







 Weisfeiler-Lehman(WL)算法是一种用于图的同构测试的方法,通过不断迭代更新节点标签来区分不同结构的图。算法包括标签扩展、压缩和重标签过程,其在一维形式下与GNNs有相似之处。文章介绍了WL测试的步骤、一维WL算法的执行流程,以及General Weisfeiler-Lehman Kernels,包括Subtree、Edge和Shortest Path Kernel的计算方法。
Weisfeiler-Lehman(WL)算法是一种用于图的同构测试的方法,通过不断迭代更新节点标签来区分不同结构的图。算法包括标签扩展、压缩和重标签过程,其在一维形式下与GNNs有相似之处。文章介绍了WL测试的步骤、一维WL算法的执行流程,以及General Weisfeiler-Lehman Kernels,包括Subtree、Edge和Shortest Path Kernel的计算方法。
Weisfeiler-Lehman 算法
Weisfeiler-Lehman(WL)算法
The Weisfeiler-Lehman Test of Isomorphism
- 图核使用来自 W e i s f e i l e r − L e h m a n Weisfeiler-Lehman Weisfeiler−Lehman同构检验的概念,更具体地讲是其一维变体,也称为“朴素顶点修饰”
- 该算法的关键思想是通过对相邻节点的节点标签排序后的集合来扩展节点标签,并将这些扩展后的标签压缩为新的短标签
- a l p h a b e t alphabet alphabet Σ Σ Σ必须足够大才能使 f f f具内射性。 对于两个图, ∣ Σ ∣ = 2 n |Σ| = 2n ∣Σ∣=2n个满足条件。

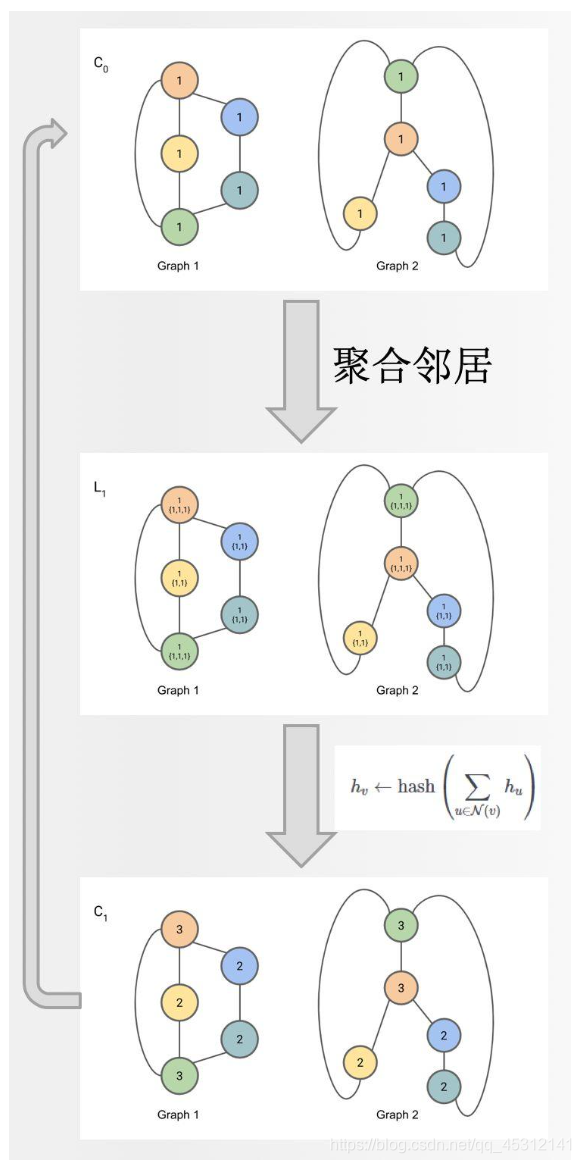
- ( a ) (a) (a)网络中每个节点有一个 l a b e l label label,如图中的彩色的 1 , 2 , 3 , 4 , 5 1,2,3,4,5 1,2,3,4,5
- ( b ) (b) (b)标签扩展:做一阶广度优先搜索,即只遍历自己的邻居。比如在图 ( a ) (a) (a)网络 G G G中原 ( 5 ) (5) (5)号节点,变成 ( 5 , 234 ) (5,234) (5,234),这是因为原 ( 5 ) (5) (5)节点的一阶邻居有 2 , 3 和 4 2,3和4 2,3和4
- ( c ) (c) (c)标签压缩:仅仅只是把扩展标签映射成一个新标签,如 5 , 234 = > 13 5,234 => 13 5,234=>13
- ( d ) (d) (d)压缩标签替换扩展标签
- ( e ) (e) (e)数标签:比如在 G G G网络中,含有 1 1 1号标签 2 2 2个,那么第一个数字就是 2 2 2。这些标签的个数作为整个网络的新特征
算法:
假设要测试同构的两张图为 G G G和 G ’ G’ G’,那么在结点 v v v的第 i i i次迭代里,算法都分别做了四步处理:标签复合集定义、复合集排序、标签压缩和重标签

- W L t e s t WL\ test WL test的复杂度是 O ( h m ) O(hm) O(hm),其中h为 i t e r a t i o n iteration iteration次数, m m m是一次 i t e r a t i o n iteration iteration里 m u l t i s e t multiset multiset的个数
一维的 W e i s f e i l e r − L e h m a n Weisfeiler-Lehman Weisfeiler−Lehman如下所示:

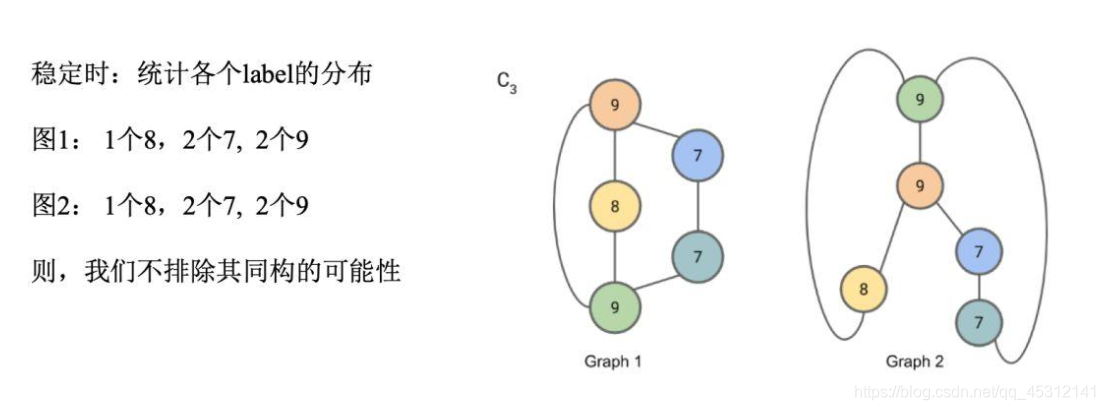
稳定后,统计两张图的 l a b e l label label的分布,如果分布相同,则一般认为两张图时同构的。
注意:我们可以发现, W L t e s t WL\ test WL test方法的步骤和 G N N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2078
2078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









