









2021-0312-6 毕设--基于雨课堂平台的学生在线预习行为数据分析
2021-0312-6 毕设–基于雨课堂平台的学生在线预习行为数据分析
前言:雨课堂是—种致力于为所有教学过程提供免费的数据化、智能化支持的在线学习平台。本章基于雨课堂平台的web程序设计与安全课程在线教学为例, 对教学平台产生的学生在线预习数据进行数据清洗和预处理、聚类分析、相关性分析以及回归性分析。
1 数据清洗及预处理
1.1 在线数据学生预习行为数据集
在对在线学生预习行为分析之前,首先说明数据集的来源是周老师在雨课堂平台获取到的,然后再将这些数据汇总,得到本次数据分析的数据集。下面简单介绍数据集的内容以及字段所表示的具体意义。
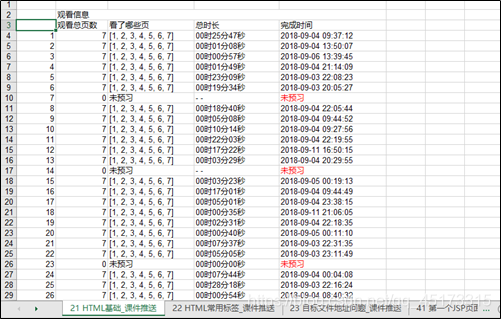
图3.1.1.1 打开的数据集
1、数据集的内容以及字段所表示的具体意义
如图3.1.1.1所示,左下角的sheet表格是第几节课的课题,每个sheet表中的字段都是相同的,分别有字段:ID、观看总页数(共X页)、看了那些页、总时长以及完成时间。ID:与学生信息唯一对应;观看总页数(共X页):你预习的时候预习了几页(此处包含你一秒一页的数据记录);看了那些页:预习内容总共几页,你预习的页码;总时长:从开始预习到完成预习总共花费时间;完成时间:老师从发布预习任务开始到学生完成预习任务结束所花时间,无论你是否预习或是仅仅预习了几页,都会有相应的时刻记录在表中。
2、数据集前期处理
直接从老师哪里获取到的数据源因为格式、类型、重复项等因素是不能直接用于数据分析的,所以我们需要对数据源进行数据清洗及预处理。
数据清洗及预处理步骤与源码:
Win+r进入命令提示行,进入data虚拟环境,输入jupyter notebook后回车,进入交互式环境。使用相应的代码完成任务的具体需求。使用相应的代码完成任务的具体需求。
数据预处理基础命令:
1)导入需要用到的包
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import sqlalchemy
import pymysql
import math
2)读取数据
# d = pd.read_excel('E:\\Program Files\\Tencent\\QQ\\新疆大学\\大三暑假至大四上半学期\\科研实践\\雨课堂数据\\2019-08-28.xls',names=["学号","姓名","观看总页数","已看页数","用时","完成时间"],index_col=False,header=2)
d = pd.read_excel('E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/2019-08-28.xls',index_col=False,header=2)
# read_table(txt) read_csv
d.head(6)
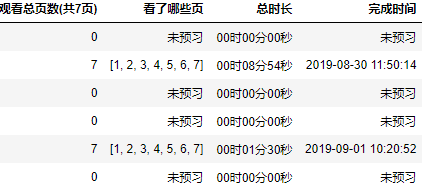
3)查看各列数据类型
# 查看各列数据类型 float,string,int,datetime三种数据python类型
d.dtypes

4)数据信息查看
# 数据规模(维度)
d.shape
输出:(40,6)
# 列名
d.columns
# “总时长”数据维一值
d["看了哪些页"].unique()
d["看了哪些页"].values
pd.isnull(d).any(axis=0)
# 检测是否包含缺失数据
d.isnull().any(axis=1).head()
d.loc[d.isnull().any(axis=1)]
d.isnull().sum(axis=0)
#缺失值填充为0
d0=d.fillna(0,inplace=False)
d0.head()
# 缺失值填充为均值
d0=d.fillna(value={"观看总页数(共7页)":d["观看总页数(共7页)"].mean()},inplace=False)
d0.head()
# 两表的数据合并
d2=pd.concat([d,d1],ignore_index=True)
# 检测是否包含重复数据
d2.duplicated()
# 删除重复数据
d2=d2.drop_duplicates()
d2
5)数据提取与筛选
# 添加列
d["index"]=d.index
d.head()
# 删除指定列
# d=d.drop(columns="index")
d0=d
# 删除指定行
d0=d0.drop(index=[0,1,2,3,4])
d0.head()
6)数据排序
d0.sort_values(by="学号")
d0.head()
# 小到大 ascending=False是大到小
d0.sort_index("index",ascending=False).head()
7)数据汇总
d = pd.read_excel('E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/2019-08-28.xls',index_col=False,header=2)
d0=d.groupby(["学号"])["观看总页数(共7页)"].mean()
d0.head()
8)数据标准化
X=d["观看总页数(共7页)"]
#[0,1]标准化
def f1(x):
x=(x-np.min(x))/(np.max(x)-np.min(x))
return x
f1(X).head()
#Z-score标准化
# 基于均值与方差做数据均值为0方差为1的正态分布
def f2(x):
x=(x-np.mean(x))/np.std(x)
return x
f2(X).head()
9)数据存储
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/data analysis?charset=utf8')
# print(engine)
formlist=pd.read_sql_query('select * from bc1',con=engine)
formlist.dtypes
d.to_sql("bc",con=engine,schema=None,if_exists='fail',index=True,index_label=None,dtype=None) #存储到MySQL数据库中
# y.to_excel("*.xls",sheet_name="sheet1") #以xls格式存储在本地
尝试:
d = pd.read_excel('./1.xls',index_col=False,header=0)
d0=d
d0=d0.drop(columns="Unnamed: 0")
d0.head()
# d0['总时长'] = pd.to_datetime(d0['总时长'], format ='%H:%M:%S')
# d.axes
d0["总时长"].head()
# d0.to_excel("1.xls",sheet_name="sheet1")
d0["用时"] = pd.to_datetime(d0["总时长"],format = "%h:%m:%s",errors = 'coerce')
# d0["用时"]=pd.to_datetime(d0['总时长'])
d0
# d = pd.read_excel('E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/web安全程序设计_2018_92482_3.7.xls',index_col=False,header=0)
# # d1=d
# d1
def read(path):
f = pd.ExcelFile(path)
f.sheet_names # 获取工作表名称
data = pd.DataFrame()
for i in f.sheet_names:
d = pd.read_excel(path, sheet_name=i,header=1)
# status_dict = d['Unnamed: 4'].unique().tolist()
# status_dict1 = d['Unnamed: 2'].unique().tolist()
# d['完成时间数字标签']=d['Unnamed: 4'].apply(lambda x : status_dict.index(x))
# d['已看页数标签']=d['Unnamed: 2'].apply(lambda x : status_dict1.index(x))
data = pd.concat([data, d])
return data
dd=read("E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/web安全程序设计_2018_92482_3.7.xls").head(45)
# names=["编号","观看总页数","已看页数","用时","完成时间"]
# dd.to_excel("E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/处理后的雨课堂预习数据.xls")
dd
数据类型转换:
1)读取所有sheet表,整理字段名称并将所有表合并在同一张表中。
df = pd.read_excel("E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/web安全程序设计_2018_92482_3.7.xls", sheet_name="23 目标文件地址问题_课件推送",header=2,names=["编号","观看总页数","已看页数","用时","完成时间"])
df.head(13)
2)使用df.dtypes命令查看字段数据类型
数据类型转换尝试
d=df
status_dict = d['完成时间'].unique().tolist()
status_dict1 = d['已看页数'].unique().tolist()
d['完成时间数字标签']=d['完成时间'].apply(lambda x : status_dict.index(x))
d['已看页数标签']=d['已看页数'].apply(lambda x : status_dict1.index(x))
d.head(12)
# d["用时转换"]=pd.to_datetime(d["用时"],format='%H时%M分%S秒')
# d=d.drop(columns="用时转换")
# d["用时"].dtypes
# print(d['用时'])
d["用时转换"]=d["用时"].replace("- -","00时00分00秒")
d.head(13)
# print(pd.to_datetime(["00时04分53秒","00时20分11秒","00时04分53秒","00时00分00秒"],format='%H时%M分%S秒'))
d["用时转换"]=pd.to_datetime(d["用时转换"],format='%H时%M分%S秒')
d.dtypes
d['预习时长'] =d['用时转换'].dt.minute
d=d.drop(columns=["已看页数","用时","完成时间","用时转换"])
# # d=d.drop(columns="完成率")
# d=d.drop(columns="用时转换")
d
# d["完成率"]=(d["观看总页数"]/d["观看总页数"].max())
# d["完成率"] = d[u'完成率'].apply(lambda x: format(x, '.2%'))
# d.head(13)
# d.drop(columns="完成率")
d.describe()
d[d['预习时长'].isin([4])]
d['预习时长'].quantile()
a=df.sort_values(by="预习时长")
c=(a['预习时长'].quantile(q=0.75))/2
c=math.ceil(c)
# 向上取整
c
df.head(13)
# df=df.drop(columns=["已看页数","用时","完成时间","完成率"])
# df=df.drop(columns=["用时转换"])
# d.loc["预习时长",2]=6
df.loc[3,"预习时长"]=9
df.head(6)
def f(a):
for i in range(38):
if a.loc[i,"预习时长"]<c:
a.loc[i,"核对总页数"]=math.ceil(a.loc[i,"观看总页数"]/2)
else:
a.loc[i,"核对总页数"]=a.loc[i,"观看总页数"]
return a
b=d
b.head(6)
f(b)
# from sqlalchemy import create_engine
# engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/data analysis?charset=utf8')
# # print(engine)
# formlist=pd.read_sql_query('select * from bc1',con=engine)
# formlist.dtypes
# b.to_sql("已处理雨课堂预习数据",con=engine,schema=None,if_exists='fail',index=True,index_label=None,dtype=None)
# b.to_excel("已处理雨课堂预习数据.xls")
# dd.to_excel("E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/处理后的雨课堂预习数据.xls")
dd=pd.read_excel("E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/雨课堂预习数据集成精简.xls")
dd=dd.drop(columns="Unnamed: 0")
dd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/data analysis?charset=utf8')
f.to_sql("简化集成",con=engine,schema=None,if_exists='fail',index=True,index_label=None,dtype=None)
d=dd.drop_duplicates()
d["用时转换"]=d["总时长"].replace(["- -","总时长"],["00时00分00秒","00时00分00秒"])
d["用时转换"]=pd.to_datetime(d["用时转换"],format='%H时%M分%S秒')
d.head(6)
d['预习时长'] =d['用时转换'].dt.minute
d.head(6)
# if 0<=d.loc[1,"预习时长"]<=1:
# print(666)
len(d)
def fun(d):
a=d.sort_values(by="预习时长")
c=(a['预习时长'].quantile(q=0.75))/2
c=math.ceil(c)
for i in range(len(d)):
if 0<=d.loc[i,"预习时长"]<=1:
d.loc[i,"核对总页数"]= 0
if 1<d.loc[i,"预习时长"]<c:
d.loc[i,"核对总页数"]=math.ceil(d.loc[i,'观看信息']/2)
if d.loc[i,"预习时长"]>=c:
d.loc[i,"核对总页数"]=d.loc[i,"观看信息"]
d["完成率"]=(d["核对总页数"]/d["核对总页数"].max())
d["完成率"] = d[u'完成率'].apply(lambda x: format(x, '.2%'))
return d
3)字段类型转换:上文中可以看到字段看了那些页、总时长以及完成时间都是string型格式,然后我们需要的类型分别是整形int以及时间格式为datetime且这些表都是分散的,不适合整个数据分析,因此就需要对数据集进行数据集成及字段类型转换:
def read(path):
f = pd.ExcelFile(path)
f.sheet_names # 获取工作表名称
data = pd.DataFrame()
for i in f.sheet_names:
d = pd.read_excel(path, sheet_name=i,header=1)
# print(d.columns)
d["Unnamed: 4"]=d["Unnamed: 4"].replace(["未预习","完成时间","未完成预习"],["2018-12-31 00:00:00","2018-12-31 00:00:00","2018-12-31 00:00:00"])
d["Unnamed: 3"]=d["Unnamed: 3"].replace(["- -","总时长"],["00时00分00秒","00时00分00秒"])
d.rename(columns={'Unnamed: 0': 'ID',"观看信息":"观看总页数","Unnamed: 2":"看了哪些页","Unnamed: 3":"用时","Unnamed: 4":"完成时间"},inplace=True)
d=d.drop(columns="看了哪些页")
d=d.dropna(axis=0)
d["完成时间"]=pd.to_datetime(d["完成时间"])
d["用时"]=pd.to_datetime(d["用时"],format='%H时%M分%S秒')
fun(d)
data = pd.concat([data, d])
data=data.drop(columns=["用时","完成时间","及时预习时间间隔"])
data['ID'] = data['ID'].astype("int64")
data['观看总页数'] = data['观看总页数'].astype("int64")
data['刷课次数'] = data['刷课次数'].astype("int64")
data['超时完成次数'] = data['超时完成次数'].astype("int64")
data['预习完成次数'] = data['预习完成次数'].astype("int64")
# d["预习用时"].astype("int")
return data
# Unnamed: 0 观看信息 Unnamed: 2 Unnamed: 3 Unnamed: 4 完成时间数字标签 已看页数标签
# NaN 观看总页数(共7页) 看了哪些页 总时长 完成时间 0 0
此处调用了fun()函数,在之后的文章中会提到。
3、对预习完成次数及提前完成次数算法设计与实现
在先前处理过的基础数据源中,参考价值并没有那么明显,所以需要对之前的数据源进行扩展:
def fun(dd):
for i in range(1,len(dd)+1):
dd.loc[i,"及时预习时间间隔"]=dd.loc[i,"完成时间"]-dd["完成时间"].min()
if dd["用时"].dt.hour[i]==0 and dd["用时"].dt.minute[i]==0 and dd["用时"].dt.second[i]==0:
dd.loc[i,"预习用时"]=0
elif dd["用时"].dt.hour[i]==0 and dd["用时"].dt.minute[i]==0 and dd["用时"].dt.second[i]!=0:
dd.loc[i,"预习用时"]=1
elif 0<dd["用时"].dt.second[i]<30:
dd.loc[i,"预习用时"]=dd["用时"].dt.hour[i]*60+dd["用时"].dt.minute[i]
elif 30<=dd["用时"].dt.second[i]<=59:
dd.loc[i,"预习用时"]=dd["用时"].dt.hour[i]*60+dd["用时"].dt.minute[i]+1
else:
dd.loc[i,"预习用时"]=dd["用时"].dt.hour[i]*60+dd["用时"].dt.minute[i]
a=dd.sort_values(by="预习用时")
c=math.ceil(a['预习用时'].quantile(q=0.5))/2
# for i in range(1,len(dd)+1):
if dd.loc[i,"预习用时"]==0:
dd.loc[i,"刷课次数"]=1
# dd.loc[i,"预习次数"]=1
elif 0<dd.loc[i,"预习用时"]<c:
dd.loc[i,"刷课次数"]=1
elif c<=dd.loc[i,"预习用时"]<90:
dd.loc[i,"刷课次数"]=0
else:
dd.loc[i,"刷课次数"]=1
if dd.loc[i,"刷课次数"]==1:
dd.loc[i,"超时完成次数"]=0
elif dd["及时预习时间间隔"].dt.days[i]<=3:
dd.loc[i,"超时完成次数"]=1
else:
dd.loc[i,"超时完成次数"]=0
if dd.loc[i,"刷课次数"]==1:
dd.loc[i,"预习完成次数"]=0
elif dd.loc[i,"观看总页数"]==dd["观看总页数"].max():
dd.loc[i,"预习完成次数"]=1
else:
dd.loc[i,"预习完成次数"]=0
return dd
其中,对刷课次数这一字段进行处理时,存在预习用时的阈值设定。决定阈值的原理是:因为需要普遍性,所以我们取到预习用时的中位数,但是这样会出现近一半同学会在本章存在刷客行为,考虑到这点,阈值在之前的基础之上再对该值向上取整之后取一半,如此就完成了预习用时这块阈值的设置。
4、数据统计集成结果

使用f.loc[f.isnull().any(axis=1)]命令查看数据空值情况:

2 学生预习行为特征的聚类分析及算法优化
聚类分析:
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
from sklearn.cluster import KMeans
from sklearn.cluster import Birch
import warnings
warnings.filterwarnings("ignore")
#读取文件
datafile = u'E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/统计汇总.xls'#文件所在位置,u为防止路径中有中文名称,此处没有,可以省略
outfile = u'E:\Program Files\Tencent\QQ\新疆大学\大三暑假至大四上半学期\科研实践\雨课堂数据\聚类\聚类.xls'#设置输出文件的位置
data = pd.read_excel(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件则用read_csv
d = DataFrame(data)
d = d.drop(columns=["ID","预习总用时","刷课总次数","预习未完成总次数"])
# ,"观看总页数","预习总用时","预习未完成总次数"
f = d[["观看总页数","超前完成总次数"]]
f['观看总页数'] = f['观看总页数'].astype("float")
# f['预习完成总次数'] = f['预习完成总次数'].astype("float")
f['超前完成总次数'] = f['超前完成总次数'].astype("float")
#聚类
mod = KMeans(n_clusters=3, n_jobs = 4, max_iter = 500,init='random')#聚成3类数据,并发数为4,最大循环次数为500
mod.fit_predict(d)#y_pred表示聚类的结果
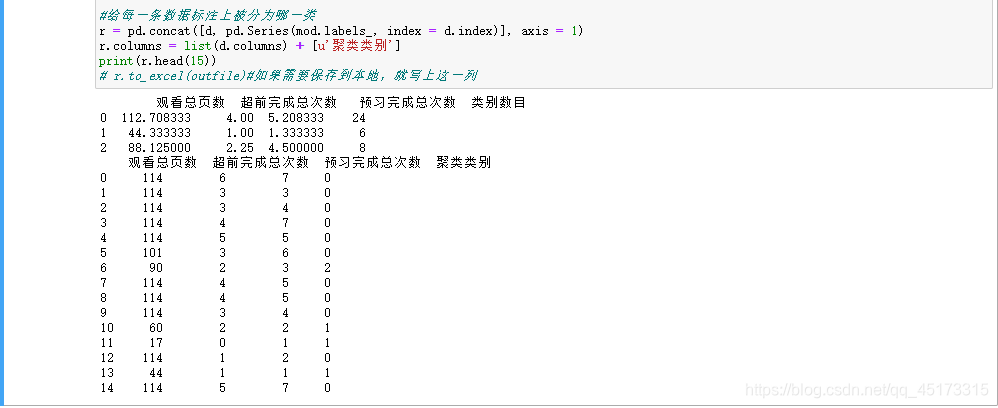
#聚成3类数据,统计每个聚类下的数据量,并且求出他们的中心
r1 = pd.Series(mod.labels_).value_counts()
r2 = pd.DataFrame(mod.cluster_centers_)
r = pd.concat([r2, r1], axis = 1)
r.columns = list(d.columns) + [u'类别数目']
print(r)
#给每一条数据标注上被分为哪一类
r = pd.concat([d, pd.Series(mod.labels_, index = d.index)], axis = 1)
r.columns = list(d.columns) + [u'聚类类别']
print(r.head(15))
# r.to_excel(outfile)#如果需要保存到本地,就写上这一列
#K-means聚类结果可视化
import matplotlib.pyplot as plt
datafile = u'E:/Program Files/Tencent/QQ/新疆大学/大三暑假至大四上半学期/科研实践/雨课堂数据/统计汇总.xls'#文件所在位置,u为防止路径中有中文名称,此处没有,可以省略
outfile = u'E:\Program Files\Tencent\QQ\新疆大学\大三暑假至大四上半学期\科研实践\雨课堂数据\聚类\聚类.xls'#设置输出文件的位置
d = pd.read_excel(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件则用read_csv
da = d.drop(columns=["ID","预习总用时","刷课总次数","预习未完成总次数"])
# print(da.head())
ts = TSNE()
ts.fit_transform(da)
ts = pd.DataFrame(ts.embedding_, index = r.index)
# print(ts)
# 绘制聚簇中心
import time
r = time.time()
kmeans = KMeans(n_clusters=3,max_iter = 500,init='random')
kmeans.fit(ts)
print("随机聚类花费时间为:",time.time()-r)
print(kmeans.cluster_centers_)
r = pd.concat([da, pd.Series(mod.labels_, index = d.index)], axis = 1)
r.columns = list(da.columns) + [u'聚类类别']
print(r.head(11))
print(ts[r[u'聚类类别'] == 1])
colors = ['r', 'g', 'b']
for i in range(3):
p=ts[r[u"聚类类别"]==i]
plt.scatter(p[0],p[1], c=colors[i],label="Cluster {}".format(i))
# plt.scatter(kmeans.cluster_centers_[:, 0],kmeans.cluster_centers_[:, 1], s=66, color='black',label='Centers')
plt.title("Cluster With Ground Truth")
plt.legend()
# # f.savefig("9485OS_03-17")
聚类结果:

¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
干饭了,干饭了。
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥


















 2092
2092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











