




对于手写transformer的复盘
参考视频:https://www.youtube.com/watch?v=ISNdQcPhsts&t=9966s
Coding a Transformer from scratch on PyTorch, with full explanation, training and inference.
对应个github仓库:https://github.com/hkproj/pytorch-transformer
从零开始使用 PyTorch 编写 Transformer,包含全面讲解、训练和推理。
看着这个视频手写实现了transform的过程。
先编辑的是
model.py
实现网络的各个模块
定义结构和对应的forward
首先进行的是输入的嵌入层和位置编码,把这两个进行相加。
对于位置编码,可以进行如下的可视化:
import matplotlib.pyplot as plt
def positional_encoding(max_position, d_model):
position = np.arange(max_position)[:, np.newaxis] # 位置向量 [pos, 1]
print(position)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model)) # 频率项
print(div_term)
# PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
# PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
pe = np.zeros((max_position, d_model))
pe[:, 0::2] = np.sin(position * div_term) # 偶数维度用sin
pe[:, 1::2] = np.cos(position * div_term) # 奇数维度用cos
return pe
max_position = 3700 # 纵轴:位置范围
d_model = 512 # 横轴:编码维度(Depth)
pe = positional_encoding(max_position, d_model)
plt.figure(figsize=(12, 6))
plt.imshow(pe, cmap="viridis", aspect="auto")
plt.xlabel("Depth (Encoding Dimension)", fontsize=12) # 横轴为编码维度
plt.ylabel("Position", fontsize=12) # 纵轴为位置索引
plt.colorbar(label="Encoding Value")
plt.title("Positional Encoding Heatmap: Depth vs. Position", fontsize=14)
plt.show()
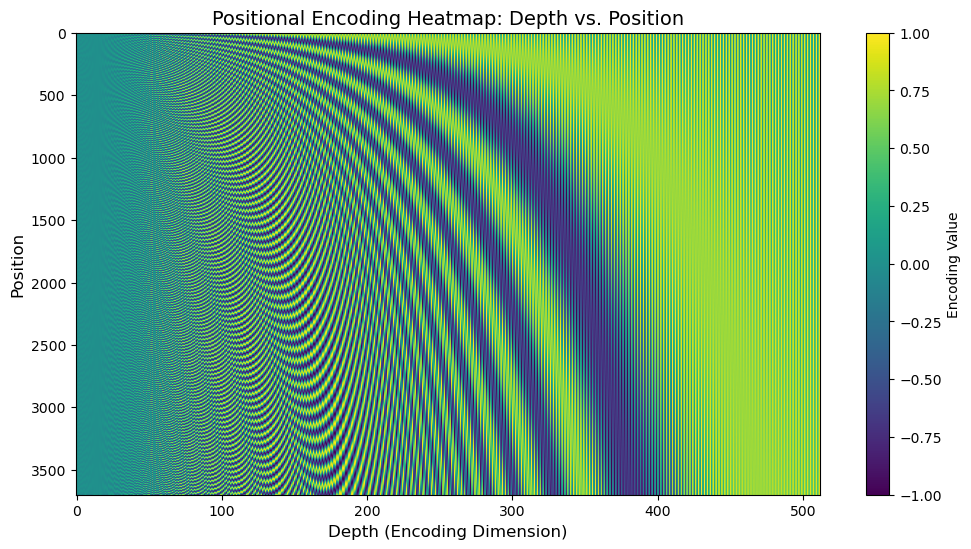
位置编码的可视化
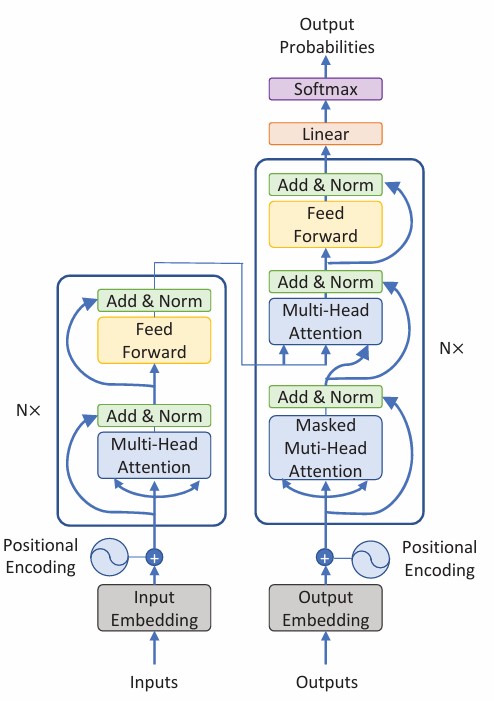
整个模型的架构,我们可以看到,有inputs和outputs.
在这个视频中,使用的是两个语言,从英文到意大利文的翻译。
整体思路,从下到上,逐个定义模块。
重复的模块定义为类,在更大的框中进行复用。
如multi-head Attention层
feed forward层
add&norm层是一个叠加操作的和残差网络类似的,跳跃性连接.
对于decoder的特殊层,是Masked 的多头层,这个可以进行一定的替换,因为此处的上下文,要符合因果联系,即后面的文字完全依赖于前面的内容。其他内容和multi一致。
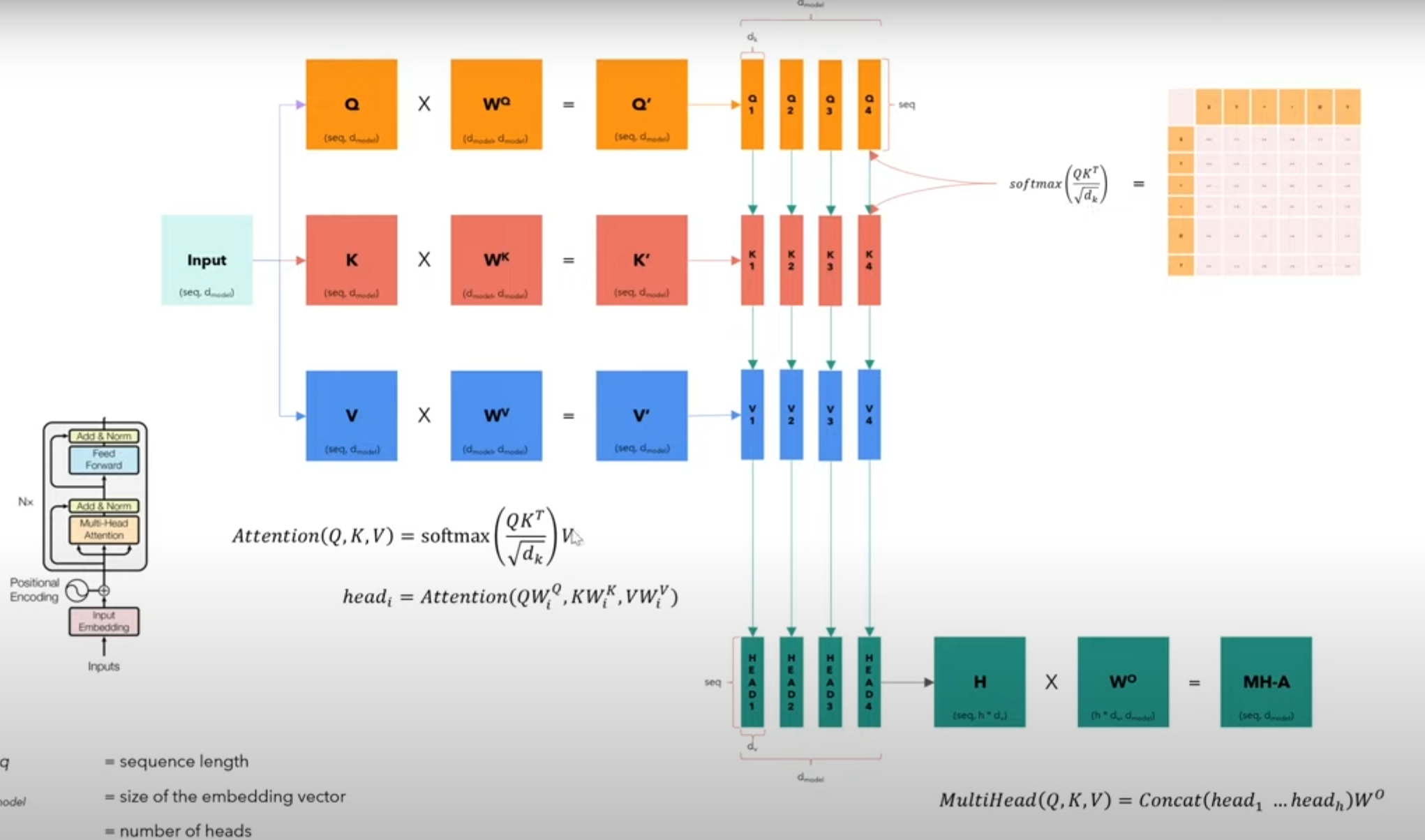
对生成的q,k,v矩阵进行自相关,然后
LayerNormalization的主要过程
x ^ j = x j − μ j σ j 2 + ϵ \widehat{x}_{j}=\frac{x_{j}-\mu_{j}}{\sqrt{\sigma_{j}^{2}+\epsilon}} x j=σj2+ϵxj−μj
feedforward 层的主要过程
F
F
N
(
x
)
=
max
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
\mathrm{FFN}(x)=\max(0,xW_1+b_1)W_2+b_2
FFN(x)=max(0,xW1+b1)W2+b2
分为编码器和解码器来分别构造
注意力的过程在下面的代码中有体现,有一个维度变换的过程。见attention的forward的内容。整个句子即行数。
因为多头在自注意力后,要进行合并。
详情参考原视频,或者仓库里的pdf说明
在最后定义了ResidualConnection
就可以组合出encoder
网络结构中有N个编码器和解码器,这个要成对。因为编码器的output,会在解码器的注意力模块中作为k和v来提供原始信息。
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class InputEmbedding(nn.Module):
def __init__(self,d_model:int,vocab_size:int):
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
# 线性层(nn.Linear)的权重是使用kaiming均匀分布初始化的,而偏置项是使用常数0初始化的。
# PyTorch的nn.Embedding的权重默认是使用从均匀分布中采样的值
# 其权重矩阵(weight)的值通过正态分布(均值为0,标准差为1)随机初始化。此外,如果设置了padding_idx,对应的嵌入向量会被显式置零。
# 手动初始化为均匀分布 [-0.1, 0.1)
# nn.init.uniform_(embedding.weight, a=-0.1, b=0.1)
# vocab_size个正态分布,sqrt(d_k)
self.embedding = nn.Embedding(vocab_size,d_model)
def forward(self,x):
# 定义此处的正向传播操作,平衡嵌入向量的数值,避免梯度爆炸
return self.embedding(x)*math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
def __init__(self,d_model:int,seq_len:int,dropout:float):
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len,d_model)
# create a vector of shape (seq_len,1)
positions = torch.arange(0,seq_len,dtype=torch.float).unsqueeze(1)
#对数运算不改变相对大小
#原始的公式算子是10000^(2i/d_model),此处只对算子进行log,该式子整体在分母的位置,所以添加一个负号
div_term = torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000.0)/d_model))
# apply sin to even positions in the array
pe[:,0::2] = torch.sin(positions*div_term)
# apply cos to odd positions in the array
pe[:,1::2] = torch.cos(positions*div_term)
# 一批句子,添加一个新的维度,这个针对的是单个句子的
pe = pe.unsqueeze(0)#(1,seq_len,d_model)
print(pe.shape)
# 因为这个位置编码是一个固定的,所以我们不需要进行反向传播,所以我们使用register_buffer
self.register_buffer('pe',pe)
def forward(self,x):
# x是传入的字符,其shape是(batch_size,seq_len,d_model)
# 定义此处的正向传播操作,不参与反向传播
x = x + (self.pe[:,:x.shape[1],:]).requires_grad_(False)
# 计算后的维度是(batch_size,seq_len,d_model)
return self.dropout(x)
# 层级的归一化,对于batch(一个句子)
class LayerNormalization(nn.Module):
#一个非常小的数,防止分母为0
def __init__(self,eps:float=10**-6):
super().__init__()
self.eps = eps
self.alpha = nn.Parameter(torch.ones(1))#multiplied
self.bias = nn.Parameter(torch.zeros(1))#added
def forward(self,x):
# 计算平均值会抹除一个维度,所以我们需要保留一个维度
mean = x.mean(dim=-1,keepdim=True)
std = x.std(dim=-1,keepdim=True)
return self.alpha*(x-mean)/(std+self.eps)+self.bias
class FeedForwardBlock(nn.Module):
def __init__(self,d_model:int,d_ff:int,dropout:float):
super().__init__()
#d_ff是什么
self.liner_1 = nn.Linear(d_model,d_ff)# w1 and b1 #bias=True ,偏置矩阵是默认存在的
self.dropout = nn.Dropout(dropout)
self.liner_2 = nn.Linear(d_ff,d_model)# w2 and b2
def forward(self,x):
# (batch_size,seq_len,d_model) -> (batch_size,seq_len,d_ff)
# x = self.dropout(F.relu(self.liner_1(x)))
return self.liner_2(self.dropout(torch.relu(self.liner_1(x))))
# (batch_size,seq_len,d_ff) -> (batch_size,seq_len,d_model)
class MultiHeadAttentionBlock(nn.Module):
def __init__(self,h:int,d_model:int,dropout:float):
super().__init__()
self.d_model=d_model
#几个头,确保这个维度,可以被整除
self.h=h
assert d_model%h==0,"d_model is not divisible by h"
self.d_k = d_model//h
self.w_q = nn.Linear(d_model,d_model)#Wq
self.w_k = nn.Linear(d_model,d_model)#Wk
self.w_v = nn.Linear(d_model,d_model)#Wv
self.w_o = nn.Linear(d_model,d_model)#Wo
self.dropout = nn.Dropout(dropout)
@staticmethod #在没有声明类的情况下直接调用。
def attention(query,key,value,mask,dropout:nn.Dropout):
# 小块的注意力参数维度
d_k = query.shape[-1]
#对于有多个维度的矩阵进行计算的时候,计算的是最后两个维度,然后前面的维度是保持不变的视为批次
# (batch_size,h,seq_len,d_k) -> (batch_size,h,seq_len,seq_len)
attention_scores = (query @ key.transpose(-2,-1))/math.sqrt(d_k)
#使用mask对不希望链接的部分进行屏蔽
if mask is not None:
attention_scores = attention_scores.masked_fill(mask==0,-1e9)
# 对最后一个维度进行softmax
#一个自注意力矩阵,行表示的是一个单词,列表示的是另一个单词
attention_scores = torch.softmax(attention_scores,dim=-1)#(batch_size,h,seq_len,seq_len)
if dropout is not None:
attention_scores = dropout(attention_scores)
#因为我们需要两个第一个用于参数传递,第二个用于自注意力可视化
return (attention_scores @ value),attention_scores
def forward(self,q,k,v,mask):
# q,k,v的维度是(batch_size,seq_len,d_model)
# 首先需要将q,k,v转换为多头的形式
# (batch_size,seq_len,d_model) -> (batch_size,seq_len,d_model) -> (batch_size,seq_len,h,d_k)
# (batch_size,seq_len,d_model)
query = self.w_q(q)# batch_size,seq_len,d_model -> batch_size,seq_len,d_model
key = self.w_k(k)
value = self.w_v(v)
#进行头的拆分,调换顺序,使得每个头可以看到整个句子,头索引作为第二个维度
# batch_size,seq_len,d_model -> batch_size,seq_len,h,d_k-> batch_size,h,seq_len,d_k
query = query.view(query.shape[0],query.shape[1],self.h,self.d_k).transpose(1,2)# batch_size,seq_len,d_model -> batch_size,seq_len,h,d_k
key = key.view(key.shape[0],key.shape[1],self.h,self.d_k).transpose(1,2)# batch_size,seq_len,d_model -> batch_size,seq_len,h,d_k
value = value.view(value.shape[0],value.shape[1],self.h,self.d_k).transpose(1,2)# batch_size,seq_len,d_model -> batch_size,seq_len,h,d_k
x,self.attention_scores = MultiHeadAttentionBlock.attention(query,key,value,mask,self.dropout)
# (Batch,h,seq_len,d_k) -> (batch_size,seq_len,h,d_k) -> (batch_size,seq_len,d_model)进行拼接
#确保张量在内存中连续存储
x = x.transpose(1,2).contiguous().view(x.shape[0],-1,self.h*self.d_k)
return self.w_o(x)#(batch_size,seq_len,d_model)
class ResidualConnection(nn.Module):
def __init__(self,dropout:float):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization()
def forward(self,x,sublayer):
# 残差连接
#论文中,这个norm是先进行的,可传入其他操作的子层
return x + self.dropout(sublayer(self.norm(x)))
#实现了其他的所有组件,组合最终的编码器
class EncoderBlock(nn.Module):
def __init__(self,self_attention_block:MultiHeadAttentionBlock,feed_forward_block:FeedForwardBlock,dropout:float):
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
#定义两个残差连接,模型列表的方式
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)])
def forward(self,x,src_mask):
x = self.residual_connections[0](x,lambda x:self.self_attention_block(x,x,x,src_mask))
x = self.residual_connections[1](x,self.feed_forward_block)
# 一个编码器块的输出是(batch_size,seq_len,d_model)
return x
class DecoderBlock(nn.Module):
def __init__(self,self_attention_block:MultiHeadAttentionBlock,
cross_attention_block:MultiHeadAttentionBlock,
feed_forward_block:FeedForwardBlock,
dropout:float):
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(3)])
def forward(self,x,encoder_output,src_mask,tgt_mask):
x = self.residual_connections[0](x,lambda x:self.self_attention_block(x,x,x,tgt_mask))
#output提供的是q,然后从编码器中获取k,v
x = self.residual_connections[1](x,lambda x:self.cross_attention_block(x,encoder_output,encoder_output,src_mask))
x = self.residual_connections[2](x,self.feed_forward_block)
# 一个解码器块的输出是(batch_size,seq_len,d_model)
return x
#因为一个结构,会包含多个编码器块,有多个层,传入块的列表
class Encoder(nn.Module):
def __init__(self,layers:nn.ModuleList):
super().__init__()
self.layers = layers
self.norm = LayerNormalization()
def forward(self,x,mask):
for layer in self.layers:
x = layer(x,mask)
return self.norm(x)
class Decoder(nn.Module):
def __init__(self,layers:nn.ModuleList):
super().__init__()
self.layers = layers
self.norm = LayerNormalization()
def forward(self,x,encoder_output,src_mask,tgt_mask):
for layer in self.layers:
x = layer(x,encoder_output,src_mask,tgt_mask)
return self.norm(x)
#分别完成了编码器和解码器的构建
#线性层,或者说投影层,把嵌入转换wield词汇表的位置
# 解码器的倒数第二层
class ProjectionLayer(nn.Module):
def __init__(self,d_model:int,vocab_size:int):
super().__init__()
#要把多头的维度转化为词表的维度
self.proj = nn.Linear(d_model,vocab_size)
def forward(self,x):
# (batch_size,seq_len,d_model) -> (batch_size,seq_len,vocab_size)
return torch.log_softmax(self.proj(x),dim=-1)
class Transformer(nn.Module):
def __init__(self,encoder:Encoder,decoder:Decoder,src_embed:InputEmbedding,tgt_embed:InputEmbedding,src_pos:PositionalEncoding,tgt_pos:PositionalEncoding,projection_layer:ProjectionLayer):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
#把输出分开,从而更好的可视化注意力模块
def encode(self,src,src_mask):
src = self.src_embed(src)
src = self.src_pos(src)
return self.encoder(src,src_mask)
def decode(self,encoder_output,src_mask,tgt, tgt_mask):
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt,encoder_output,src_mask,tgt_mask)
def project(self,x):
return self.projection_layer(x)
# 构建最终的模型
# 参数,源和目标的词汇量,src和tdt的len可以不同,因为编码器和解码器可以不同(如果两种语句的差异有,这个可以不同,但是他的层数是必须相同的)
# n_encoder:编码器的层数
# n_decoder:解码器的层数
#N是层数
#h是头的个数
def build_transformer(src_vocab_size:int,tgt_vocab_size:int,src_seq_len:int,tgt_seq_len:int,h:int=8,N:int =6,d_model:int =512,d_ff:int =2048,dropout:float=0.1)->Transformer:
#创建embedding层
src_embed = InputEmbedding(d_model,src_vocab_size)
tgt_embed = InputEmbedding(d_model,tgt_vocab_size)
#这两部分的工作一致,仅有dropout的不同,位置编码层
src_pos = PositionalEncoding(d_model,src_seq_len,dropout)
tgt_pos = PositionalEncoding(d_model,tgt_seq_len,dropout)
#创建编码器块
encoder_blocks = []
for _ in range(N):
encoder_self_attention_block = MultiHeadAttentionBlock(h,d_model,dropout)
feed_forward_block = FeedForwardBlock(d_model,d_ff,dropout)
encoder_block = EncoderBlock(encoder_self_attention_block,feed_forward_block,dropout)
encoder_blocks.append(encoder_block)
#创建解码器块
decoder_blocks = []
for _ in range(N):
decoder_self_attention_block = MultiHeadAttentionBlock(h,d_model,dropout)
decoder_cross_attention_block = MultiHeadAttentionBlock(h,d_model,dropout)
feed_forward_block = FeedForwardBlock(d_model,d_ff,dropout)
decoder_block = DecoderBlock(decoder_self_attention_block,decoder_cross_attention_block,feed_forward_block,dropout)
decoder_blocks.append(decoder_block)
#创建编码器和解码器
encoder = Encoder(nn.ModuleList(encoder_blocks))
decoder = Decoder(nn.ModuleList(decoder_blocks))
#创建投影层
projection_layer = ProjectionLayer(d_model,tgt_vocab_size)
#创建Transformer
transformer = Transformer(encoder,decoder,src_embed,tgt_embed,src_pos,tgt_pos,projection_layer)
#初始化权重,使用xavier_uniform_初始化
for p in transformer.parameters():
if p.dim()>1:
nn.init.xavier_uniform_(p)
return transformer
# print("build_transformer:")
# model = build_transformer(15,20,10,10)
# print("model:",model)
dataset.py
使用双语数据集,对于句子的处理,对数据进行填充和处理的过程,因为要进行句子的对齐,而且有句子的开始和结束等特殊的符号。
要使用tokenizer来进行编码和处理
import torch
import torch.nn as nn
from torch.utils.data import Dataset
#从huggignface中下载双语数据集
class BilingualDataset(Dataset):
def __init__(self,ds,tokenizer_src,tokenizer_tgt,src_lang,tgt_lang,seq_len):
super().__init__()
self.ds=ds
self.tokenizer_src = tokenizer_src
self.tokenizer_tgt = tokenizer_tgt
self.src_lang = src_lang
self.tgt_lang = tgt_lang
self.seq_len = seq_len
#设置句子开头和结尾的token
# print("tokenizer_src:",tokenizer_src)
self.sos_token = torch.tensor([tokenizer_src.token_to_id("[SOS]")],dtype=torch.int64)
self.eos_token = torch.tensor([tokenizer_src.token_to_id("[EOS]")],dtype=torch.int64)
self.pad_token = torch.tensor([tokenizer_src.token_to_id("[PAD]")],dtype=torch.int64)
# 使用tokenizer_src的token_to_id方法,可以将这些特殊符号转换为对应的数字ID,然后保存为张量。
def __len__(self):
return len(self.ds)
def __getitem__(self, index:any)->any:
src_target_pair = self.ds[index]
# print(src_target_pair)
src_text = src_target_pair['translation'][self.src_lang]
tgt_text = src_target_pair['translation'][self.tgt_lang]
#对文本进行分词
enc_input_tokens = self.tokenizer_src.encode(src_text).ids
dec_input_tokens = self.tokenizer_tgt.encode(tgt_text).ids
#对文本进行截断
# 计算需要填充多少个数据
# 编码器的输入序列需要预留 2个位置 给特殊标记 [SOS](开始)和 [EOS](结束)。
# 解码器的输入序列通常只需预留 1个位置 给 [SOS] 标记(训练时输入以 [SOS] 开头,输出以 [EOS] 结尾)
enc_num_padding_tokens = self.seq_len - len(enc_input_tokens) - 2
dec_num_padding_tokens = self.seq_len - len(dec_input_tokens) - 1
if enc_num_padding_tokens < 0 or dec_num_padding_tokens < 0:
raise ValueError("Sentence is too long")
# 构建张量,用于编码器的输入和解码器的输入
# add sos and eos to the source text
encoder_input = torch.cat((
self.sos_token,
torch.tensor(enc_input_tokens,dtype=torch.int64),
self.eos_token,
torch.tensor([self.pad_token]*enc_num_padding_tokens,dtype=torch.int64),
),dim=0)
decoder_input = torch.cat((
self.sos_token,
torch.tensor(dec_input_tokens,dtype=torch.int64),
torch.tensor([self.pad_token]*dec_num_padding_tokens,dtype=torch.int64),
),dim=0)
#说明Tensor是类,而tensor是函数
# add eos to the target text
label = torch.cat((
torch.tensor(dec_input_tokens,dtype=torch.int64),
self.eos_token,
torch.tensor([self.pad_token]*dec_num_padding_tokens,dtype=torch.int64),
),dim=0)
#需要这三者满足同等的长度
assert encoder_input.size(0) == self.seq_len
assert decoder_input.size(0) == self.seq_len
assert label.size(0) == self.seq_len
#padding 不应该参与注意力机制的构建
return {
"encoder_input":encoder_input, #(Seq_len)
"decoder_input":decoder_input, #(Seq_len)
"encoder_mask":(encoder_input != self.pad_token).unsqueeze(0).unsqueeze(0).int(), #(1,1,Seq_len)
#使用因果掩码,使得解码器不能看见未来的信息,只能查看未知的填充单词
"decoder_mask":(decoder_input != self.pad_token).unsqueeze(0).unsqueeze(0).int() & causal_mask(decoder_input.size(0)), #(1,1,Seq_len)->(1,Seq_len,Seq_len)
"label":label, #(Seq_len)
"src_text":src_text,
"tgt_text":tgt_text,
}
def causal_mask(size):
mask = torch.triu(torch.ones((1,size,size)),diagonal=1).type(torch.int)
# torch.triu(torch.ones((1,size,size)),diagonal=-1)#确定填充的是对角线的上还是下的第几个
return mask == 0
#因果掩码
# [[[1, 0, 0, 0, 0],
# [1, 1, 0, 0, 0],
# [1, 1, 1, 0, 0],
# [1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1]]]
# 广播机制扩展了
# [[[1&1, 0&1, 0&1, 0&0, 0&0], # 第1行 → [1,0,0,0,0]
# [1&1, 1&1, 0&1, 0&0, 0&0], # 第2行 → [1,1,0,0,0]
# [1&1, 1&1, 1&1, 0&0, 0&0], # 第3行 → [1,1,1,0,0]
# [1&0, 1&0, 1&0, 0&0, 0&0], # 第4行 → [0,0,0,0,0]
# [1&0, 1&0, 1&0, 0&0, 0&0]]] # 第5行 → [0,0,0,0,0]
config.py
此处进行训练参数的设置
from pathlib import Path
def get_config():
config = {
"batch_size":8, #训练8个句子,然后再进行梯度更新
"num_epochs":25,
"lr":10**-4,#可以使用动态调整学习率的方式,现在不采用,作为基础的应用
"seq_len":350,
"d_model":512,
"lang_src":"en",
"lang_tgt":"it",
"model_folder":"weights",
"model_filename":"tmodel_",
"preload": "19",#在训练过程中,是否加载之前保存的模型,可以接着之前的过程进行训练
"tokenizer_file":"tokenizer_{0}.json",
#tensorboard的名称,记录训练时的损失函数
"experiment_name":"runs/tmodel"
}
return config
def get_weights_file_path(config,epoch: str):
model_folder = config["model_folder"]
model_basename = config["model_filename"]
model_filename = f"{model_basename}{epoch}.pth"
return str(Path('.') / model_folder / model_filename)
train.py
此处呈现但是最后的代码,验证在前面了。
正常的编码顺序是,先进行数据的获取和tokenizer的加载。
get_ds
get_model
train_model
此处有一些需要学习的经验和技巧,在每个训练周期,进行数据和模型参数的暂存,从而可以达到重复训练。
import torch
import torch.nn as nn
from datasets import load_dataset
from tokenizers import Tokenizer
from tokenizers.models import WordLevel
from tokenizers.trainers import WordLevelTrainer
from tokenizers.pre_tokenizers import Whitespace
from pathlib import Path
from torch.utils.data import Dataset,DataLoader,random_split
from dataset import BilingualDataset,causal_mask
# from module import *
from model import build_transformer
from config import get_config,get_weights_file_path
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
import warnings
#记录和查看状态的
import torchmetrics
# https://zhuanlan.zhihu.com/p/560480473
import os
# 此处使用了自己的hugging face的Access密钥
# os.environ["HUGGINGFACE_TOKEN"] = "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"
#登录huggingface
# huggingface-cli login
try:
console_width = os.get_terminal_size().columns
except OSError:
# 无法获取时设置默认值(例如 80)
console_width = 80
# os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
def greedy_decode(model,source,source_mask,tokenizer_src,tokenizer_tgt,max_len,device):
sos_idx =tokenizer_tgt.token_to_id('[SOS]')
eos_idx =tokenizer_tgt.token_to_id('[EOS]')
# 预计算encoder 的output并在每个decoder中重用
#在这个步骤出现了一个问题:mean(): could not infer output dtype. Input dtype must be either a floating point or complex dtype. Got: Long
# 检查一下传入的参数问题,调用错对象了,应该是encode,用了encoder
encoder_output = model.encode(source,source_mask)
#initialize the decoder input with the sos_id
# for batch
# 因为出现了类型的问题,此处查看一下source的type类型
# 我们的目标是生成一个解码器的输出,以SOS开始
# 创建未初始化的张量, 填充起始符索引, 填充起始符索引,指定计算设备
decoder_input = torch.empty(1,1).fill_(sos_idx).type_as(source).to(device)
# for the max len single exe
while True:
#如果decoder_input的长度大于max_len,则停止
if decoder_input.size(1) == max_len:
break
# mask(decoder_input,decoder_input,device)
decoder_mask = causal_mask(decoder_input.size(1)).type_as(source).to(device)
# calculate the output of the decoder
out = model.decode(encoder_output,source_mask,decoder_input,decoder_mask)
# get the predicted next word token
prob = model.project(out[:, -1])
# 因为是贪心算法,直接使用概率最高的那个词语作为下一个词语
_, next_word = torch.max(prob, dim=1)
decoder_input = torch.cat([decoder_input,torch.empty(1,1).type_as(source).fill_(next_word.item()).to(device)],dim=1)
if next_word == eos_idx:
break
return decoder_input.squeeze(0)
#设置一个验证
def run_validation(model,validatioin_ds,tokenizer_src,tokenizer_tgt,max_len,device,print_msg,global_state,writer,num_examples=2):
model.eval()
count = 0
# source_texts = []
# expected = []
# predicted = []
#Size of the control window(just use a default value)
try:
console_width = os.get_terminal_size().columns
except OSError:
# 无法获取时设置默认值(例如 80)
console_width = 80
# 禁用梯度计算
with torch.no_grad():
for batch in validatioin_ds:
count += 1
#批次设置的为1
encoder_input = batch['encoder_input'].to(device)
encoder_mask = batch['encoder_mask'].to(device)
assert encoder_input.size()[0] == 1," Batch size must be 1 for validation"
# encoder_output只计算一次,但是在每次都使用
model_out = greedy_decode(model,encoder_input,encoder_mask,tokenizer_src,tokenizer_tgt,max_len,device)
source_texts = batch['src_text'][0]
target_texts = batch['tgt_text'][0]
model_out_text = tokenizer_tgt.decode(model_out.detach().cpu().numpy())
# source_texts.append(source_texts)
# expected.append(target_texts)
# predicted.append(model_out_text)
# print to the console
print_msg('-'*console_width)
print_msg(f"Source: {source_texts}")
print_msg(f"Target: {target_texts}")
print_msg(f"Predicted: {model_out_text}")
if count==num_examples:
break
#如果批次大小不为1
# for batch in batch_iterator:
# if writer:
# # TorchMetrics ChatErrorRate,BLEU,WordErrorRate
# 可以自行进行扩展
def get_all_sentences(ds,lang):
for item in ds:
#从对中只取lang对应的部分
yield item['translation'][lang]
#使用配置的方式,提供config,dataset,language
def get_or_build_tokenizer(config,ds,lang):
# 保存分词器的路径,
#config['tokenizer_file']='../tokenizer/tokenizer_{0}.json'
tokenizer_path = Path(config['tokenizer_file'].format(lang))
print("tokenizer_path:",tokenizer_path)
if not Path.exists(tokenizer_path):
# 分词器不存在,构建并保存
#对于不认识的单词,使用[Unknown]代替
#
tokenizer = Tokenizer(WordLevel(unk_token="[UNK]")) # 关键点
tokenizer.pre_tokenizer = Whitespace()
tokenizer.add_special_tokens(["[UNK]", "[PAD]", "[SOS]", "[EOS]"])
# 训练分词器
# 四个特殊的标记
# pad可以填充,用于训练transformer,至少出现两次,才会作为词汇表的单词
trainer = WordLevelTrainer(
special_tokens=["[UNK]", "[PAD]", "[SOS]", "[EOS]"],
min_frequency=2
)
print(tokenizer.get_vocab())
tokenizer.train_from_iterator(get_all_sentences(ds,lang),trainer=trainer)
# assert tokenizer.token_to_id("[UNK]") is not None, "[UNK] 标记未添加到词汇表"
tokenizer.save(str(tokenizer_path))
return tokenizer
else:
# 分词器已经存在,直接加载
tokenizer = Tokenizer.from_file(str(tokenizer_path))
return tokenizer
#加载数据集
def get_ds(config):
ds_raw = load_dataset("opus_books", f'{config["lang_src"]}-{config["lang_tgt"]}',split='train',token="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")
# build tokenizer
tokenizer_src = get_or_build_tokenizer(config,ds_raw,config['lang_src'])
# print("tokenizer_src:",tokenizer_src)
tokenizer_tgt = get_or_build_tokenizer(config,ds_raw,config['lang_tgt'])
# print("tokenizer_tgt:",tokenizer_tgt)
# keep 90% of the data for training
train_ds_size = int(0.9 * len(ds_raw))
val_ds_size = len(ds_raw) - train_ds_size
# ds = ds_raw.train_test_split(test_size=0.1)
train_ds_raw,val_ds_raw = random_split(ds_raw,[train_ds_size,val_ds_size])
train_ds = BilingualDataset(train_ds_raw,tokenizer_src,tokenizer_tgt,config['lang_src'],config['lang_tgt'],config['seq_len'])
val_ds = BilingualDataset(val_ds_raw,tokenizer_src,tokenizer_tgt,config['lang_src'],config['lang_tgt'],config['seq_len'])
max_len_src = 0
max_len_tgt = 0
# 最终返回一个整数列表
for item in ds_raw:
src_ids = tokenizer_src.encode(item['translation'][config['lang_src']]).ids
tgt_ids = tokenizer_tgt.encode(item['translation'][config['lang_tgt']]).ids
max_len_src = max(max_len_src,len(src_ids))
max_len_tgt = max(max_len_tgt,len(tgt_ids))
print(f'Max length of source sentence: {max_len_src}')
print(f'Max length of target sentence: {max_len_tgt}')
train_dataloader = DataLoader(train_ds,batch_size=config['batch_size'],shuffle=True)
# 对于验证集使用小批量
val_dataloader = DataLoader(val_ds,batch_size=1,shuffle=True)
return train_dataloader,val_dataloader,tokenizer_src,tokenizer_tgt
def get_model(config, vocab_src_len, vocab_tgt_len):
model = build_transformer(vocab_src_len, vocab_tgt_len, config['seq_len'], config['seq_len'], d_model=config['d_model'])
return model
def train_model(config):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device {device}')
print(config['model_folder'])
Path(config['model_folder']).mkdir(parents=True,exist_ok=True)
# 加载数据集
train_dataloader,val_dataloader,tokenizer_src,tokenizer_tgt = get_ds(config)
# print(tokenizer_src)
# 加载模型
# model = get_model(config, len(tokenizer_src.get_vocab()), len(tokenizer_tgt.get_vocab()))
model = get_model(config,tokenizer_src.get_vocab_size(),tokenizer_tgt.get_vocab_size()).to(device)
# 可视化损失 Tensorboard
writer = SummaryWriter(log_dir=config['model_folder'])
optimizer = torch.optim.Adam(model.parameters(),lr=config['lr'],eps=1e-9)
#因为设置了崩溃重启的设置,所以需要加载之前的模型
initial_epoch = 0
global_step = 0
if config['preload']:
model_filename = get_weights_file_path(config,config['preload'])
print(f'Preloading model {model_filename}')
state = torch.load(model_filename)
initial_epoch = int(config['preload']) + 1
optimizer.load_state_dict(state['optimizer_state_dict'])
global_step = state['global_step']
#平滑,对大概率的动态缩减,从最高概率的标记取出1%分散到其他概率中
loss_fn = nn.CrossEntropyLoss(ignore_index=tokenizer_src.token_to_id('[PAD]'),label_smoothing=0.1).to(device)
for epoch in range(initial_epoch,config['num_epochs']):
model.train()#启用训练模式,设置
# 进度条
batch_iterator = tqdm(train_dataloader,desc=f'Processing epoch {epoch:02d}',total=len(train_dataloader))
for batch in batch_iterator:
encoder_input = batch['encoder_input'].to(device)# (B,Seq_len)
decoder_input = batch['decoder_input'].to(device)#(B,Seq_len)
# 编码器的掩码
encoder_mask = batch['encoder_mask'].to(device)#(B,1,1,Seq_len)
# 解码器的掩码
decoder_mask = batch['decoder_mask'].to(device)#(B,1,Seq_len,Seq_len)
# run the tensors through the encoder, decoder and the projection layer
encoder_output = model.encode(encoder_input,encoder_mask)#(B,Seq_len,d_model)
decoder_output = model.decode(encoder_output,encoder_mask,decoder_input,decoder_mask)#(B,Seq_len,d_model)
proj_output = model.project(decoder_output)#(B,Seq_len,vocab_size)
#修改两者的维度,使得两者的维度相同,才能计算损失
# 计算损失
label = batch['label'].to(device)#(B,Seq_len)
# (B,Seq_len,vocab_size) -> (B*Seq_len,vocab_size)
loss = loss_fn(proj_output.view(-1,tokenizer_tgt.get_vocab_size()),label.view(-1))
batch_iterator.set_postfix({'loss':f'{loss.item():6.3f}'})
# 反向传播
writer.add_scalar('train loss',loss.item(),global_step)
writer.flush()
# Backpropagation
loss.backward()
#update weights
optimizer.step()
optimizer.zero_grad(set_to_none=True)
#在每训练完一个轮次后,就进行一次验证
# run_validation(model,val_dataloader,tokenizer_src,tokenizer_tgt,config['seq_len'],device,lambda msg: batch_iterator.write(msg),global_step,writer)
global_step += 1
run_validation(model,val_dataloader,tokenizer_src,tokenizer_tgt,config['seq_len'],device,lambda msg: batch_iterator.write(msg),global_step,writer)
# 保存模型
model_filename = get_weights_file_path(config,f'{epoch:02d}')
torch.save({
'epoch':epoch,
'model_state_dict':model.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'global_step':global_step
},model_filename)
if __name__ == '__main__':
warnings.filterwarnings('ignore')
config = get_config()
# print(config)
train_model(config)
多头模块的可视化
使用了altair
import torch
import torch.nn as nn
from model import Transformer
from config import get_config,get_weights_file_path
from train import get_model,get_ds,greedy_decode
from pathlib import Path
import math
import torch.nn.functional as F
# 额外的库
import altair as alt
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
#加载模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("Useing device:",device,"\n")
config = get_config()
train_dataloader, val_dataloader, vocab_src, vocab_tgt = get_ds(config)
model = get_model(config, vocab_src.get_vocab_size(), vocab_tgt.get_vocab_size()).to(device)
model_filename = get_weights_file_path(config,f"24")
state = torch.load(model_filename)
model.load_state_dict(state['model_state_dict'])
#此处是进行推理
def load_next_batch():
# Load a sample batch from the validation set
batch = next(iter(val_dataloader))
encoder_input = batch["encoder_input"].to(device)
encoder_mask = batch["encoder_mask"].to(device)
decoder_input = batch["decoder_input"].to(device)
decoder_mask = batch["decoder_mask"].to(device)
encoder_input_tokens = [vocab_src.id_to_token(idx) for idx in encoder_input[0].cpu().numpy()]
decoder_input_tokens = [vocab_tgt.id_to_token(idx) for idx in decoder_input[0].cpu().numpy()]
# check that the batch size is 1
assert encoder_input.size(
0) == 1, "Batch size must be 1 for validation"
model_out = greedy_decode(
model, encoder_input, encoder_mask, vocab_src, vocab_tgt, config['seq_len'], device)
return batch, encoder_input_tokens, decoder_input_tokens
def mtx2df(m, max_row, max_col, row_tokens, col_tokens):
# 将注意力矩阵m转换为数据dataframe
# r:行
# c:列
# v:值
# row_token:行token
# col_token:列token
return pd.DataFrame(
[
(
r,
c,
float(m[r, c]),
"%.3d %s" % (r, row_tokens[r] if len(row_tokens) > r else "<blank>"),
"%.3d %s" % (c, col_tokens[c] if len(col_tokens) > c else "<blank>"),
)
for r in range(m.shape[0])
for c in range(m.shape[1])
if r < max_row and c < max_col
],
columns=["row", "column", "value", "row_token", "col_token"],
)
def get_attn_map(attn_type: str, layer: int, head: int):
#注意力分数提取
# 自注意力和交叉注意力
# 参数:
# attn_type: 自注意力或交叉注意力
# layer: 层
# head: 头
# 返回:[seq_len, seq_len] 注意力矩阵
if attn_type == "encoder":
attn = model.encoder.layers[layer].self_attention_block.attention_scores
elif attn_type == "decoder":
attn = model.decoder.layers[layer].self_attention_block.attention_scores
elif attn_type == "encoder-decoder":
attn = model.decoder.layers[layer].cross_attention_block.attention_scores
return attn[0, head].data
def attn_map(attn_type, layer, head, row_tokens, col_tokens, max_sentence_len):
df = mtx2df(
get_attn_map(attn_type, layer, head),
max_sentence_len,
max_sentence_len,
row_tokens,
col_tokens,
)
return (
alt.Chart(data=df)
.mark_rect()
.encode(
x=alt.X("col_token", axis=alt.Axis(title="")),
y=alt.Y("row_token", axis=alt.Axis(title="")),
color="value",
tooltip=["row", "column", "value", "row_token", "col_token"],
)
#.title(f"Layer {layer} Head {head}")
.properties(height=400, width=400, title=f"Layer {layer} Head {head}")
.interactive()
)
def get_all_attention_maps(attn_type: str, layers: list[int], heads: list[int], row_tokens: list, col_tokens, max_sentence_len: int):
charts = []
for layer in layers:
rowCharts = []
for head in heads:
rowCharts.append(attn_map(attn_type, layer, head, row_tokens, col_tokens, max_sentence_len))
charts.append(alt.hconcat(*rowCharts))
return alt.vconcat(*charts)
batch, encoder_input_tokens, decoder_input_tokens = load_next_batch()
print(f'Source: {batch["src_text"][0]}')
print(f'Target: {batch["tgt_text"][0]}')
sentence_len = encoder_input_tokens.index("[PAD]")
Source: The same lady pays for the education and clothing of an orphan from the workhouse, on condition that she shall aid the mistress in such menial offices connected with her own house and the school as her occupation of teaching will prevent her having time to discharge in person.
Target: "La stessa signora paga per l’educazione e per il vestiario di un’orfana della manifattura a condizione che la ragazza aiuti la maestra nel servizio di casa e di scuola.
layers = [0, 1, 2]
heads = [0, 1, 2, 3, 4, 5, 6, 7]
# Encoder Self-Attention
get_all_attention_maps("encoder", layers, heads, encoder_input_tokens, encoder_input_tokens, min(20, sentence_len))
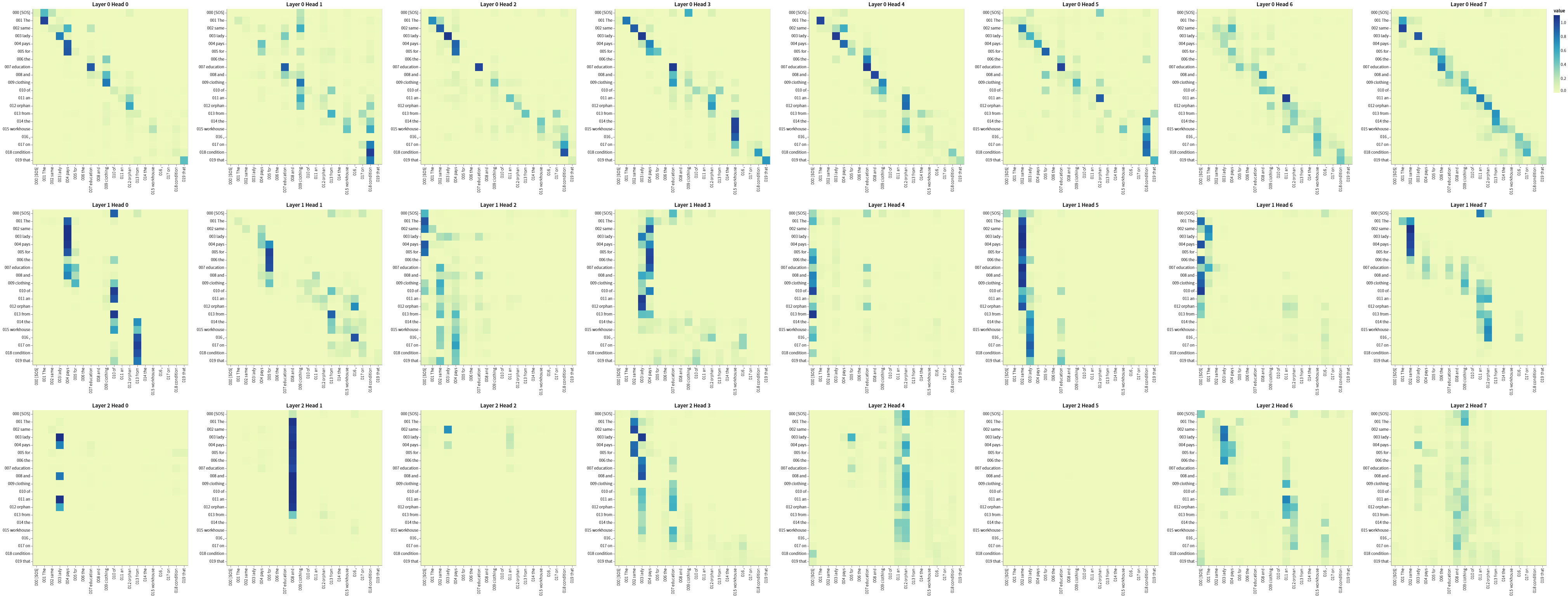

















 3933
3933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









