







一. 逻辑回归
在前面讲述的回归模型中,处理的因变量都是数值型区间变量,建立的模型描述是因变量的期望与自变量之间的线性关系。比如常见的线性回归模型:
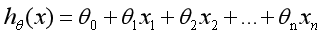
而在采用回归模型分析实际问题中,所研究的变量往往不全是区间变量而是顺序变量或属性变量,比如二项分布问题。通过分析年龄、性别、体质指数、平均血压、疾病指数等指标,判断一个人是否换糖尿病,Y=0表示未患病,Y=1表示患病,这里的响应变量是一个两点(0-1)分布变量,它就不能用h函数连续的值来预测因变量Y(只能取0或1)。
总之,线性回归模型通常是处理因变量是连续变量的问题,如果因变量是定性变量,线性回归模型就不再适用了,需采用逻辑回归模型解决。
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
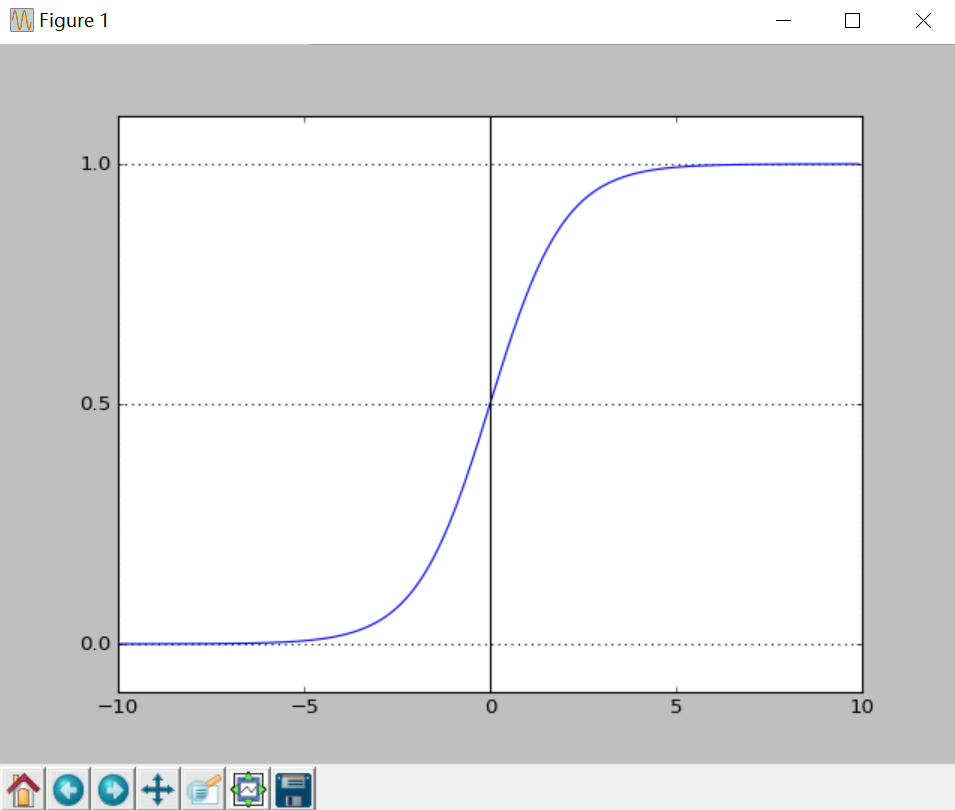
二分类问题的概率与自变量之间的关系图形往往是一个S型曲线,如图所示,采用的Sigmoid函数实现。
PS:如果你觉得这篇文章看起来稍微还有些吃力,或者想要系统地学习人工智能,那么推荐你去看床长人工智能教程。非常棒的大神之作。教程不仅通俗易懂,而且很风趣幽默。点击这里可以查看教程。
这里我们将该函数定义如下:
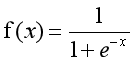
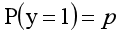
y=0的概率分布公式定义如下:
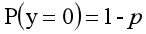
其离散型随机变量期望值公式如下:
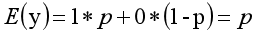
采用线性模型进行分析,其公式变换如下:
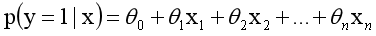
而实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit(p)与自变量之
间存在线性相关的关系,逻辑回归模型定义如下:
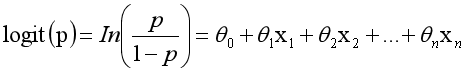
通过推导,概率p变换如下,这与Sigmoid函数相符,也体现了概率p与因变量之间的非线性关系。以0.5为界限,预
测p大于0.5时,我们判断此时y更可能为1,否则y为0。
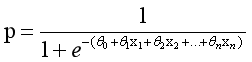
得到所需的Sigmoid函数后,接下来只需要和前面的线性回归一样,拟合出该式中n个参数θ即可。test17_05.py为绘
制Sigmoid曲线,输出上图所示。
-
import matplotlib.pyplot
as plt
-
import numpy
as np
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2915
2915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









