再次读取路径下文件信息
for i in range(1000):
Judge = Judge_check(Chirps_Time_Info,out_path)
if Judge == True :
Check_file(Chirps_Time_Info,out_path)
break
else:
time.sleep(120)#120S后重新读取文件夹下文件信息
continue
ungzip(out_path)
warpclip(shp_path,os.path.join(out_path,'Chirps'),os.path.join(out_path,'Chirps_clip'))
timeend = datetime.datetime.now()
print('Running time: %s Seconds'%(timeend-timestart))
sys.exit()
这里注意有些库可以直接pip安装,如gzip、shapefile等,但是向gdal库的话建议和python版本匹配,我这里用的python3.9,装的GDAL库版本为3.1.2,如果后续需要对图像进行处理安装shapely、geopandas等库时,要注意有一个版本匹配问题,如果直接pip的话到后面装其他库很有可能会报错…如有需要可以下载我上传的资源,或者私信我发给你~
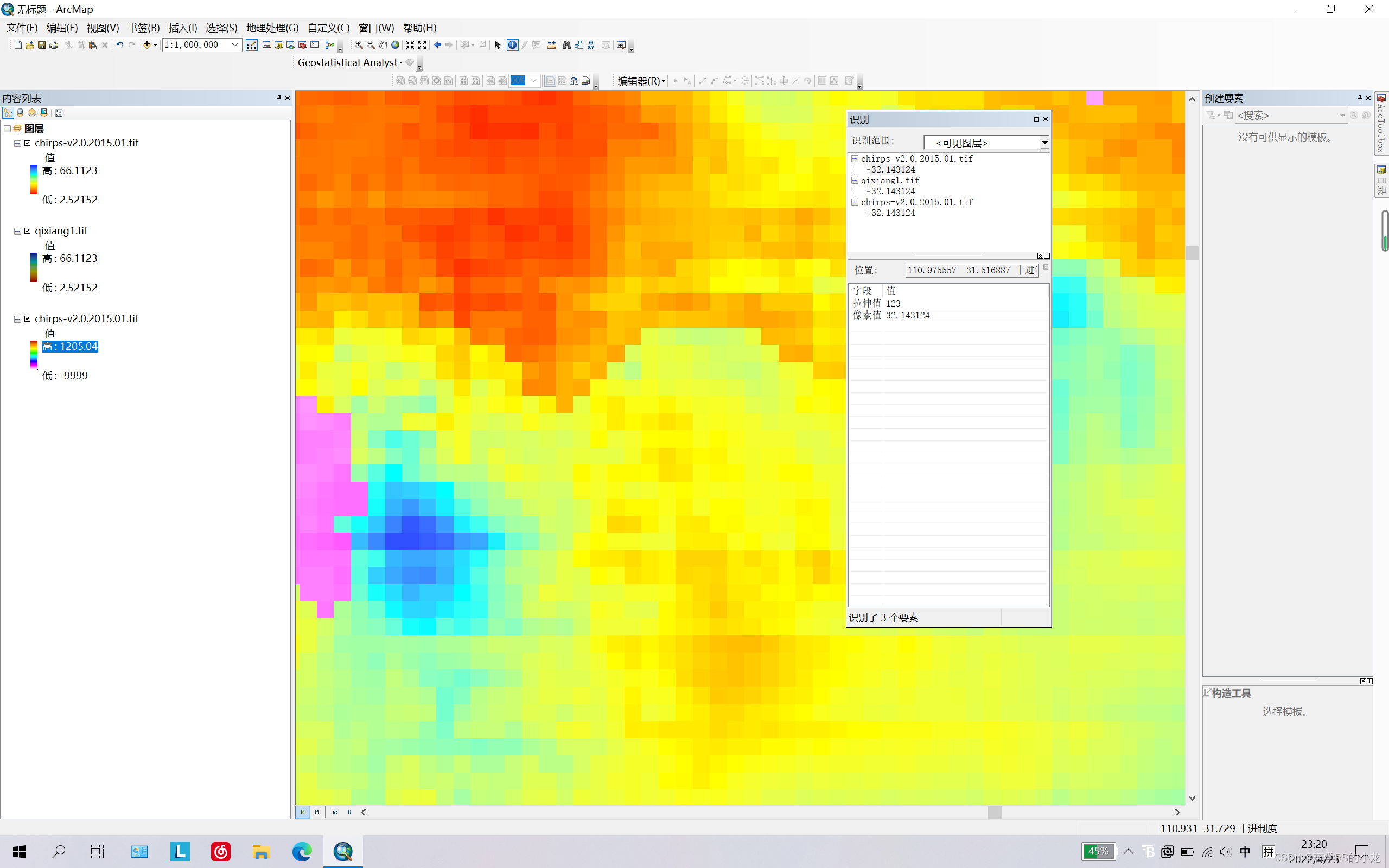
四、代码结果
最后结果如图所示:第一个图层为代码裁剪得出,第二个图层为arcgis工具(按掩膜提取)得出,第三个为解压缩出的原始数据,可以看到三者像元值一致,因此初步认为代码并无问题。


















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}