






A Systematic Survey of Molecular Pre-trained Models
目录
2. Autoregressive Modeling (AM)
3. Masked Components Modeling (MCM)
6. Replaced Component Detection (RCD)
8. Knowledge-Enriched Pre-training
1. Molecular Property Prediction (MPP)
3. Drug-Drug Interaction (DDI)
4. Drug-Target Interaction (DTI)
五、Conclusions and Future Outlooks
1. Understanding Theoretical Groundings
2. Towards Better Knowledge Transfer
3. Seeking Better Encoder Architectures and Pre-Training Tasks
4. Seeking More Reliable and Realistic Benchmarks for Fair Evaluations
5. Pursuing Broader Impact in Diverse End Tasks
总结
今天给大家介绍来自浙江大学于2022年10月29日发表在arXiv上的预印本《分子预训练模型综述》。从头开始训练深度神经网络通常需要足够的标记分子,而在现实场景中获取这些分子的成本很高。为了缓解这一问题,受NLP中“预训练-微调”范式成功的启发,人们投入了大量精力研究分子预训练模型(MPMs),在这种模型中,神经网络使用大规模的无标记分子进行预训练,然后针对不同的下游任务进行微调。作者提供了一个系统的预训练模型的分子表征综述。首先,作者强调了训练深度神经网络进行分子表征的局限性。接下来,作者从分子描述符、编码器结构、预训练策略和应用等几个关键角度系统地回顾了该主题的最新进展。最后,作者指出了几个挑战,并讨论了未来有前途的研究方向。
一、Introduction
基于序列(LSTM,Transformer)和基于图(GNN)的方法都特别关注在监督下的分子表示。这种学习范式往往需要足够的标记分子数据,这阻碍了其在实践中的广泛应用,主要有以下两个原因:
- Scarcity of labeled data:特定任务的分子标签可能非常稀缺,因为数据标签通常需要耗时和资源昂贵的湿实验。
- Poor out-of-distribution generalization:在许多现实场景中,学习具有不同大小或官能团的分子需要分布外泛化。例如,当一个人想要预测一个新合成的分子的化学性质时,它与训练集中的所有分子都不同。然而,据观察,目前的神经网络不能很好地外推到分布外的分子。
受NLP中近期成功的预训练语言模型(PLMs)的启发,MPMs被引入来从大量未标记的分子中学习通用分子表征,并使用任务特定的标记数据对下游任务进行微调。图1显示了常规流程。一开始,研究人员采用基于序列的预训练策略对基于序列的分子数据,如SMILES。一种典型的策略是预训练编码器来预测像BERT这样的随机掩码标记。该系列包括ChemBERTa、SMILES-BERT、Molformer等。最近,分子图(2D和3D)的预训练也逐渐步入人们的视野。其中2D图的预训练主要利用图拓扑的结构信息,3D图的预训练主要利用三维构象信息。例如,Hu等人提出了两种预训练策略(1)掩码原子或边属性并预测被掩码属性(2)预测通过取中心原子周围的K-hop邻居获得的上下文子图。You等人建议使用对比学习最大化成对分子图之间的一致性。Zaidi等人证明,对构象空间进行去噪有助于学习分子力场。这项工作的贡献可以概括为以下四个方面:
- Structured taxonomy:如图2所示,作者贡献了一个结构化的分类法来提供该领域的广泛概述,它从四个角度对现有的工作进行了分类:分子描述符、网络结构、预训练策略和应用。
- Current progress:根据分类法,系统地描述了分子预训练模型的研究现状。
- Abundant resources:收集了丰富的资源,包括开源的MPM、可用的数据集和一个重要的论文列表,网址。
- Future directions:讨论了现有研究的局限性,并提出了几个有前途的研究方向。
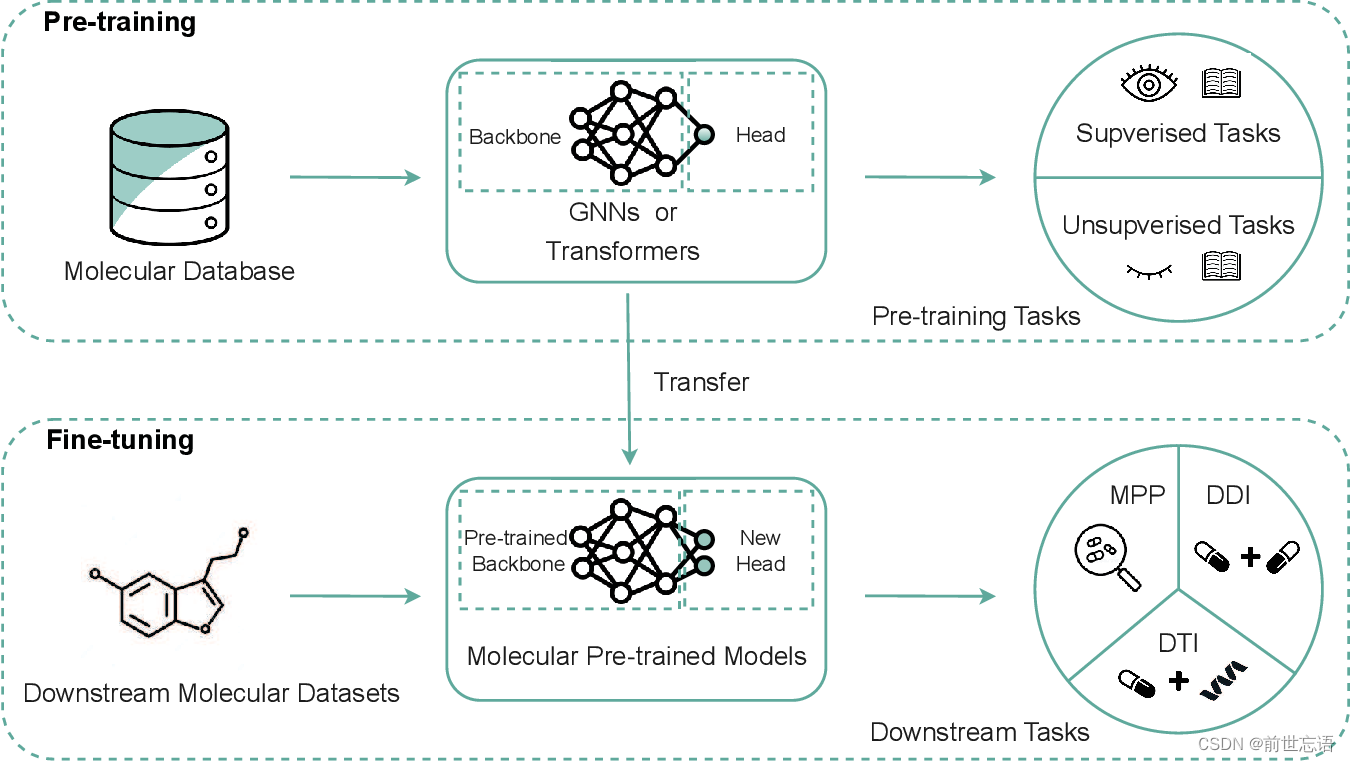 图 1
图 1
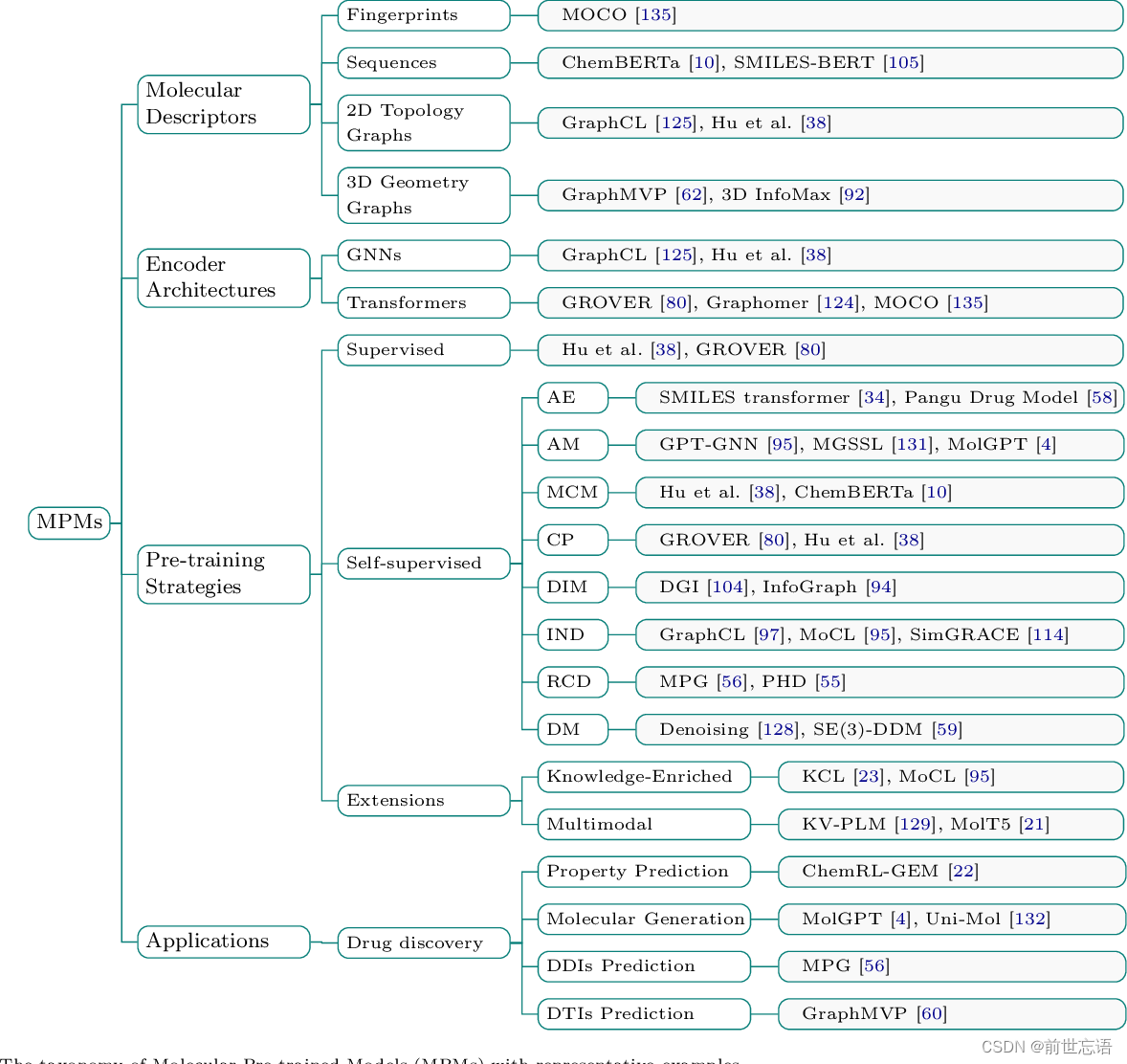 图 2
图 2
二、Molecular Descriptors
- 指纹:分子指纹用二元串来描述分子中特定亚结构的存在或缺失。例如,PubChemFP编码了881个结构键类型,对应于PubChem数据库中所有化合物片段的子结构。Morgan指纹为每个原子分配数字标识符,并使用哈希函数在相邻原子之间迭代更新这些原子描述符。
- 序列:由于其通用性和可解释性,最常用的分子顺序描述符是SMILES。每个原子都表示为各自的ASCII符号。化学键、分支和立体化学在SMILES串中用特定的符号表示。然而,SMILES字符串的大部分并不对应有效分子。为了解决这个问题,最近开发了一个基于字符串的分子描述符SELFIES,这样每个SELFIES字符串都表示一个有效的分子。
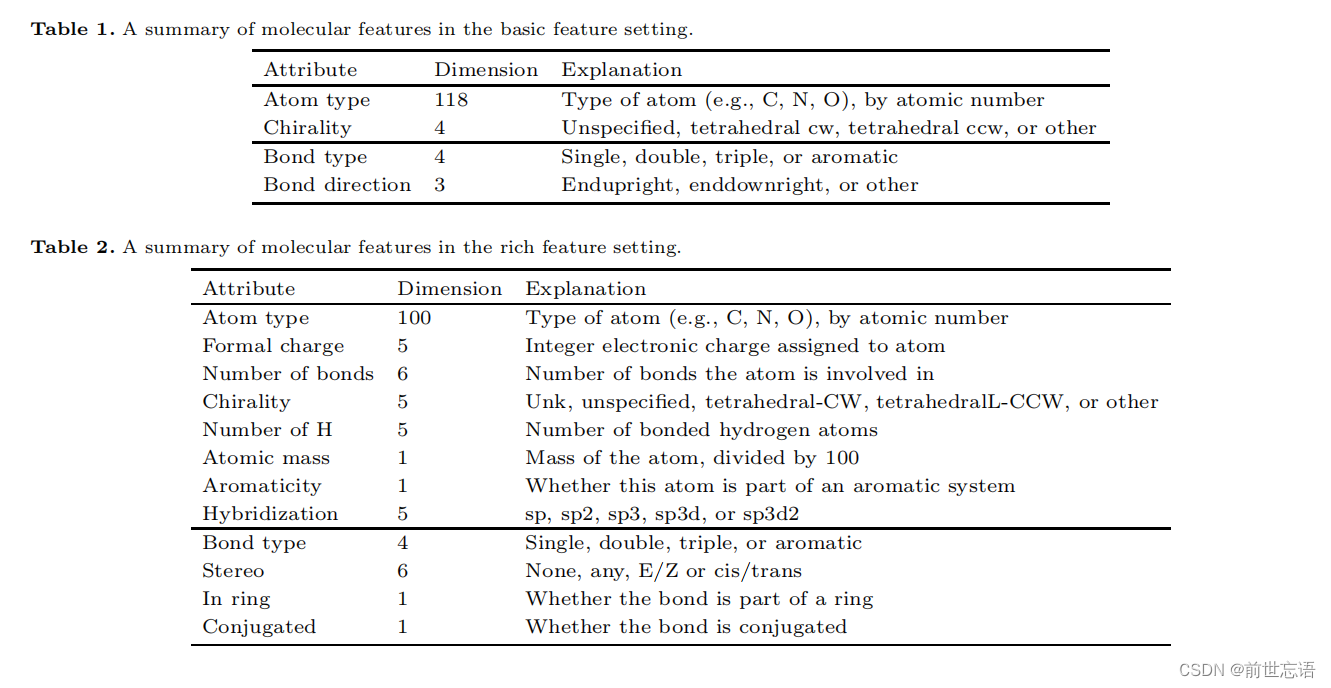
- 2d图:分子可以自然地表示为二维图,原子作为节点,键作为边。此外,每个节点和边缘还可以携带信息特征向量,例如表示原子/键类型。尽管2D图被证明是分子的自然描述符,但这种描述符有一些限制。例如,对于两个手性不同的分子图,当原子和键类型作为唯一特征时,大多数主流的图神经网络无法区分它们。为了用更有意义的特征丰富图形表示,通常包含两个特征集:基本特征和丰富特征。前者是节点和键特征的最小集合,可以清楚地描述分子的二维结构,后者包括附加的原子特征,如芳香性和杂化,以及键特征,如环信息。作者将这两个特征集分别总结为表1和表2。
- 3d图:3D分子几何图形表示三维空间中每个原子的空间排列。具体来说,它包括具有原子类型和原子坐标的原子列表。与关注拓扑信息的2D分子图不同,3D几何图形编码构象信息,这对许多分子性质,特别是量子性质至关重要。此外,也可以直接推断三维空间中给定的分子几何构型的手性。
三、Pre-training Strategies
作者在表3中总结了几种代表性的预训练策略。

1. AutoEncoders (AE)
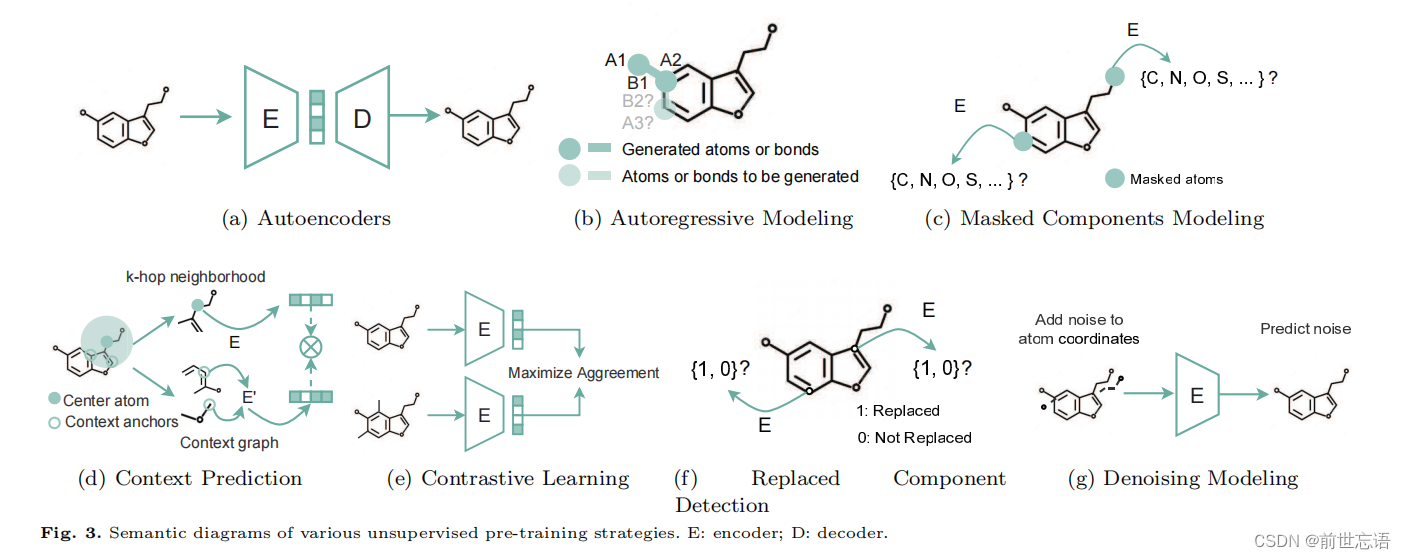
用自编码器重构分子(图3a)作为学习分子表征的自监督目标。分子重构中的预测目标是给定分子的部分结构,如原子子集或化学键的属性。例如,Honda等人建立了一个基于Transformer的编码器-解码器来重构SMILES所代表的分子。受自编码器在其他领域成功的启发,图自编码器也被广泛采用,通过重建原始分子图的邻接矩阵来预训练分子图。尽管自编码器可以学习有意义的分子表示,但它们无法捕捉分子间的关系,这限制了它们的性能。
2. Autoregressive Modeling (AM)
自回归模型将输入的分子分解为子序列,然后根据之前的子序列去预测下一个子序列。遵循GPT在预训练语言模型方面取得巨大成功的思想,MolGPT预训练一个Transformer,以自回归预测SMILES字符串中的下一个token。对于分子图,GPT-GNN按照一系列步骤重构分子图(图3b),而图自编码器则一次性重构整个图。特别是,给定一个节点和边随机掩码的图,GPT-GNN每次生成一个被掩码的节点及其边,并使每次迭代生成的节点和边的可能性最大化。然后,迭代生成节点和边,直到生成所有被掩码的节点。类似地,MGSSL生成分子图motif,而不是单个原子或键。然而,自回归预训练过程的计算成本较高。
3. Masked Components Modeling (MCM)
MCM(图3c)类似于掩码语言模型(MLM),它从输入语句中随机掩码标记,然后训练模型用其余标记预测掩码标记,MCM(图3c)首先掩码分子的某些部分(如原子、键、子图等),然后训练模型预测它们。对于基于序列的预训练,按照ChemBERTa、SMILES- bert和Molformer中的掩码语言模型对SMILES或SELFIES中的一些字符进行掩码,然后根据输入掩码后的SMILES或SELFIES的Transformer恢复掩码字符。对于分子图预训练,Hu等提出了属性掩蔽,其中输入的原子/化学键属性被随机掩码,并对GNN进行预训练以预测这些属性。此外,GROVER尝试预测掩码图,以捕获分子图中的上下文信息。这些掩码方法尤其适用于注释丰富的分子图。例如,掩码节点属性(原子类型)使GNN能够学习简单的化学规则,如价,以及更复杂的化学现象比如官能团的电子或空间效应。此外,与自回归相比。MCM根据周围环境预测被掩码的成分(原子/键),而自回归模型仅根据出现在它们之前的序列预测它们。因此,MCM允许MPM全面捕获化学规律。然而,使用MCM的预训练模型的输入往往包含下游任务中从未出现过的人工符号,这造成了预训练和微调阶段之间的差距。这一关键问题在分子预训练中仍未得到解决。
4. Context Prediction (CP)
上下文预测(图3d)被提出以上下文感知的方式捕获分子/原子的语义。例如,Hu等人使用分子中的子图,用GNN预测其周围的上下文结构。GROVER试图在一些局部子图中预测目标原子/键的上下文感知属性。这里的属性是目标原子/键周围的一些原子键计数项。尽管CP很有效,但它需要一个辅助模型来将上下文编码为一个固定的向量,这为大规模的预训练引入了更多的计算开销。
5. Contrastive Learning (CL)
对比预训练已成为分子表征最流行的策略之一。根据对比粒度(如分子级或子图级),可将CL分为Deep InfoMax (DIM)和Instance Discrimination (IND)两类。
DIM最初是为图像提出的,通过最大化图像表示和图像局部区域之间的相互信息来学习表示。对于分子图,InfoGraph首先提出通过最大化不同粒度的分子与子图级表示之间的互信息来获得有表达性的分子表示。
IND(图3e)是最受欢迎的预训练策略之一,其目的是通过将增强的分子推到靠近锚点分子(正对)的地方,而远离其他分子(负对)来学习分子表示。对于分子表示,GraphCL及其变体为用图表示的分子水平预训练提出了各种先进的增强策略。最近,一些研究尝试通过分别丢弃负对、参数化互信息估计、甚至分子图数据增强来简化上述对比预训练框架。此外,最近的一些研究也使相同分子的不同描述符之间的一致性最大化,并排斥不同的描述符。具体来说,SMICLR联合预训练一个图编码器和一个SMILES编码器来执行对比学习目标。MM-Deacon利用两个独立的Transformer来学校分子的SMILES与IUPAC表征,之后使用对比目标来最大化相互信息,判断SMILES和IUPAC是否来自同一分子,并区分来自不同分子的SMILES和IUPAC。GeomGCL采用双视图几何消息传递神经网络(GeomMPNN)对分子的2D和3D图形进行编码,并设计几何图形对比目标。
虽然分子对比预训练已经取得了很好的效果,但仍有一些关键问题。
- 在分子增强过程中难以保持语义。现有的解决方案通过人工试错,繁琐的优化,或通过昂贵的领域知识的指导来选择合适的扩展,这是次优的。
- 在分子对比学习中,拉近相似分子的距离可能并不总是正确的。例如,在分子活性悬崖的情况下,相似的分子具有完全不同的性质,仍然将它们的嵌入拉近的对比目标可能不合适。对于分子预训练,是否有更合适的增广框架或无增广框架还有待探索。
- 对比框架将其他所有分子图拒之门外,不管它们的真实语义如何,由于最近一项工作中主张的假阴性问题,这将不利于排斥性质相似的分子,并削弱性能。
6. Replaced Component Detection (RCD)
替换成分检测(图3f)被提出作为输入分子随机排列的有效预训练任务。具体来说,PHD将分子分解成两个部分,并通过不同分子中单个部分的随机组合排列分子结构。然后训练编码器来判断这两种成分是否来自同一分子。尽管RCD可以帮助MPM捕获分子结构下的内在模式,但它本质上是一个二元分类任务,比MCM更具挑战性。因此,在这种简单的预训练任务下,预训练过程会迅速收敛到一个高值,从而使预训练模型捕获的可转移知识更少,从而影响了对新任务的泛化或适应能力。
7. Denoising Modeling (DM)
受Noisy Nodes的启发,Noisy Nodes将去噪(图3g)作为提高性能的辅助任务,最近的一项工作将噪声添加到3D几何的原子坐标中,并对编码器进行预训练以预测噪声。他们进一步证明了分子预训练中的去噪目标近似等价于学习一个分子力场,揭示了去噪如何帮助分子预训练。同时,考虑到掩蔽原子类型可以通过3D原子位置推断出来,普通的掩码原子类型预测任务可以非常简单。作为补救措施,Uni-Mol设计了一个3D位置去噪预训练任务,在原子坐标中添加噪声,使掩模原子预测的预训练任务更具挑战性,从而鼓励模型学习更多可转移的知识。
8. Knowledge-Enriched Pre-training
MPMs通常从大型分子数据库中学习一般的分子表示。然而,他们通常缺乏领域特定的知识。为了提高MPM的性能,最近的一些研究尝试将外部知识注入MPM中。例如,GraphCL首先指出键扰动(键的添加或删除)在概念上与领域知识不相容,而且在经验上对化合物的对比预训练没有帮助。因此,他们避免采用键扰动来进行分子图增强。
为了更明确地将领域知识融入到预训练中,MoCL提出了一种新的分子增强算法,称为子结构替换,将分子的有效子结构替换为生物电子等排体,该生物电子等排体产生一个与原分子具有相似物理或化学性质的新分子。最近,为了捕捉具有共同属性但没有化学键直接连接的原子之间的相关性,KCL构建了一个化学元素知识图来总结化学元素之间的微观联系,并为分子表示学习贡献了一个新的知识增强对比学习框架。此外,MGSSL首先利用BRICS算法推导出语义意义的motif,然后预训练编码器以自回归方式预测motif。ChemRL-GEM提出利用分子几何信息增强分子图预训练。设计了一种基于几何的图神经网络和几种几何级的自监督学习策略(键长预测、键角预测和原子距离矩阵预测)来捕获预训练时的分子几何知识。Zhu等人提出使用对比目标最大化四种分子描述符的视图嵌入与其聚合嵌入之间的一致性。
9. Multimodal Pre-training
分子还可以使用其他形式描述,包括图像和生化文本。受CV和NLP领域多模态预训练进展的启发,最近的一些工作对分子进行了多模态预训练。
例如,KV-PLM首先将SMILES和生化文本变成token。然后,他们随机掩码部分标记,并预训练编码器恢复掩码token。MolT5首先掩盖了一些丰富的SMILES和分子的生化文本描述的部分,然后预训练Transformer模型来预测被掩盖的部分。这样,这些预训练的模型既可以生成SMILES字符串,也可以生成生化文本,这对于文本引导的分子生成和分子标题(生成分子描述性文本)尤其有效。此外,MICER采用了一种基于编码器-解码器的预训练框架用于分子图像标题(生成分子图像的描述性文本)。具体来说,它们将分子图像作为预训练的编码器(即CNN)的输入,然后解码相应的SMILES字符串。上述多模态预训练策略可以提高不同模态间的翻译效果。此外,各种模态可以相互补充,为下游任务组成更完整的知识库。
四、Applications
在表5中,作者总结了在不同应用程序中用于评估MPM的几个广泛使用的数据集。

1. Molecular Property Prediction (MPP)
MPMs可以作为分子编码器来获得新合成药物的表示,这有助于下游分子性质预测任务。MoleculeNet是分子性质预测最常用的benchmark,包括来自PubChem]、PubChem BioAssasy和ChEMBL的70万个分子。分子的性质大致可分为四类:生理、生物物理、物理化学和量子力学。MoleculeNet共有17个数据集,其中FreeSolv、ESOL、MUV、HIV、BACE、BBBP、Tox21、ToxCast、SIDER、Clintox、QM7、QM8、QM9是最常用的MPMs评估数据集。利用MoleculeNet进行分子性质预测可以看作是机器学习中的多标签二元分类或回归任务。最近,引入了一个名为Alchemy的新的量子分子数据集,用于分子性质的多任务学习。
2. Molecular Generation (MG)
分子生成是计算机辅助药物设计的一个长期而有前途的研究课题。然而,列举无限的类药物化学空间在计算上是禁止的。基于机器学习的方法,特别是生成模型,通过缩小搜索空间和提高计算效率,彻底改变了分子生成的前景。目前,MPMs在分子生成方面已经显示出了良好的应用前景。例如,MolGPT采用自回归模拟分子生成过程的预训练策略,在生成有效的、唯一的和新颖的分子方面显示出有前景的结果。此外,多模态分子预训练技术的出现使从描述性文本生成分子成为可能(文本到分子生成)。此外,以生成分子三维构象为目标的分子构象生成具有广泛的应用,如蛋白质-配体结合位姿预测。传统的基于分子动力学或马尔可夫链蒙特卡罗的方法往往计算成本高,特别是对于大分子。三维几何增强MPMs在下游的构象生成任务中表现出显著的优势,因为它们可以捕获二维分子图和三维构象之间的必然关系。评价分子生成的代表性数据集包括ZINC , ChEMBL和QM9。
3. Drug-Drug Interaction (DDI)
药物-药物相互作用预测是药物研发过程中必不可少的一个阶段,它可能导致药物不良反应,损害健康甚至导致死亡。此外,准确的DDI预测有助于药物推荐。因此,DDI预测是市场批准前监管调查不可或缺的一部分。从机器学习的角度来看,DDI预测可以看作是将联合药物的影响分为协同作用、相加作用和拮抗作用三类的任务。现有的分子预训练工作,如MPG,将DDI预测作为评估MPM有效性的下游任务。常用的DDI预测数据集包括TWOSIDES2和DeepDDI3,提取自DrugBank。
4. Drug-Target Interaction (DTI)
药物-靶标相互作用预测是药物发现早期阶段的一项关键任务,其目的是确定具有与特定蛋白质靶标结合效力的候选药物。此外,当一种新疾病出现时,最佳的治疗选择是回收已批准的药物,因为它们的可用性和已知的安全性,即药物再利用。因此,DTI预测可以减少进一步的药物发现需求,降低药物安全风险。当利用MPMs实现DTI时,我们需要同时考虑分子编码器和目标编码器,并预测DTI的结合亲和力。在这种情况下,MPMs可以直接作为药物编码器,预先训练的模型为分子编码器提供了良好的初始化。然后,对分子编码器和目标编码器进行协同训练,实现DTI预测任务。现有的工作,如MPG遵循上述设置来推进DTI预测。DTI广泛使用的数据集包括Human和Caenorhabditis elegans。
五、Conclusions and Future Outlooks
1. Understanding Theoretical Groundings
尽管MPM已经在各种下游任务中证明了它们的能力,但对MPM的严格理论分析一直滞后。对于研究和产业界来说,理解MPM学到的关键机制以及它如何提高不同下游任务的性能至关重要。然后,我们可以更好地利用MPM的力量,在现实应用中放大优点,避免缺点。例如,最近的一项研究观察到,一些自监督图预训练策略并不总是比非预训练策略带来统计上显著的优势。需要进一步的工作来充分理解各种分子预训练目标成功或失败的理论基础。
2. Towards Better Knowledge Transfer
在预训练策略方面,MPM付出了巨大的努力。然而,如何利用这些预训练的模型来提高下游任务的性能还有待进一步研究。微调是一种使知识适应各种下游任务的主要技术,但它面临着灾难性遗忘[的问题,这意味着在微调过程中MPM经常忘记他们所学的知识。为了缓解这一问题,Han等人在微调阶段对各种预训练任务与目标任务进行自适应选择和组合,以实现更好的自适应。该策略保留了自监督预训练任务获取的足够知识,提高了分子预训练转移学习的有效性。然而,该策略假设MPM的预训练任务对下游用户可用,这在许多现实场景中是不实际的。为了更好地从预训练的模型中转移知识,还需要做大量的工作。
3. Seeking Better Encoder Architectures and Pre-Training Tasks
正如之前的研究所揭示的,在分子图预训练中应用强大的图注意网络(GAT)将极大地削弱预训练性能。目前还不清楚为什么会出现这种现象,以及什么样的GNN架构将是最适合分子图预训练的选择。另一方面,对于大规模分子图预训练,如何将消息传递方案作为统一的编码器集成到Transformer中,值得关注。此外,正如在之前中指出的,一些具有代表性的预训练策略仍然充满了各种各样的问题。例如,MCM在预训练和微调阶段之间造成了一个不受欢迎的间隙,因为它经常包含在下游任务中从未出现过的人工符号。预计会有更多的努力来缓解这些问题。
4. Seeking More Reliable and Realistic Benchmarks for Fair Evaluations
现有的MPM评价方案规模有限,使得对这些基准的评价对于了解MPM的实际进展不太可靠。以流行的量子特性预测数据集QM9为例,现有的MPM已经取得了很高的性能。进一步的竞争和在这些基准上投入的资源可能会对研究问题造成有限的影响。另一个例子是MoleculeNet,它包含了一些用于ADMET分子特性预测的昂贵数据集。然而,由于这些数据集非常小,同一模型的性能甚至在不同的随机种子下有很大的差异。此外,另一个迫切需要是在现实环境下进行基准测试,例如,考虑scaffold的分布外泛化,我们根据scaffold(分子子结构)拆分分子。正如在现实世界中,研究人员总是寻求将已知分子的MPMs应用到可能具有不同性质的未知分子上。最近,构建了治疗学数据共享(TDC),用于系统地访问和评估跨越大量治疗任务的机器学习模型,这可能成为更公平评估MPM的统一平台
5. Pursuing Broader Impact in Diverse End Tasks
MPM通常规模很大,需要消耗大量的计算能力来训练。最终目标是获得一个通用的分子表示,可以用于任何涉及分子的下游任务。然而,方法的进步和实际应用之间存在着关键的差距。一方面,MPMs还没有被广泛用于取代传统的分子描述符。另一方面,MPMs如何使更多的下游任务受益,包括化学反应预测、虚拟筛选中的分子相似性搜索、逆合成、分子设计、化学空间探索等,仍有待进一步研究。
参考(具体细节见原文)
 https://arxiv.org/abs/2210.16484
https://arxiv.org/abs/2210.16484分子预训练论文链接:


















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











