






目录
CAPABILITIES
基础模型获得了一些能力,其中一些令人惊讶地从学习过程中出现,从而支持下游应用程序。具体来说,我们讨论了语言和视觉能力,以及影响物理世界、执行推理和搜索以及与人类交互的能力。此外,我们还讨论了自我监督(用于学习当前基础模型的技术方法)在哲学上与理解能力的关系。
Language
The nature of human language.
语言是大多数人类交流和互动的基础。然而,它不仅仅是人类实现共同目标的一种手段:语言是人类思想、社会和情感关系如何形成、我们如何在社会和个人上识别自己,以及人类如何记录知识和发展社会智力的核心。口语或手语出现在每个人类社会中,世界上的语言在表达和构建信息的方式上都是令人难以置信的不同,同时在构成一种语言的丰富性方面也表现出惊人的一致性1。语言是一种非常复杂而又有效的系统,由儿童在短时间内持续获得,它们进化并包含了语言社区不断变化的需求和条件。由于语言在人类活动中的中心地位,语言理解和生成是人工智能研究的关键因素。自然语言处理(NLP)是人工智能的子领域,与自动语音识别(ASR)和文本到语音(TTS)等相关领域一起,其目标是让计算机能够理解和生成人类语言。
到2021年为止,NLP一直是受基础模型影响最深刻的领域。第一代基础模型展示了令人印象深刻的各种语言能力,以及对各种语言情况的惊人数量的适应能力。自2018年引入早期基础模型ELMo2和BERT3以来,NLP领域主要围绕使用和理解基础模型。该领域已经转向使用基础模型作为主要工具,转向更广泛的语言学习作为一个中心方法和目标。在本节中,我们在最近成功的基础模型在NLP,详细说明基础模型如何改变了整个过程和心态训练机器学习模型的语言,并讨论一些理论和实践基础模型面临的挑战,因为他们应用于更广泛的语言和更现实和复杂的语言情况。
Impact of foundation models on NLP
基础模型对自然语言处理领域产生了巨大的影响,现在是大多数自然语言处理系统和研究的核心。在第一层次上,许多基础模型都是熟练的语言生成器:例如,4证明,非专家很难区分GPT-3编写的短写英语文本和人类编写的短写英语文本。然而,基础模型在NLP中最重要的特点不是它们的原始生成能力,而是它们惊人的普遍性和适应性:一个单一的基础模型可以以不同的方式进行调整,以实现许多语言任务。
NLP领域历来专注于为具有挑战性的语言任务定义和工程系统,并认为擅长这些任务的模型将导致针对下游应用程序的胜任语言系统。NLP任务包括整个句子或文档的分类任务(例如,情绪分类,如预测电影评论是正面还是负面),序列标签任务,我们分类每个单词或短语在一个句子或文档(例如,预测每个词是一个动词或名词,或跨越的单词指一个人或一个组织),跨度关系分类,(例如。、关系提取或解析,比如一个人和位置是否由“当前住宅”关系,或一个动词和名词“主题”关系)和生成任务,产生新文本强烈条件输入(例如,生产文本的翻译或摘要,识别或生产演讲,或响应对话)5。
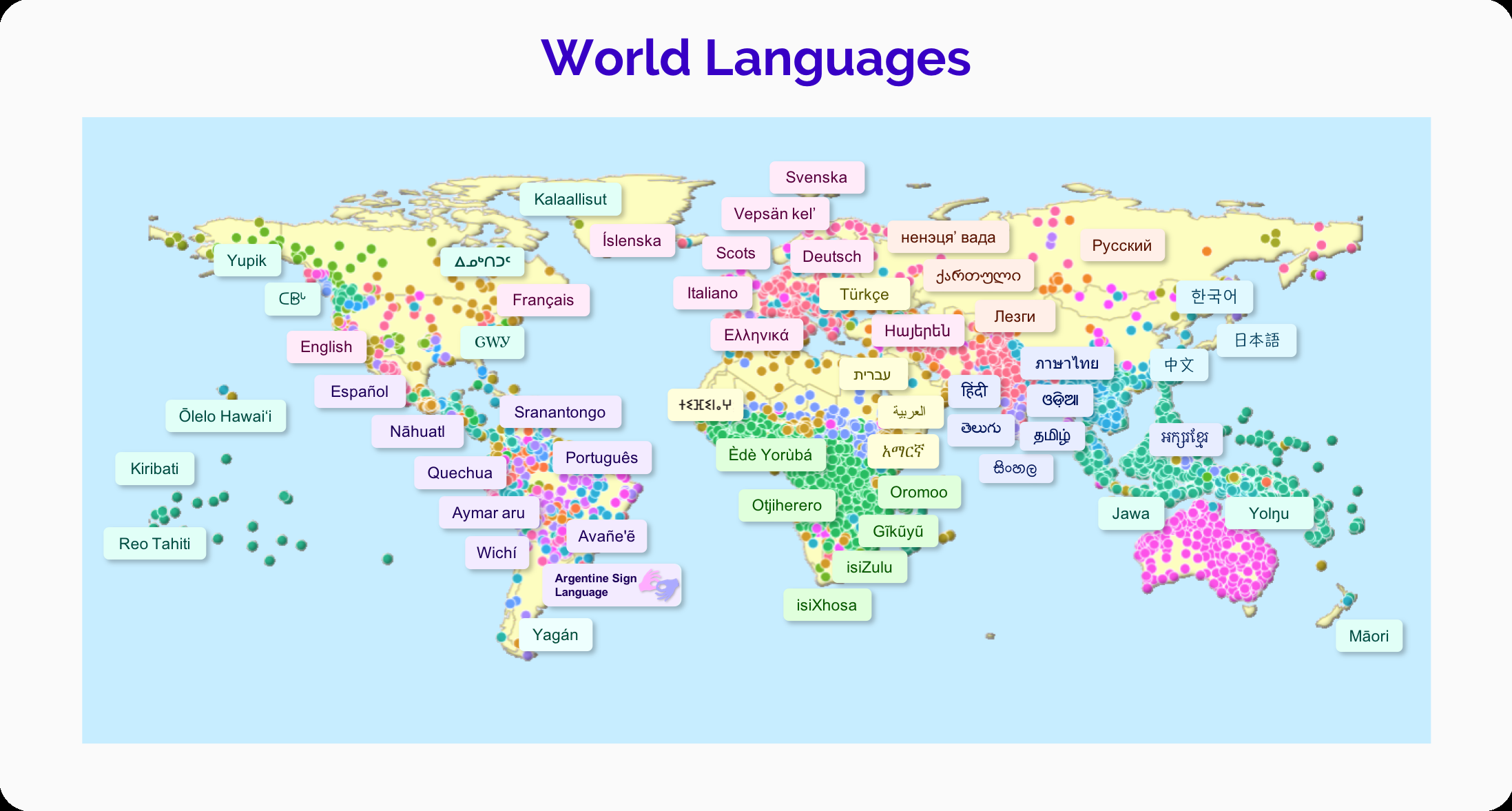
图5。目前,世界上只有一小部分的语言出现在基础模型中。世界上有超过6000多种语言,由于构成独立语言的内在不确定性,估计有所不同6。这张地图显示了世界上的语言,每个点代表一种语言,它的颜色表示顶级语言系。数据来自Glottolog7。我们将地图上的一些语言标记为例子。在过去,NLP任务有不同的研究社区,它们开发了特定于任务的架构,通常基于不同模型的管道,每个模型执行一个语言子任务,如标记分割、句法解析或共引用解析。
相比之下,执行每个任务的主要现代方法是使用单一的基础模型,并使用特定于每个任务的相对少量的注释数据(情绪分类、命名实体标记、翻译、摘要)进行轻微调整,以创建一个适应的模型。这已被证明是一种非常成功的方法:对于上面描述的绝大多数任务,一个稍微适合于任务的基础模型大大优于以前专门为执行该任务而构建的模型或模型管道。举个例子,在2018年,2018年回答开放式科学问题的最佳系统,可以在纽约大学8年级科学考试中获得73.1%的成绩。一年后的2019年,一个经过调整的基金会模型得分为91.6% 8。
基础模型的出现,通过大量训练来生成语言,构成了语言生成在自然语言处理中作用的一个重要转变。直到2018年左右,生成通用语言的问题还被认为是非常困难的,除非通过其他语言子任务9。相反,自然语言处理的研究主要集中在语言学上的分析和理解文本上。现在,我们可以用一个简单的语言生成目标来训练高度连贯的基础模型,比如“预测这个句子中的下一个单词”。这些生成模型现在构成了机器进行语言学习的主要工具——包括分析和理解曾经被认为是生成的先决条件的任务。基础模型所展示的成功一代也导致了总结和对话生成等语言生成任务的研究。基础模型范式的兴起已经开始在口语和写作中发挥类似的作用。现代自动语音识别(ASR)模型,如wav2vec 2.0,仅在大型语音音频数据集上进行训练,然后在与相关转录的音频适应ASR任务10。
由于基础模型范式带来的变化,自然语言处理的研究和实践的重点已经从为不同的任务定制架构转移到探索如何最好地利用基础模型。对适应方法的研究已经蓬勃发展,基础模型的惊人成功也导致了研究兴趣向分析和理解基础模型的转变。
Language variation and multilinguality
尽管基础模型在从预训练中获得的语言知识方面具有惊人的灵活性,但这种适应性仍存在局限性:目前的基础模型在处理语言变异方面有多成功尚不清楚。语言差异很大。除了世界上有数千种不同的语言之外,语言甚至在一种语言内部或一个说话者内部也有所不同。举几个例子,非正式对话与书面语言不同,人们与朋友交谈时的语法结构与与权威人士交谈时的非常不同,一种语言中的社区使用不同的方言。社会和政治因素嵌入在语言变化如何看待和价值,以及多少不同的品种在NLP研究。由于基础模型具有强大的对语言信息的学习能力和灵活的适应能力,因此基础模型有望扩展自然语言处理,以包含更多的语言多样性。它仍然是一个开放的研究问题来理解是否有可能使基础模型,稳健和公平地代表语言的主要和微妙的变化,给予同等的重量和敏锐度使每个语言品种不同的研究提出和解决这个问题包括11;12;13]。
随着英语基础模型的成功,多语言基础模型已经发布,以将这种成功扩展到非英语语言。对于世界上6000多种语言中的大多数来说,可用的文本数据不足以训练一个大规模的基础模型。举个例子,有超过6500万人使用西非语言富拉,但富拉的资源很少14。多语言基础模型通过同时联合培训多种语言来解决这个问题。迄今为止的多语言基础模型(mBERT、mT5、XLM-R)均采用大约100种语言进行训练[3;15;16]。联合多语言培训依赖于一个合理的假设,即语言之间的共享结构和模式可以导致共享和从高资源语言转移到低资源语言,这使得我们无法训练独立模型的语言的基础模型成为可能。 使用多语言基础模型和分析的实验表明,在多语言基础模型中,不同语言之间和并行编码的数量确实有令人惊讶的数量[17;18;19;20;21;22;23]。
然而,这些模型在多大程度上具有多语言仍然是一个悬而未决的问题。目前尚不清楚有多少基于这些数据训练的模型可以代表来自英语的语言方面24,以及它们明显的多语言性能是否更依赖于同化[25;26;27]。多语言模型显示更好的性能类似的语言资源语言的训练数据,它已经表明,语言在多语言模型竞争模型参数,不清楚多少变化可以适合一个模型28。一个突出的问题源于数据,我们使用训练多语言基础模型:在许多多语言语料库,英语数据不仅是数量级比低资源语言更丰富,但它往往是更干净,更广泛,包含例子展示更多的语言深度和复杂性29。然而,答案并不仅仅在于创造更平衡的语料库:语言变化的坐标轴太多了,因此创建一个在所有方面都能达到平衡和具有代表性的语料库是不可行的。基础模型的未来、多功能性和公平性都依赖于稳健地处理语言变化30。
目前的多语言基础模型的原始形式,以及幼稚的无监督多语言训练作为一种方法,可能无法充分模拟语言和语言变体的微妙之处。然而,它们对于一些多语言应用程序仍然很有用,例如,通过为其原始训练集中没有的低资源语言调整多语言模型31。此外,(非公开)GShard神经机器翻译模型的结果显示,最低资源语言比单语基线的收益最大,收益随着模型大小的增加而增加32。研究界应该批判性地研究基础模型如何处理语言变异,理解基础模型在给NLP带来公平和代表性方面的局限性,而不是满足于推广消除语言变异,并在训练数据中大多符合语言多数。
Inspiration from human language acquisition.
尽管基础模型在创造更像人类的自然语言处理系统方面取得了巨大的进展来源,但他们所获得的语言系统以及学习过程仍有重要的方面与人类语言不同。理解机器语言学习和人类语言学习之间的差距的含义,是发展一个了解基础模型的语言限制和可能性的研究社区的必要组成部分。
人类语言习得是非常有效的:基础模型GPT-3训练大约三到四个数量级的语言数据比大多数人会听到或阅读,当然比孩子已经暴露的时候他们大多是语言能力。基础模型和人类语言习得之间的一个显著区别是,人类语言是基于现实世界的33。例如,婴儿和看护人在语言发展过程中指向物体34,婴儿在学习语言系统的许多其他方面之前,先学习涉及共同物体的单词的基本含义35。另一方面,NLP中使用的大多数基础模型都从原始、非扎根文本的分布信息中学习,并且(与人类学习者相反)Zhang等人36表明,RoBERTa模型在可用意义之前表达抽象的句法特征。强大的无基础的统计学习确实也存在于婴儿中37,因此它无疑是习得的一个重要因素。然而,推进基础模型的基础语言学习仍然是接近人类习得效率的重要方向[38;39;40]。
另一个重要的方向是检验基础模型中的归纳偏差,以及它们如何与人类思维中的归纳偏差相关,包括语言学习的和人类认知的41。虽然人类大脑在结构上可能更专注于有效的语言习得,但基础模型不是白纸学习者42,理解和对齐这些语言归纳偏差是基础模型研究的一个重要未来方向。
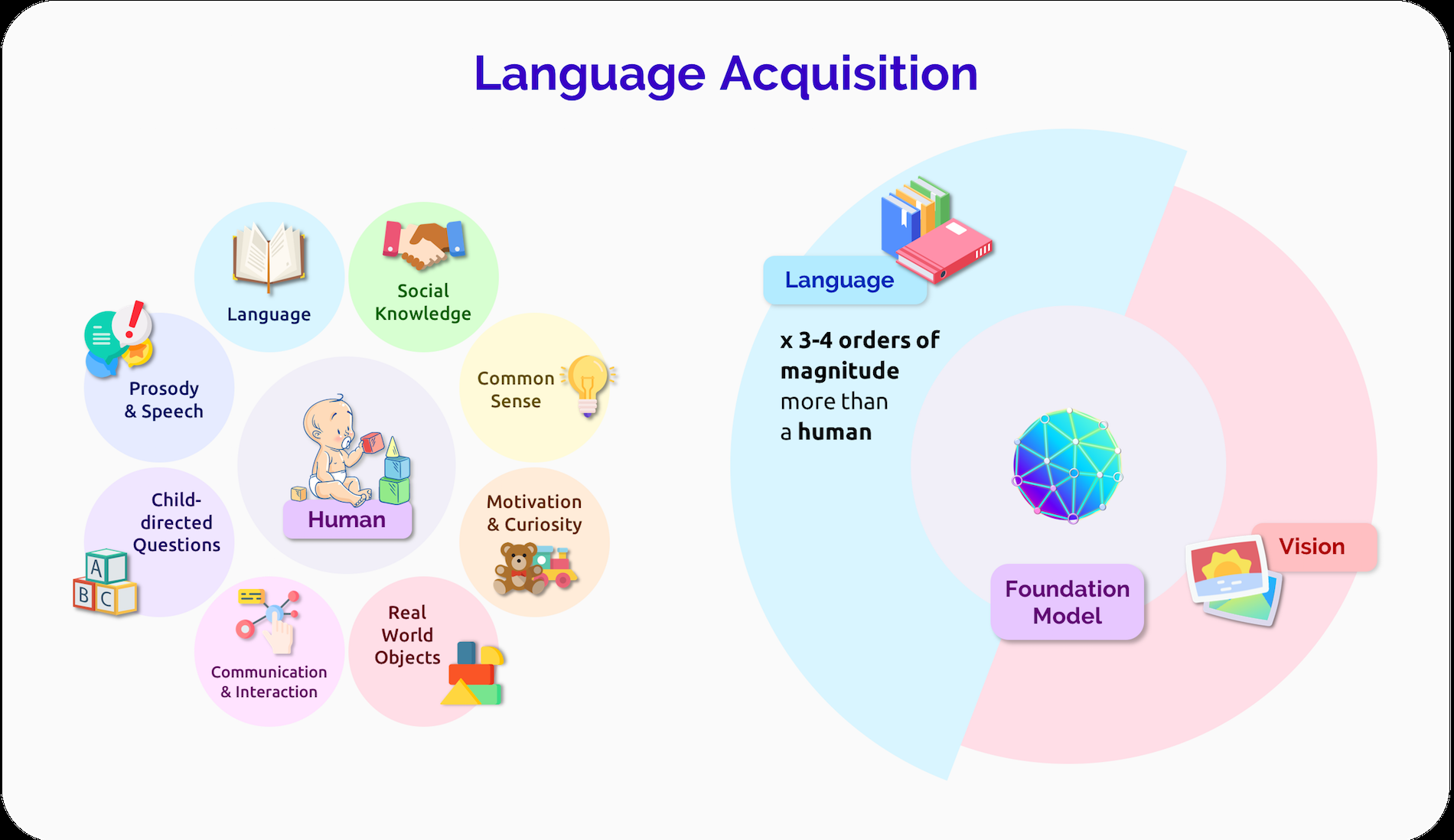
图6。面向人类的语言习得和基础模型。虽然人类大脑和基础模型之间肯定存在不同的归纳偏差,但他们学习语言的方式也非常不同。最突出的是,人类与一个物理世界和社会世界的互动,其中他们有不同的需求和欲望,而基础模型主要是观察和建模由他人产生的数据。
提高语言习得效率的一个重要因素是,人类获得了一个系统的、可概括的语言系统。尽管关于人类语言系统的理论抽象类型有许多不同的理论[例如,43;44].但人们普遍认为,人类学习语言的方式允许他们轻松地将新知识插入到现有的抽象中,并有效地创造新的语法句子。例如,一个10岁的孩子已经获得了很多关于他们的语言如何工作的抽象概念,尽管他们产生的实际单词和结构将在未来十年内发生巨大的变化。另一方面,基础模型往往无法获得我们所期望的来自人类的系统抽象概念。例如,当一个基础模型准确地产生语言结构一次时,不能保证未来的使用将是一致的,特别是在主题的重大领域转移之后[研究基础模型的系统性包括45;46;47]。自然语言处理面临的挑战是在基础模型中发展某种系统化的获取,而不回归到过于依赖严格的语言规则的系统。
语言学习贯穿了说话者的一生:人类语言的语法不断进化,人类可以灵活地适应新的语言情境。例如,当新的术语和概念在成年人的生活中出现时,他们可以相对容易地在语法句子中使用它们,而人类经常调整他们的语法模式,以适应不同的社会群体。另一方面,基础模型的语言系统主要由训练数据设置,且相对静态。虽然适应方法可以为不同的任务建立基础模型,但在不进行大量训练的情况下,如何改变基础模型的更基本的语言基础仍不清楚。建立能够自然反映类人语言适应和语言进化的适应性模型是未来基础模型的一个重要研究领域。
基础模式极大地改变了自然语言处理的研究和实践。基础模型产生了许多新的研究方向:理解生成作为语言的基本方面,研究如何最好地使用和理解基础模型,理解基础模型的方式可能增加不平等在NLP,检查基础模型是否可以令人满意地包含语言变异和多样性,并找到方法利用人类语言学习动力学。在基础模型之前,研究社区关注的大多数复杂的NLP任务现在被最好地处理,使用少数公开发布的基础模型之一,达到接近人类的水平。然而,在这种性能和在复杂的下游设置中有用和安全地部署基础模型的需求之间仍然存在显著的差距。
Vision
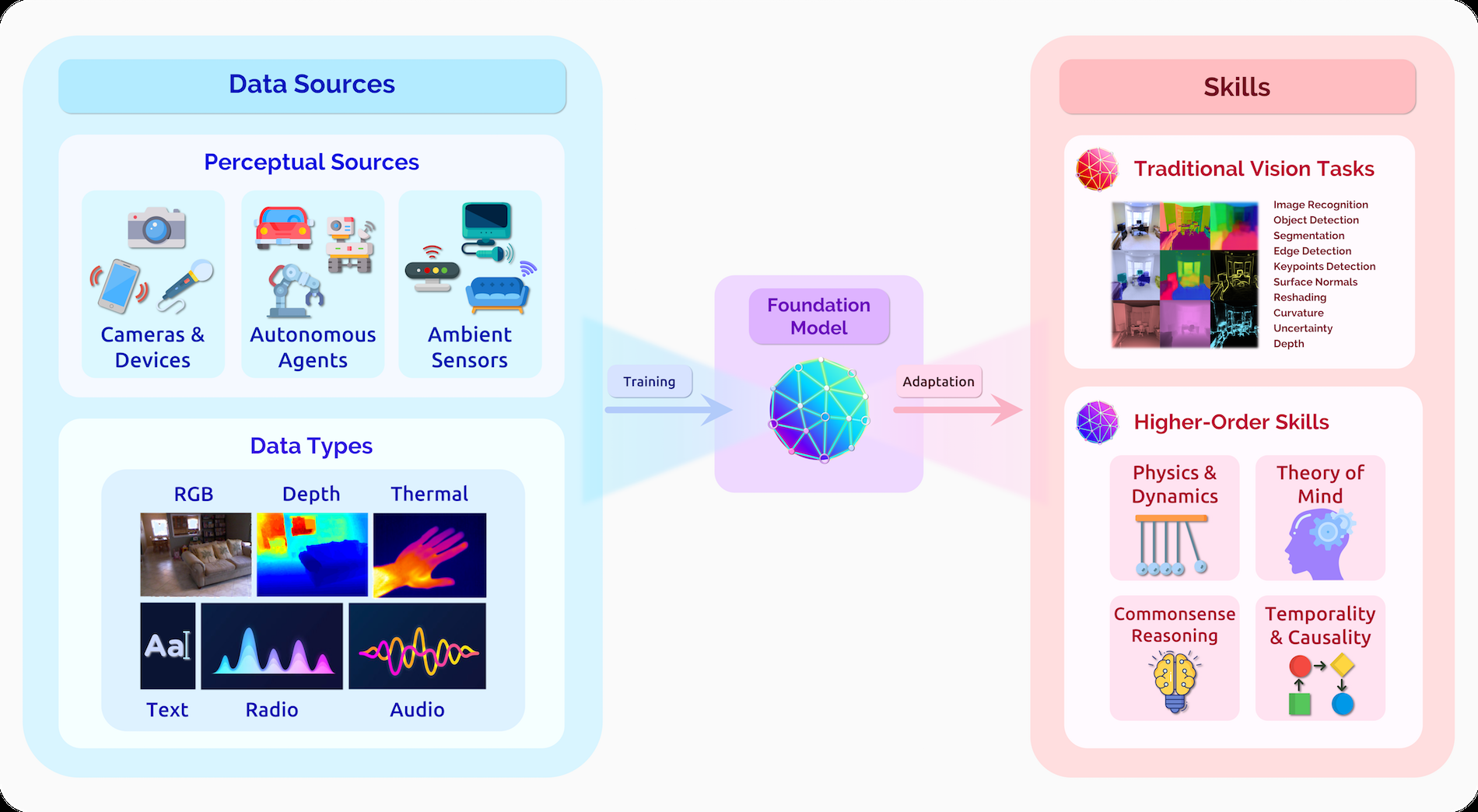
图7。通过利用大规模的自我监督,视觉基础模型有可能将原始的、多模态的感官信息提炼为视觉知识,这可能有效地支持传统的感知任务,并可能在挑战时间和常识推理等高阶技能方面取得新的进展。这些输入可以来自不同的数据源和应用程序领域,这表明在医疗保健和具体化的交互式感知设置中的应用程序有前景。
视觉是生物体了解其环境的主要模式之一的基础。观察的能力使近恒定的、远程的密集信号收集成为可能,这是一种在各种生命形式的进化时间尺度上发展起来的关键能力。技能执行毫不费力地甚至简单的生物,转移相同的能力机器证明非常具有挑战性,领先的计算机视觉和机器人研究员汉斯·莫拉1988年观察一个悖论:在人工智能,(被认为)难题是简单的,同样容易的问题,和“最简单”的问题之一的视觉敏锐度我们每天不断在毫秒内解释复杂的场景。
另一端这个可怕的挑战是大量的变革应用程序的计算机视觉的关键:自动驾驶汽车可以免费通勤者摆脱僵局,救生人工智能工具,可以帮助过度专家检测罕见的医疗事件,下一代多媒体创建和编辑工具,等等。反思人类感知的应用和设置,提供了计算机视觉可以帮助和转换的潜在领域。
计算机视觉领域和我们所定义的挑战从许多方面从人类的感知能力中获得灵感。一些经典理论提出,人类可以通过一个更大的整体来感知现实世界的场景,并指出了计算机视觉技术逐步模拟抽象水平的道路认为人类视觉具有内在的体现,互动的生态环境可能在其发展中发挥关键作用。这些想法继续推动计算机视觉系统的持续发展,迭代世界的上下文、互动和具体化的感知。
在计算机视觉的背景下,基础模型将来自不同来源和传感器的原始感知信息转化为视觉知识,可以适应许多下游设置(图7)。在很大程度上,这种努力是过去十年来在该领域出现的关键思想的自然演变。ImageNet的引入和监督预训练的出现导致了计算机视觉中深度学习范式的转变。
这一转变标志着一个新时代,我们超越了早期的经典方法和任务特定特征工程,这些模型可以在大量数据中进行训练,然后适应各种任务,如图像识别、目标检测和图像分割。这个想法仍然是基础模型的核心。
通往基础模型的桥梁来自于先前范式的局限性。传统的监督技术依赖于昂贵且仔细收集的标签和注释,限制了其鲁棒性、泛化和适用性;相比之下,自我监督学习的最新进展提出了另一种开发基础模型的途径,可以利用大量的原始数据来获得对视觉世界的上下文理解。相对于该领域的更广泛目标,目前视觉基础模型的能力目前还处于早期阶段:我们观察到传统计算机视觉任务的改进(特别是在泛化能力方面),并预计近期的进展将继续这一趋势。然而,从长远来看,基础模型减少对外显性注释依赖的潜力可能会导致基本认知技能的进展,这在当前的完全监督范式中被证明是困难的。反过来,我们将讨论基础模型对下游应用程序的潜在影响,以及未来必须解决的核心挑战和前沿。
Key capabilities and approaches.
在高层次上,计算机视觉是人工智能的核心子领域,它探索如何赋予机器解释和理解视觉世界的能力。它包括许多任务、子域和下游应用程序,这些社区在过去几十年中取得了持续的进展。选择示例任务:(1)语义理解任务,旨在发现视觉场景中实体之间的属性和关系;包括图像分类、目标检测、语义分割、动作识别和场景图生成。(2)几何、运动和三维任务,寻求表示静止或运动物体的几何、姿态和结构,包括深度估计、运动结构、表面法线检测、曲率线和关键点估计等任务。.(3)多模态集成任务,将语义和几何理解与自然语言等其他模式相结合;例如,包括视觉问题回答、图像字幕和后续指导。我们在图7中突出显示了传统核心任务的一个子集。
解决这些任务的主要范式,由ImageNet的出现[邓等。2009]在2010年代初,倾向于围绕一个熟悉的核心思想:首先,预训练模型在大量精心注释的数据完全监督训练任务,像图像分类。然后,针对特定数据集和领域的下游调整模型通过微调以达到最先进的性能。这种预训练和适应的概念仍然存在于我们现在考虑的基础模型的定义中。这种完全监督范式的局限性促使了向基础模型的过渡:对外部监督注释的依赖限制了以前方法的上限能力,即以可扩展、健壮和可推广的方式捕获视觉输入的不同频谱。在视觉合成和无监督学习领域的最新发展提供了一个引人注目的选择。例如,GANs通过学习生成高保真、现实主义和多样性的视觉内容,通过两个竞争的发电机和鉴别器可以单独监督图像收集。其他神经模型通过使用变分自动编码、对比学习或其他自我监督技术,在没有明确注释监督的情况下推断物体和场景的视觉属性。例如,He等人建立在掩蔽图像编码的表示学习的工作,部分是将柔性架构的最新进展(如视觉变压器)与更大的扩展相结合。
有了基础模型,这种自我监督技术的发展使得在更广泛的视觉数据中进行训练,无论是在其范围还是在其潜在的多样性方面。因此,我们已经看到了在传统视觉任务中取得进展的早期指标和少镜头的概括指标。在图像分类和目标检测方面,自我监督技术报告了与先前的完全监督方法的竞争性能,在训练期间没有明确的注释,在适应过程中有更高的样本效率。在视觉合成方面,值得注意的例子包括DALL-E和clip引导生成,其中研究人员利用多模态语言和视觉输入来呈现引人注目的视觉场景。在短期内,我们预计,随着培训目标的细化,这些基础模型的能力将沿着这些方向继续提高和架构被设计为纳入额外的模式。
Bernard Comrie. 1989. Language universals and linguistic typology: Syntax and morphology. University of Chicago press. ↩︎
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In North American Association for Computational Linguistics (NAACL). ↩︎
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Association for Computational Linguistics (ACL). 4171–4186. ↩︎ ↩︎
Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A Smith. 2021. All That’s ’Human’ Is Not Gold: Evaluating Human Evaluation of Generated Text. arXiv preprint arXiv:2107.00061 (2021). ↩︎
D. Jurafsky and J.H. Martin. 2009. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Pearson Prentice Hall. ↩︎
Sebastian Nordhoff and Harald Hammarström. 2011. Glottolog/Langdoc: Defining dialects, languages, and language families as collections of resources. In First International Workshop on Linked Science 2011-In conjunction with the International Semantic Web Conference (ISWC 2011). ↩︎
Harald Hammarström, Robert Forkel, Martin Haspelmath, and Sebastian Bank. 2021. Glottolog 4.4. Leipzig.
Peter Clark, Oren Etzioni, Daniel Khashabi, Tushar Khot, Bhavana Dalvi Mishra, Kyle Richardson, Ashish Sabharwal, ↩︎Carissa Schoenick, Oyvind Tafjord, Niket Tandon, Sumithra Bhakthavatsalam, Dirk Groeneveld, Michal Guerquin, and Michael Schmitz. 2019. From ’F’ to ’A’ on the N.Y. Regents Science Exams: An Overview of the Aristo Project. CoRR abs/1909.01958 (2019). ↩︎
C.L. Paris, W.R. Swartout, and W.C. Mann. 2013. Natural Language Generation in Artificial Intelligence and Computational Linguistics. Springer US. ↩︎
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 12449–12460. ↩︎
Edoardo Maria Ponti, Helen O’Horan, Yevgeni Berzak, Ivan Vulić, Roi Reichart, Thierry Poibeau, Ekaterina Shutova, and Anna Korhonen. 2019. Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing. Computational Linguistics 45, 3 (09 2019), 559–601. ↩︎
Emily M Bender. 2011. On achieving and evaluating language-independence in NLP. Linguistic Issues in Language Technology 6, 3 (2011), 1–26. ↩︎
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 6282–6293. ↩︎
Elhadji Mamadou Nguer, Alla Lo, Cheikh M Bamba Dione, Sileye O Ba, and Moussa Lo. 2020. SENCORPUS: A French-Wolof Parallel Corpus. In Proceedings of the 12th Language Resources and Evaluation Conference. 2803–2811. ↩︎
Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, and Alexis Conneau. 2021. Larger-Scale Transformers for Multilingual Masked Language Modeling. arXiv preprint arXiv:2105.00572 (2021). ↩︎
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2020. mt5: A massively multilingual pre-trained text-to-text transformer. arXiv preprint arXiv:2010.11934 (2020). ↩︎
Shijie Wu and Mark Dredze. 2019. Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 833–844. ↩︎
Rochelle Choenni and Ekaterina Shutova. 2020. Cross-neutralising: Probing for joint encoding of linguistic information in multilingual models. arXiv preprint arXiv:2010.12825 (2020). ↩︎
Telmo Pires, Eva Schlinger, and Dan Garrette. 2019. How Multilingual is Multilingual BERT?. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 4996–5001 ↩︎
Jindřich Libovick`y, Rudolf Rosa, and Alexander Fraser. 2019. How language-neutral is multilingual BERT? arXiv preprint arXiv:1911.03310 (2019). ↩︎
Ethan A Chi, John Hewitt, and Christopher D Manning. 2020. Finding Universal Grammatical Relations in Multilingual BERT. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 5564–5577. ↩︎
Isabel Papadimitriou, Ethan A Chi, Richard Futrell, and Kyle Mahowald. 2021. Deep Subjecthood: Higher-Order Grammatical Features in Multilingual BERT. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2522–2532. ↩︎
Steven Cao, Nikita Kitaev, and Dan Klein. 2019. Multilingual Alignment of Contextual Word Representations. In International Conference on Learning Representations. ↩︎
Shijie Wu and Mark Dredze. 2020. Are All Languages Created Equal in Multilingual BERT?. In Proceedings of the 5th Workshop on Representation Learning for NLP. 120–130. ↩︎
Anne Lauscher, Vinit Ravishankar, Ivan Vulić, and Goran Glavaš. 2020. From Zero to Hero: On the Limitations of Zero-Shot Language Transfer with Multilingual Transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 4483–4499. ↩︎
Antti Virtanen, Jenna Kanerva, Rami Ilo, Jouni Luoma, Juhani Luotolahti, Tapio Salakoski, Filip Ginter, and Sampo Pyysalo. 2019. Multilingual is not enough: BERT for Finnish. arXiv preprint arXiv:1912.07076 (2019). ↩︎
Mikel Artetxe, Sebastian Ruder, and Dani Yogatama. 2020. On the Cross-lingual Transferability of Monolingual Representations. arXiv:1910.11856 [cs] (May 2020). ↩︎
Zirui Wang, Zachary C Lipton, and Yulia Tsvetkov. 2020d. On Negative Interference in Multilingual Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 4438–4450. ↩︎
Isaac Caswell, Julia Kreutzer, Lisa Wang, Ahsan Wahab, Daan van Esch, Nasanbayar Ulzii-Orshikh, Allahsera Tapo, Nishant Subramani, Artem Sokolov, Claytone Sikasote, Monang Setyawan, Supheakmungkol Sarin, Sokhar Samb, Benoît Sagot, Clara Rivera, Annette Rios, Isabel Papadimitriou, Salomey Osei, Pedro Javier Ortiz Suárez, Iroro Orife, Kelechi Ogueji, Rubungo Andre Niyongabo, Toan Q. Nguyen, Mathias Müller, André Müller, Shamsuddeen Hassan Muhammad, Nanda
Muhammad, Ayanda Mnyakeni, Jamshidbek Mirzakhalov, Tapiwanashe Matangira, Colin Leong, Nze Lawson, Sneha Kudugunta, Yacine Jernite, Mathias Jenny, Orhan Firat, Bonaventure F. P. Dossou, Sakhile Dlamini, Nisansa de Silva, Sakine Çabuk Ballı, Stella Biderman, Alessia Battisti, Ahmed Baruwa, Ankur Bapna, Pallavi Baljekar, Israel Abebe Azime, Ayodele Awokoya, Duygu Ataman, Orevaoghene Ahia, Oghenefego Ahia, Sweta Agrawal, and Mofetoluwa Adeyemi. 2021. Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. ArXiv abs/2103.12028 (2021). ↩︎Yonatan Oren, Shiori Sagawa, Tatsunori Hashimoto, and Percy Liang. 2019. Distributionally Robust Language Modeling. In Empirical Methods in Natural Language Processing (EMNLP). ↩︎
Zihan Wang, K Karthikeyan, Stephen Mayhew, and Dan Roth. 2020b. Extending Multilingual BERT to Low-Resource Languages. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings. 2649– 2656. ↩︎
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. In International Conference on Learning Representations. ↩︎
Matthew Saxton. 2017. Child Language: Acquisition and Development. Sage Publications, London. ↩︎
Cristina Colonnesi, Geert Jan JM Stams, Irene Koster, and Marc J Noom. 2010. The relation between pointing and language development: A meta-analysis. Developmental Review 30, 4 (2010), 352–366. ↩︎
Elika Bergelson and Daniel Swingley. 2012. At 6–9 months, human infants know the meanings of many common nouns. Proceedings of the National Academy of Sciences 109, 9 (2012), 3253–3258. ↩︎
Yian Zhang, Alex Warstadt, Haau-Sing Li, and Samuel R Bowman. 2021. When Do You Need Billions of Words of Pretraining Data?. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics. ↩︎
Jenny R Saffran, Richard N Aslin, and Elissa L Newport. 1996. Statistical learning by 8-month-old infants. Science 274, 5294 (1996), 1926–1928. ↩︎
Emmanuel Dupoux. 2018. Cognitive science in the era of artificial intelligence: A roadmap for reverse-engineering the infant language-learner. Cognition 173 (2018), 43–59. ↩︎
Hao Tan and Mohit Bansal. 2020. Vokenization: Improving Language Understanding via Contextualized, Visually-Grounded Supervision. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2066–2080. ↩︎
Rowan Zellers, Ari Holtzman, Matthew Peters, Roozbeh Mottaghi, Aniruddha Kembhavi, Ali Farhadi, and Yejin Choi. 2021a. PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World. arXiv preprint arXiv:2106.00188 (2021) ↩︎
Tal Linzen and Marco Baroni. 2021. Syntactic structure from deep learning. Annual Review of Linguistics 7 (2021), 195–212 ↩︎
Marco Baroni. 2021. On the proper role of linguistically-oriented deep net analysis in linguistic theorizing. arXiv preprint arXiv:2106.08694 (2021). ↩︎
- ↩︎
Noam Chomsky. 2014. The minimalist program. MIT press. ↩︎
Brenden Lake and Marco Baroni. 2018. Generalization without systematicity: On the compositional skills of sequence-to sequence recurrent networks. In International conference on machine learning. PMLR, 2873–2882. ↩︎
Najoung Kim and Tal Linzen. 2020. COGS: A Compositional Generalization Challenge Based on Semantic Interpretation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 9087–9105. ↩︎
Rahma Chaabouni, Roberto Dessì, and Eugene Kharitonov. 2021. Can Transformers Jump Around Right in Natural Language? Assessing Performance Transfer from SCAN. arXiv preprint arXiv:2107.01366 (2021). ↩︎















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









