






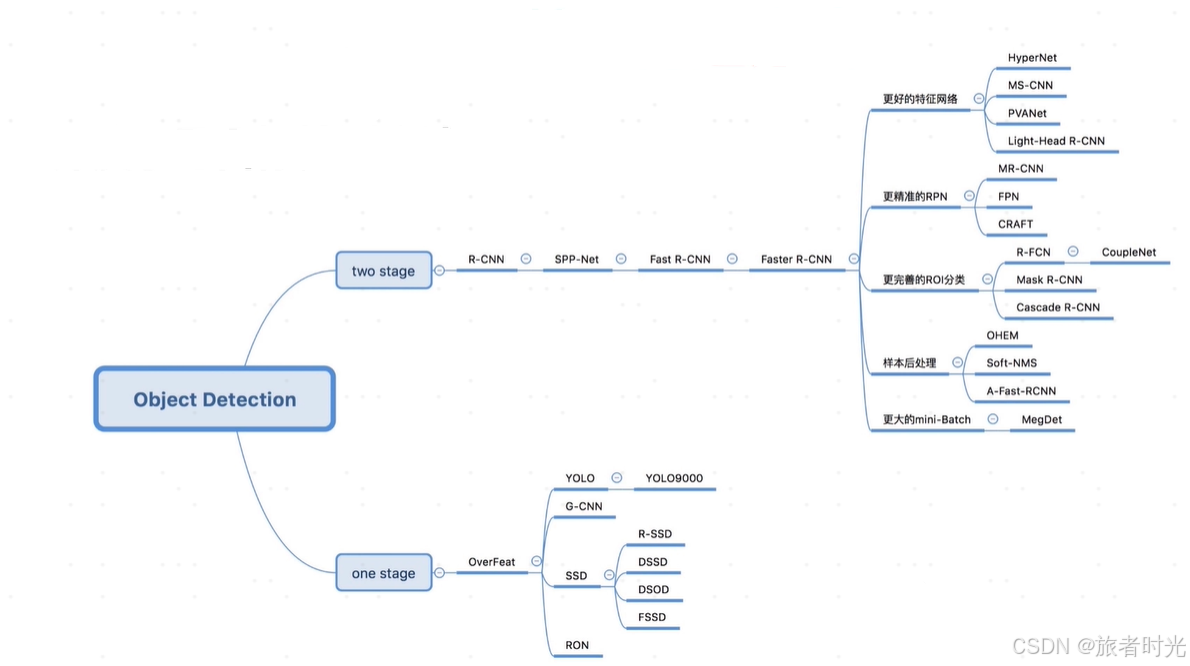
一、目标检测算法发展概要
1、传统方法
在深度学习出现之前,传统的目标检测方法主要依赖于手工设计的特征和分类器。这些方法通常分为两个主要步骤:特征提取和目标分类。
1.1 HOG(Histogram of Oriented Gradients)
HOG 通过计算图像中每个像素的梯度方向和大小,生成梯度方向直方图。这些直方图被用于描述图像中的局部形状和外观。通过滑动窗口技术,在图像的不同位置和尺度上提取 HOG 特征,并使用线性分类器(如 SVM)进行目标分类。
1.2 模板匹配(Template Matching)
使用预定义的目标模板(如图像块),在输入图像中滑动并计算模板与图像块之间的相似度。通过设定相似度阈值,确定目标的位置。
1.3 滑动窗口(Sliding Window)
在图像的不同位置和尺度上使用滑动窗口,提取局部特征(如 HOG、LBP 等)。通过分类器(如 SVM、Adaboost 等)对每个窗口进行分类,确定目标的位置。
1.4 Viola-Jones 目标检测器
使用 Haar-like 特征(如边缘、线、对角线等)描述图像中的局部区域。通过级联分类器(如 Adaboost)对每个窗口进行分类,逐步过滤非目标区域,提高检测效率。
2、深度学习方法
(1)one-stage
单阶段检测器直接在输入图像上进行目标检测,通过一个CNN主干网络提取特征,然后直接对目标位置进行回归和对类别进行判定。检测速度相对较快,通常适用于实时应用场景。
1)YOLO(You Only Look Once)
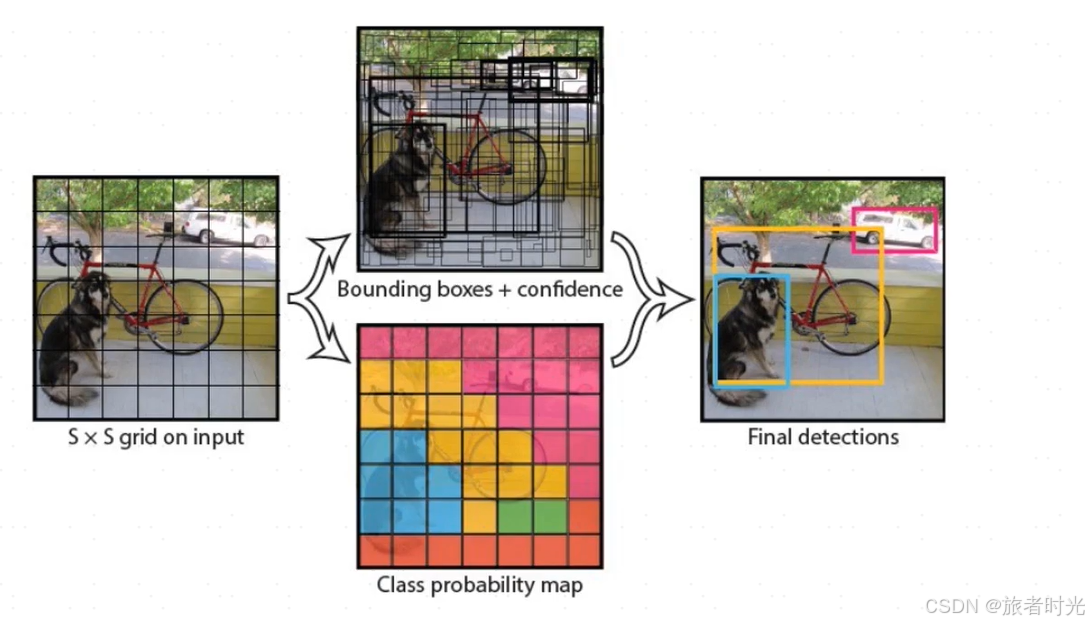
yolo的核心思想是,将图像划分成n*n的网格。以一个网格为中心,向周围扩散出一个区域,一般会有多个尺度。如果这个区域与目标区域的重叠度超过阈值,则作为一个预测的目标区域。最终,对于同一个对象可能有多个预测位置,再使用NMS非极大抑制对多个区域进行合并。
因为网格划分不可能太精细(影响检测效率),目标的实际中心点很可能不在任何一个网格(的中心),或者一个网格就可能包含多个小目标。这导致yolo算法预测的边界框精度不高,对小目标的识别率也不高。
发展历史
- YOLOv1(2016):由 Joseph Redmon 等人提出,首次将目标检测任务视为一个回归问题,通过单个卷积神经网络直接预测目标的类别和边界框。YOLOv1 实现了实时目标检测,速度显著优于 RCNN 系列。
- YOLOv2(2017):引入了锚点(Anchor)机制和多尺度预测,提高了检测精度和速度。
- YOLOv3(2018):进一步改进了网络结构,引入了多尺度特征融合和更深的网络,提高了检测精度。
- YOLOv4(2020):在 YOLOv3 的基础上引入了多种优化技术,如数据增强、网络结构优化等,进一步提高了检测精度和速度。
- YOLOv5(2020):由 Ultralytics 团队开发,进一步优化了网络结构和训练流程,提供了更快的训练速度和更高的检测精度。
- YOLOv8(2023):在v5的基础上进行了主干网络优化、检测和分类头分离、损失函数改进、正负样本分配由静态改为动态等改进措施。
- YOLOv11(2024):最新版本,使用改进的主干和颈部架构来增强特征提取,以实现更精确的目标检测和复杂任务的性能。相比v8版本,参数更少,检测效率更高。
2)SSD(Single Shot MultiBox Detector)
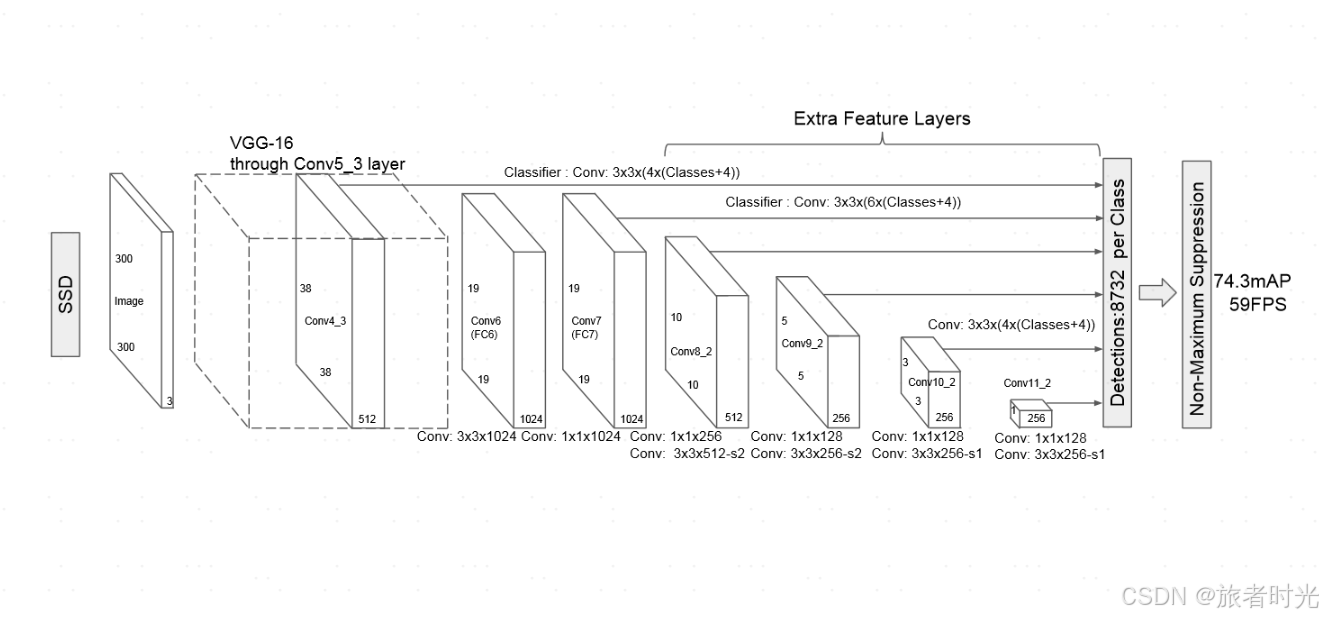
SSD由 Wei Liu 等人在2016年提出。 结合了卷积网络中的特征金字塔网络(Feature Pyramid Networks, FPN)和锚点(anchor boxes)机制。它使用不同尺度的特征图来预测对象,这有助于检测不同大小的对象。
在小物体检测精度和边界框预测精度上比yolo更好,但也因为需要计算多个尺度特征图,检测速度相对yolo会慢一点。
(2)two-stage
两阶段检测器首先生成候选区域(Region Proposal),然后对每个候选区域进行分类和边界框回归。相当于对区域先进行了初步筛选,因此,检测精度更高。通常适用于对精度要求较高、目标类别较多的应用场景。当然,缺点就是检测速度较慢。
1)RCNN(Region-based Convolutional Neural Networks)
发展历史
- RCNN(2014):由 Ross Girshick 等人提出,首次将卷积神经网络(CNN)应用于目标检测任务。RCNN 通过选择性搜索(Selective Search)生成候选区域,然后对每个区域进行分类和边界框回归。
- Fast RCNN(2015):在 RCNN 的基础上进行了改进,通过共享卷积特征图来加速训练和推理过程。Fast RCNN 引入了 RoI Pooling 层,将不同大小的候选区域映射到固定大小的特征图上。
- Faster RCNN(2015):进一步改进了候选区域生成方法,提出了区域建议网络(Region Proposal Network, RPN),将候选区域生成和目标检测任务统一到一个网络中,显著提高了检测速度。
优点
- 高精度:RCNN 系列算法在目标检测任务中表现出色,尤其是在复杂场景和多目标检测中。
- 灵活性:可以处理不同尺度和形状的目标,适用于多种应用场景。
- 端到端训练:Faster RCNN 实现了端到端的训练,简化了训练流程。
缺点
- 速度慢:RCNN 和 Fast RCNN 的推理速度较慢,主要受限于候选区域生成和特征提取步骤。
- 复杂性高:网络结构较为复杂,训练和推理过程需要多个步骤,增加了实现的难度。
二、快速使用
目标检测的框架有很多,如早期的darknet、caffe,现在比较流行的有detectron2、tensorflow、ultralytics。前两个提供了ssd、rcnn系列算法和预训练模型,ultralytics提供了多个版本的yolo算法和预训练模型。
下面介绍以tensorflow(2)为框架介绍,如何快速训练一个基于ssd或rcnn的目标检测模型,以ultralytics为框架介绍,如何训练一个基于yolo的目标检测模型。
1、YOLO
使用ultralytics框架训练yolo非常简单,可以通过配置文件生成网络结构,然后加载数据进行训练。也可以直接加载预训练模型,进行迁移学习。模型下载地址:
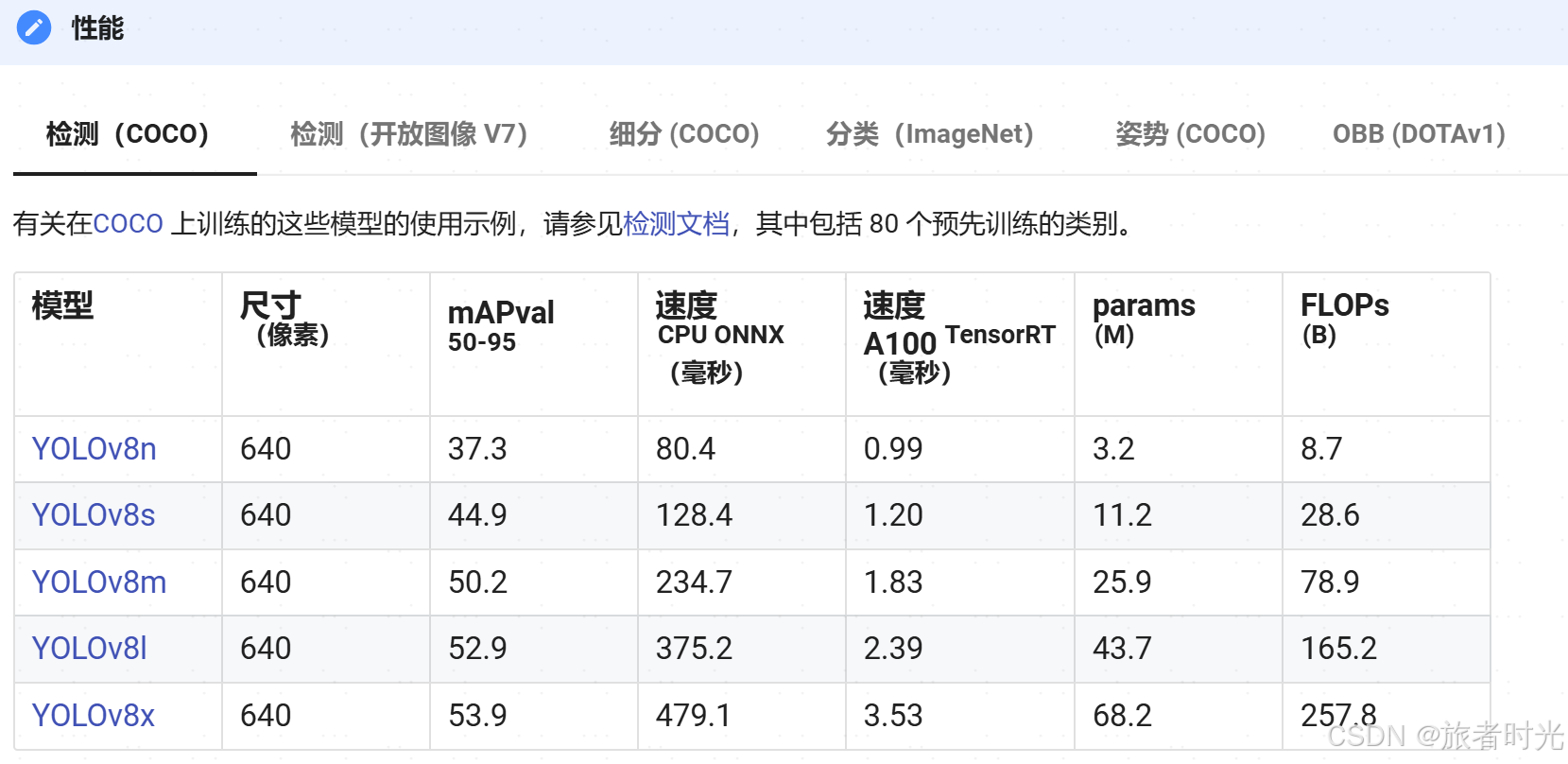
根据不同任务和对时间、精度的要求下载对应预训练模型。
from ultralytics import YOLO
# 使用官方配置文件生成模型。这种方式是全新训练,数据集大小需要保证,学习率可以稍微大一点。
# model = YOLO('yolov8.yaml')
# 加载预训练模型;基于预训练的两种方式,学习率都可以小一点。
model = YOLO('yolov8n.pt')
# 先加载配置文件生成模型再加载权重,需修改配置文件yolov8.yaml中类别数nc的值
# model = YOLO('yolov8.yaml').load('/image_identify/models/yolo-v8/yolov8n.pt')
# 设置训练参数
train_args = {
'data': 'dataset.yaml', # 数据集配置文件路径
'epochs': 50, # 训练轮数
'batch': 16, # 批量大小
'imgsz': 640, # 图像尺寸,如果不是这个尺寸,需要提前缩放处理
'workers': 4, # 数据加载线程数
'device': 0, # 使用的设备(GPU编号 或 CPU)
'project': 'custom_yolov8', # 项目名称(保存的文件夹名称)
'name': 'exp', # 实验名称
'lr0': 0.0003, # 初始学习率
'lrf': 0.0001, # 最终学习率
'freeze': [0, 1, 3, 5] # 冻结某些层
}
# 开始训练
model.train(**train_args)数据集配置文件dataset.yaml内容格式如下:
path: dataset/ # 数据集根目录
train: train/ # 训练集
val: val/ # 验证集
# 类别列表
names:
0: person
1: car
2: bike数据集的目录结构以及标注文件格式如下:
dataset/train
├── images/
│ ├── image1.jpg
│ ├── image2.jpg
│ └── ...
└── labels/
├── image1.txt
├── image2.txt
└── ...
# 数据集文件格式2
dataset/
├── images/
| |——train/
│ | ├── image1.jpg
│ | ├── image2.jpg
│ | └── ...
| |——val ...
└── labels/
|——train/
| ├── image1.txt
| ├── image2.txt
| └── ...
|——val ...
# 标注文件(如image1.jpg)格式
# <class_id> <x_center> <y_center> <width> <height>
# 0 0.370728 0.325532 0.292719 0.391489训练完成后,会在指定的文件夹生成最佳模型best.pt、最后一轮的模型last.pt以及训练过程的数据以及绘制的趋势图像。
加载训练后的模型进行检测:
import os
from ultralytics import YOLO
import cv2
# 加载训练后的模型
model = YOLO('custom_yolov8/exp3/weights/best.pt')
# model = YOLO('/image_identify/models/yolo-v8/yolov8n.pt').load('/image_identify/codes/yolo/custom_yolov8/exp/weights/best.pt')
# 读取图像
image_path = '/image_identify/data/test_for_yolo/test'
image_names = os.listdir(image_path)
images = [cv2.imread(os.path.join(image_path, image_name)) for image_name in image_names]
# 进行目标检测
results = model(images)
# 遍历每张照片
for idx, result in enumerate(results):
boxes = result.boxes
image = images[idx]
image_name = image_names[idx]
for box in boxes:
# 获取边界框坐标
x1, y1, x2, y2 = box.xyxy[0]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
# 获取分类标签和置信度
cls = int(box.cls[0])
conf = float(box.conf[0])
# 获取分类名称
class_name = model.names[cls]
# 在图像上绘制边界框和标签
label = f"{class_name} {conf:.2f}"
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 保存标注后的图像
cv2.imwrite(os.path.join(image_path, image_name.split('.')[0]+'_detect.png'), image) 检测结果示意: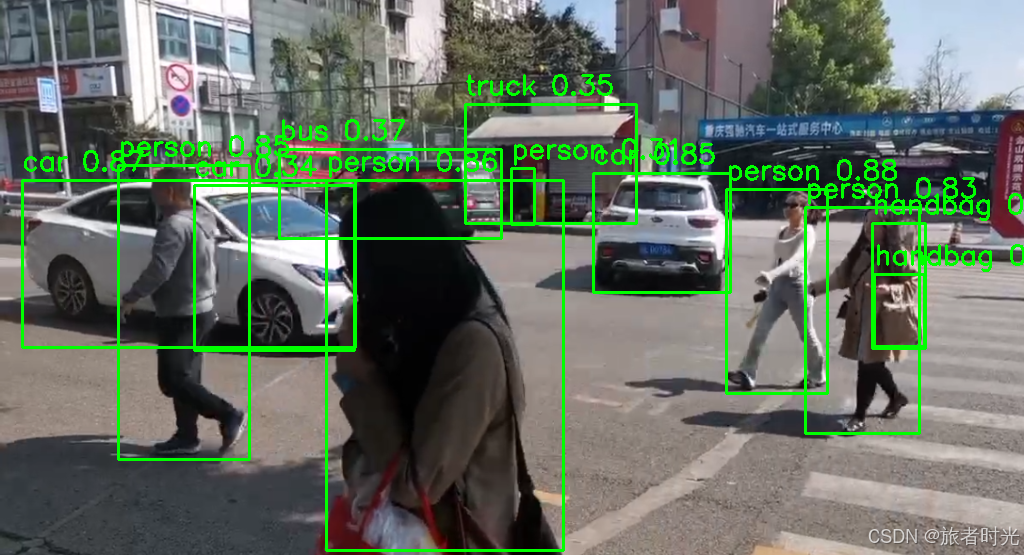
2、SSD、RCNN
基于tensorflow训练SSD和RCNN的步骤完全一样的,区别就是选择不同的配置文件,下载不同的预训练模型。完整的环境搭建、数据准备之前已经总结过:基于tensorflow2的目标检测完整实现过程_tensorflow 目标检测-CSDN博客
这里只介绍如何训练。
# 下载这个models文件夹
git clone https://github.com/tensorflow/models.git
# 将models下面的2个文件夹路径添加到python的环境变量,以便在代码中导入相关模块
export PYTHONPATH=$PYTHONPATH:/your_path/models/research:/your_path/models/research/slim
cd models/research
# 编译protoc的python接口
protoc object_detection/protos/*.proto --python_out=.
# 复制setup.py文件到当前目录
cp object_detection/packages/tf2/setup.py .
# 安装其他依赖
python -m pip install .
# 下载预训练模型,地址https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md
# 选一个你喜欢的模型,然后修改其中pipline.config文件中有关输入数据、模型、标注文件等信息
# 开始训练
python object_detection/model_main_tf2.py \
--pipeline_config_path=path/to/ssd_pipeline.config \
--model_dir=path/to/model_dir \
--num_train_steps=50000 \
--sample_1_of_n_eval_examples=1 \
--alsologtostderr三、展望
1、引入transformer
目前,绝大部分的目标检测算法都是基于卷积网络的。近几年,随着transformer在语言领域大放异彩,也有一些组织尝试将其引入目标检测算法中。DETR、Sparse R-CNN 和 Swin Transformer 等模型结合了就Transformer 和传统目标检测方法的优点,的确提高了检测精度,但推理速度相对较慢,很难做到实时检测。
传统的卷积神经网络(CNN)在局部感受野内提取特征,难以捕捉全局上下文信息。而Transformer 刚好可以通过自注意力机制捕捉图像中不同位置之间的全局依赖关系,能够更好地理解图像的整体结构和目标之间的关系。此外,Transformer 架构可以自然地融合不同尺度的特征(不定长输入),通过自注意力机制在不同尺度的特征图之间建立联系,提高对不同尺度目标的检测能力。
2、大模型
同样,受语言领域大模型的影响,计算机视觉领域也开始进行相关尝试。更大的模型、更多的数据,使得模型能够学习到更底层的事物视觉表示。此外,视觉大模型、语言大模型以及其他方向的大模型正尝试进行融合,未来一定是多模态的智能体形式。


















 4860
4860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









