







卡方检验属于非参数检验,由于非参检验不存在具体参数和总体正态分布的假设,所以有时被称为自由分布检验。
参数和非参数检验最明显的区别是它们使用数据的类型。
非参检验通常将被试分类,如民主党和共和党,这些分类涉及名义量表或顺序量表,无法计算平均数和方差。
卡方检验分为拟合度的卡方检验和卡方独立性检验。
我们用几个例子来区分这两种卡方检验:
对于可口可乐公司的两个领导品牌,大多数美国人喜欢哪一种?
公司采用了新的网页页面B,相较于旧版页面A,网民更喜欢哪一种页面?
以上两个例子属于拟合度的卡方检验,原因在于它们都是有关总体比例的问题。我们只是将个体分类,并想知道每个类别中的总体比例。它检验的内容仅涉及一个因素多项分类的计数资料,检验的是单一变量在多项分类中实际观察次数分布与某理论次数是否有显著差异。
拟合度的卡方检验定义:
主要使用样本数据检验总体分布形态或比例的假说。测验决定所获得的的样本比例与虚无假设中的总体比例的拟合程度如何。
拟合度的卡方检验又叫最佳拟合度的卡方检验,为何取名“最佳拟合”?这是因为最佳拟合度的卡方检验的目的是比较数据(实际频数)与虚无假设。确定数据如何拟合虚无假设指定的分布,因此取名“最佳拟合”。
关于拟合度的卡方检验有一些翻译上的区别,其实表达的是一个意思:
拟合度的卡方检验=卡方拟合优度检验=最佳拟合度卡方检验
以下统称:卡方拟合优度检验
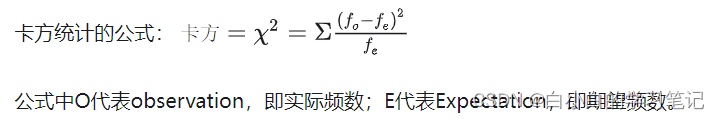

举例:我们准备在周末举办一个派对,并预期有1000个客人。实际来参加派对的人数为1040人。当我们计划接待1000人时,比预期多40个人并不是什么大问题,大家可能仍然有足够的啤酒和薯片。另一种情况,假设我们预期派对有10人出席,而实际上来了50人。在这种情况下,多出来的40个客人将会导致大麻烦,因为实际人数是预期人数的5倍,我们可能并没有足够的食物提供。
因此,差异如何显著取决于你原先的预期。
拟合优度检验中自由度为:k-1,k代表分类变量数
当期望次数并不假定是均匀分布时,也可以采用拟合优度检验。
卡方拟合优度检验在R中的实现
我们用上面的一个例子来实践,假设有一个数据集包含60名被试对新旧版网页的喜好选择。是否网民更喜欢新网页的布局?

head(prefsAB)
Subject Pref
1 1 B
2 2 B
3 3 B
4 4 B
5 5 B
6 6 B
summary(prefsAB)
Subject Pref
1 : 1 A:14
2 : 1 B:46
3 : 1
4 : 1
5 : 1
6 : 1
(Other):54
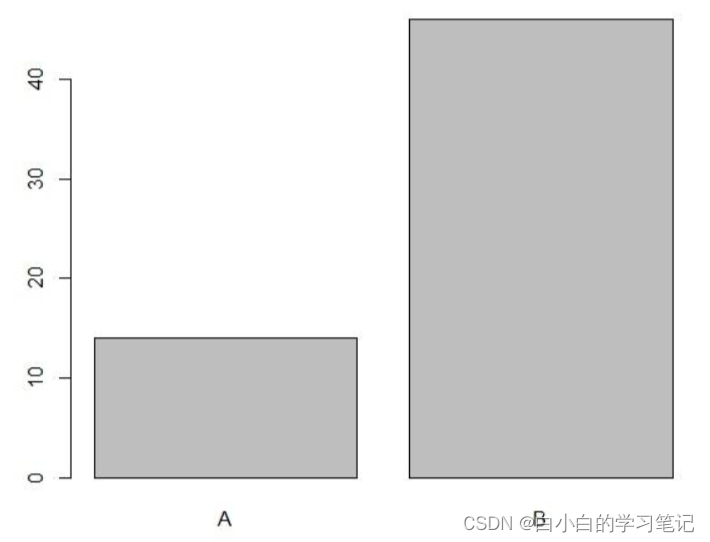
数据包含两列,第一列为被试,第二列为喜好(A为旧版页面,B为新版页面)
选择A的共有14人,选择B的共有46人。
用条形图查看,可以看出更多的被试偏爱新网页(B)的布局
plot(prefsAB$Pref)
采用xtabs生成频数表
prfs = xtabs( ~ Pref, data=prefsAB)
prfs
Pref
A B
14 46
进行卡方拟合优度检验
chisq.test(prfs)
Chi-squared test for given probabilities
data: prfs
X-squared = 17.067, df = 1, p-value = 3.609e-05
p值小于0.05,拒绝原假设H0,被试对新网页有着显著的偏爱。
如何报告卡方值
APA为在科学杂志上报告卡方统计指定了具体的格式。
被试对新旧网页布局的喜好有着显著的不同,新网页更受到偏爱,

卡方符号后的括号中包含自由度以及样本大小n
内容参考自知乎—Anakin Skywalker


















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











