







在生物医学研究领域,特别是流行病学研究中,我们经常需要探索某疾病的发病原因或其影响因素,当因变量是连续型的定量变量且变量与因变量间具有线性关系时我们常采用多重线性回归进行分析,但是在医学研究中的碰到的因变量(结局指标,或称效应指标)通常是分类变量,例如,“生存或死亡”,“发病与不发病”等,并且影响因素(自变量)与其联系更多的是非线性关系。对于这类问题,应用线性回归显然缺乏合理性。
Logistic回归模型属非线性概率回归模型中的一种,其主要适用于因变量为分类变量的回归分析,现已经成为一种常用统计分析方法。根据研究设计类型通常分为条件与非条件Logistic回归。其中条件Logistic回归适用于配对(匹配)病例--对照研究,而非条件Logistic回归主要用于成组或非配对的匹配研究。我们通常把非条件Logistic回归简称为Logistic回归。
由于SPSS 22.0进行二分类的Logistic回归分析时自变量类型不一样,其操作和解释差异有点变化,故本节主要介绍因变量为二分类时的自变量为二分类变量(连续变量时操作一样)时的单因素Logistic回归的 PSS22.0软件详细操作。
单因素Logistic 回归分析:自变量为连续/二分类变量
例1:非甾体抗炎药上市前的研究中,已知可能引起亚临床上消化道出血症状。因此,1980年Strom和Carson开展了大样本上市后 安全性再评价,以确定该药品是否引起上消化道出血不良反应。回顾性跟踪调查的47136例服用该药的患者中,有155例上消化道出血;同期没有服用该药的44634例对照中,有96例上消化道出血,结果见表1。
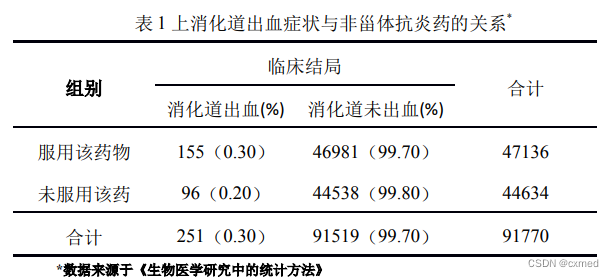
解析:
该资料为回顾性纵向研究资料,其中患者是否服用非甾体抗炎药为处理因素,有2个水平即服用与未服用该药品,是一个二分类的自变量,我们对其进行赋值时,常以X=l表示暴露因素即本例“服用该药品”,X=0表示非暴露因素即本例的“未服用该药品”;而上消化道是否出血为临床结局指标,是二分类的因变量,我们对其进行赋值时,常以Y=l表示阳性事件/观察事件本例为“发生出血症状”,Y=0表示阴性事件/非主要观察事件本例为“未发生出血症状”。
本次研究的主要目的是研究上消化道出血是否与服用该药品有关,即药物和上消化道出血间是否有因果关联性?我们可以通过计算“服用和不服用该药人群中发生消化道出血的症状比不发生出血症状的比值比”即OR来评估该药会引起出血症状的风险关联程度,我们通常选用Logistic回归分析来进行分析。下面常笑医学将给大家讲解如何采用 SPSS20.0 软件实现自变量和因变量为二分类资料的Logistic回归分析。
第一步:变量定义和数据录入
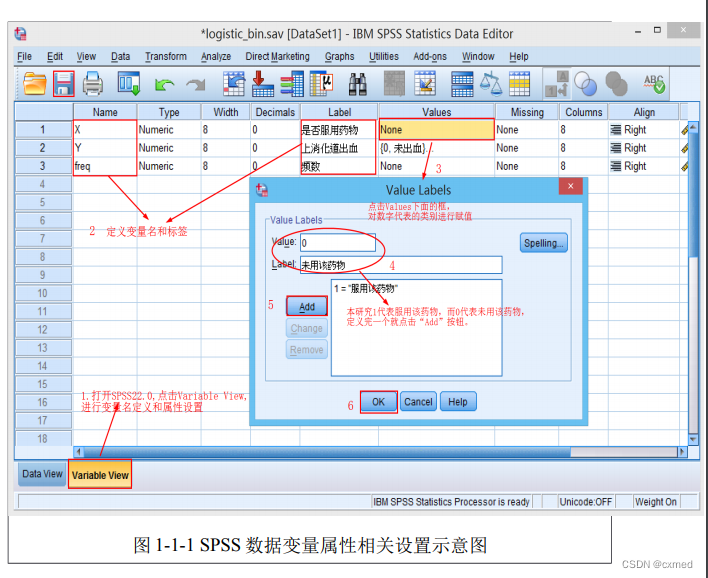
①SPSS 数据变量设置
打开SPSS 软件,点击“Variable View”进入变量视图界面,设置变量,将临床结局变量“上消化道出血”命名为“Y”,其中“1”代表 “出血”,“0”代表“未出血”;“是否服用药物”命名为“X”, 其中“0”代表“未用该药物”,“1”代表“服用该药物”;“频 数”命名为“freq”(为了演示方便本例整理成了汇总的2X2四格表资料形式,原始数据可直接复制黏贴到SPSS里面和下面加权步骤可以省掉);SPSS数据变量设置详见图1-1-1所示。
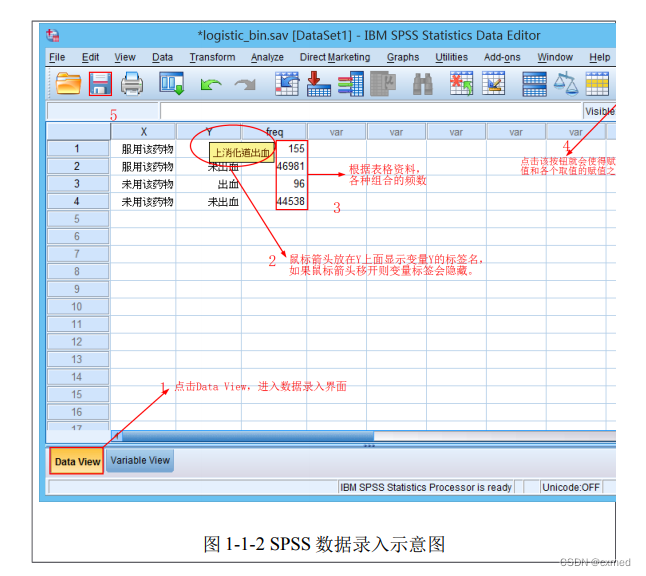
②SPSS数据文件格式
点击“Data View”,返回到数据录入界面,按照要求录入数据或直接在Excel直接复制黏贴过来,详见图1-1-2。
第二步:SPSS软件具体分析过程
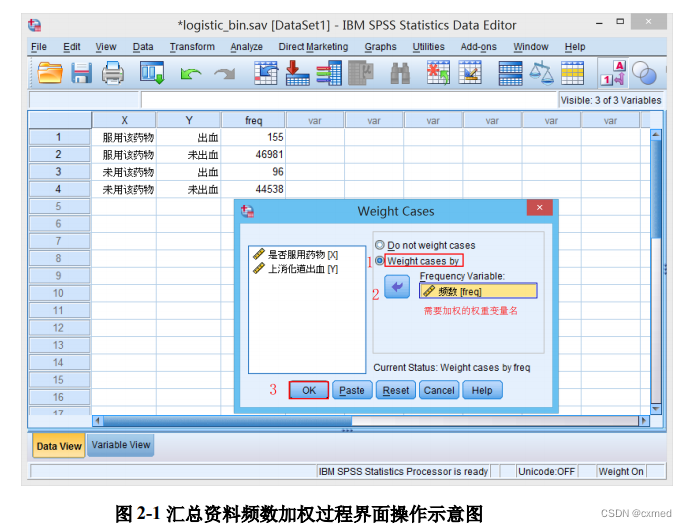
① 个案加权:由于本例是汇总数据,在数据库中每一行的频数代表该组合的实际观察总数,故需要对其进行加权,如果是原始数据即数据库是一行代表一个观察对象的临床转归时可以省去加权这过程而直接进行统计分析。
点击Data菜单中的Weight Cases子菜单,系统弹出“Weight Cases”对话框,点击 Weight casesby,选择“频数[freq]”到Frequency Variable框中进行加权(详见操作示意图,图2-1)。
② 具体的统计分析:点击Analyze菜单中的Regression子菜单,选择Binary Logistic…项, 系统弹出“Logistic Regression”对话框即Logistic回归分析定义窗口(详见操作示意图,图2-2)。
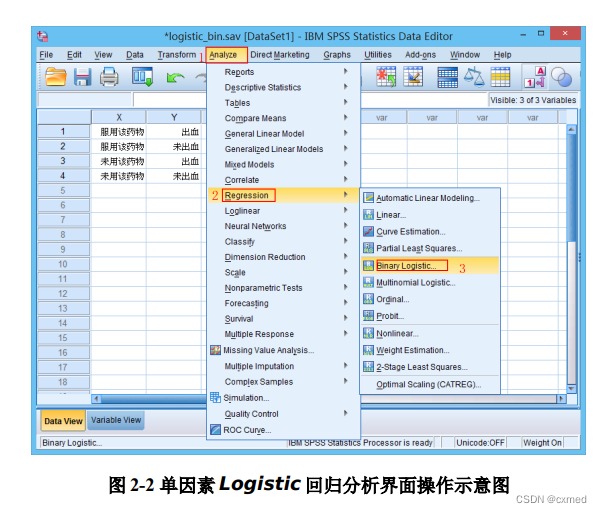
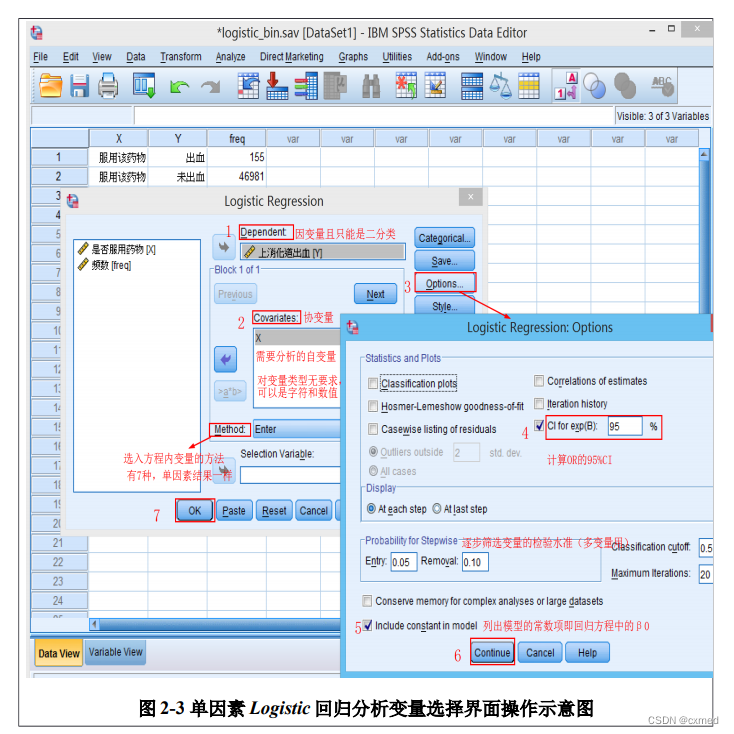
1.点击选中“上消化道出血[Y]”,将其放入到Dependent框中;→2.点击选中“是否服用药物[X]”,将其放入到Covariates框中;→3.点击Options…按钮,弹出“Logistic Regression:Options”对话 框,选择“CI for exp(B)”说明要计算优势比OR的95%CI和 “Include constant in model”说明结果中显示回归方程中的常数项;→4.点击“Continue”按钮返回Logistic回归分析窗口;→5.点击OK按钮,提交系统运行;完成单因素Logistic回归分析(详见操作示意图,图2-3)。
③输出结果:如图2-4所示。SPSS进行Logistic回归分析时会出现多个相关结果,由于本次研究是单因素Logistic回归分析,故我们的结果其实只要 重点分析其中“Block 1: Method=Enter”中的“Variables in the Equation”表格中的结果,其他的稍微了解一下即可。
统计结论:
结果显示,自变量X和常数项Constant有统计 学意义,P均<0.05。其中常数项是拟合模型所有,与本次研究目的相关不大。故主要考虑自变量X的检验结果即“是否服用该药物”,由于是二分类变量,故其OR值的含义可以解释为:相对于赋值较低的研究对象(X=“0”代表未服用该药物的人群),赋值较高的研究对象(X=“1”代表服用该药物的人群)发生风险为是多少(1.531倍)。
如果是连续变量/有序分类变量,其OR值的含义为:自变量每增加一个单位(相当于自变量取值上升一个单位,二分类变量我们 可以看成特殊的连续变量,其只有两个取值)发生结局的风险增加 的倍数(如本例可以这样理解,当自变量 X 取值由 0 上升到1时,其发生出血事件的风险增加了1.531倍)。在论文中我们可以将其整理为表格形式如表2。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









