







背景介绍
1. 京东黄金眼商智流量业务场景
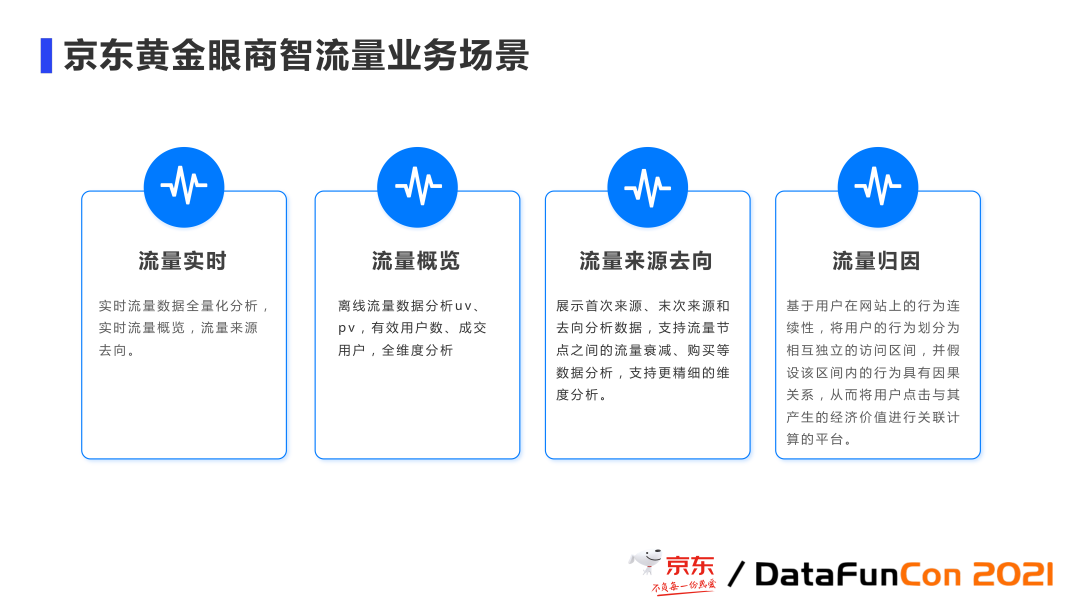
首先以流量这一业务场景来介绍一下我们现在的业务形态。
-
流量实时
实时流量数据的全量化分析,实时的流量概览,实时流量 PV/UV,流量的来源去向。
-
流量概览
以天/周/月粒度任意维度组合进行流量分析的离线数据,如有效用户数、成交用户数,我们都会进行全维度的分析。全维度的分析,不可能对所有的场景都做预计算,必然有大量的场景是进行极速的 OLAP 来计算。
-
流量的来源去向
我们假定从其他方面购买的流量,包括首次来源、末次来源,流向的分析,如用户从一个店铺跳转到另外一个店铺的趋向分析,流量的衰减,以及当中的一些购买的一些数据的分析,进行更精细的维度分析。
-
流量归因
假定用户在网站上的行为是连续性的,我们把这种区间性的划分为各个独立的访问区间,这里的区间我们认为存在因果关系。从而可以将用户的点击和购买行为进行关联计算的平台。
2. 流量分析特征
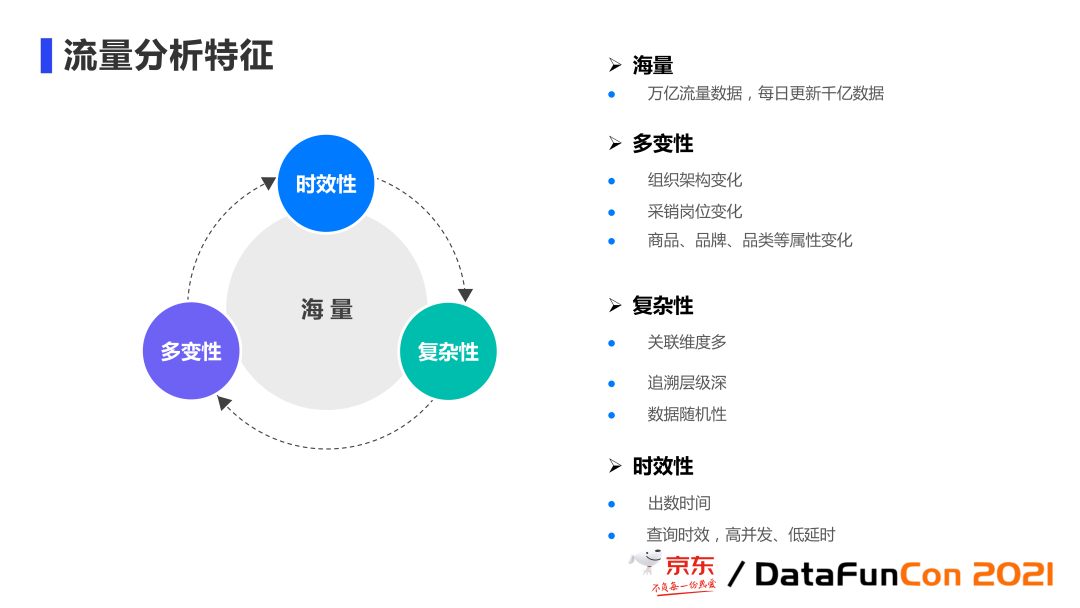
流量数据的特征:
-
海量
万亿流量数据,每日更新数据量达千亿量级,目前火热的 ClickHouse 等开源社区工具也满足不了每天更新千亿量级数据量的处理,因此我们也做了一些改造。
-
多变性
流量分析在电商领域中是以商品 SPU 为主,随着组织架构的变化、采销的岗位变化、以及商品、品牌、品类等属性的变化,做及时的调整来制定更及时准确的经营策略。
-
复杂性
首先流量有相应的品类,包括渠道、平台,关联的维度很多且层级也很深,渠道有 1~4 级甚至到 6 级,品类也到 4 级,这种层级的累加就造成了数据分析的困难性和复杂性。其次是数据的随机性,用户的点击行为是任意的,广告的推荐或图片展示都可能吸引用户的点击行为。
-
实效性
也就是我们常说的 SLA,没有及时性的变化,也就没有太大的意义了。同时,查询的时效要求高并发,大量的采销可能在同一个时间点,如双 11 零点就是一个大家都看的时间点,就会造成那个区间段的高并发,另外,还要求查询的低延时。
3. 京东黄金眼解决思路

基于上面的特点,我们主要从三个方向来解决。
-
时效性
首先每天的数据加工离线预计算要求在 8 点前出数;其次是推数时效,需要达到 10 亿量级的更新速度;最后是版本化更新数据无感知,每天更新的量级比较大,假设有张表每天要更新 100 亿数据,当更新了 20 亿的时候,用户访问了此时 PV 是 1000 万,过了一会儿再看又变成 2000 万,就会导致用户的困惑,显然不可能一会儿就增加了 100% 的数据量。因此我们实行了版本化的更新数据,在数据没有完成之前,用户看不到进行中的数据,当他能看到的时候就是正确的数据。这对用户的经营策略的抉择、相应的方案制定都更加精准。
-
精准性
每日更新的数据维度信息通常有两种方案,直接关联 OLAP 表或者字典刷卡。另外也会对特定的场景进行物化视图,如实时从 Kafka 写到 ClickHouse 的场景中如果有去重的要求,用到的引擎是 ReplicatedReplacingMergeTree,如果不去重直接用 ReplicateMergeTree 的话,需要建立物化视图进行去重。需要注意的是物化视图的 group by 和 order by 要尽量跟原表保持一致,否则会产生数据差异性。
-
高并发
ClickHouse 一般只有 20~50 的 QPS,如果要满足 200 甚至 2000 的 QPS 就需要进行升级,这里我们用到了其他引擎的特性。单个的 ClickHouse 集群无法满足业务查询的需求,因此我们进行了多活集群的负载来同时满足业务查询,如 a 到 A 集群查询,b 到 B 集群查询,此时就需要做集群的负载,这必然涉及到集群的状态管控,来实时监控集群 CPU、内存等资源的状态,以及读取 ClickHouse 本身的系统表信息,如 select query_log、system.parts 里的数据合并情况。
数据工具
第一部分解决了数据从其他数据源到 Clic
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











