




1.卡方检验(Chi-square test)
卡方检验(Chi-square test),也称为χ²检验,是一种统计学中常用的假设检验方法,用于评估观察频数与期望频数之间是否存在显著差异。以下是进行卡方检验的基本步骤和概念:
-
检验假设:
零假设(H0):假设各总体率或总体构成比之间没有差别,或者两个变量之间没有关联性。备择假设(H1):假设各总体率或总体构成比之间有差别,或者两个变量之间存在关联性。 -
计算期望频数:
基于行和列的边际总和计算每一格的期望频数。期望频数的计算公式为:fcij = (Fxi * Fyi) / n,其中Fxi表示x变量各类别的边缘次数分配,Fyj表示y变量各类别的边缘次数分配,n为总次数。 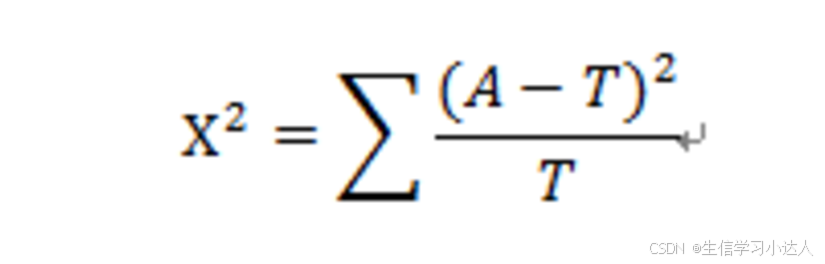
-
其中,A为实际值,T为理论值。
X2用于衡量实际值与理论值的差异程度(也就是卡方检验的核心思想),包含了以下两个信息:
1. 实际值与理论值偏差的绝对大小(由于平方的存在,差异是被放大的)
2. 差异程度与理论值的相对大小 -
计算卡方值:
卡方值的计算公式为:χ² = ∑[(fo - fc)² / fc],其中fo表示实际观测频数,fc表示期望频数。 -
确定自由度:
对于一个R×C的列联表,自由度为(r-1)(c-1),其中r是行数,c是列数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









