









上篇:FPGA HLS 卷积单元 数据类型&hls优化&约束设置_xiongyuqing的博客-CSDN博客
AXI接口协议详解-AXI总线、接口、协议 - 腾讯云开发者社区-腾讯云 (tencent.com)
给函数参数添加axilite控制端口:
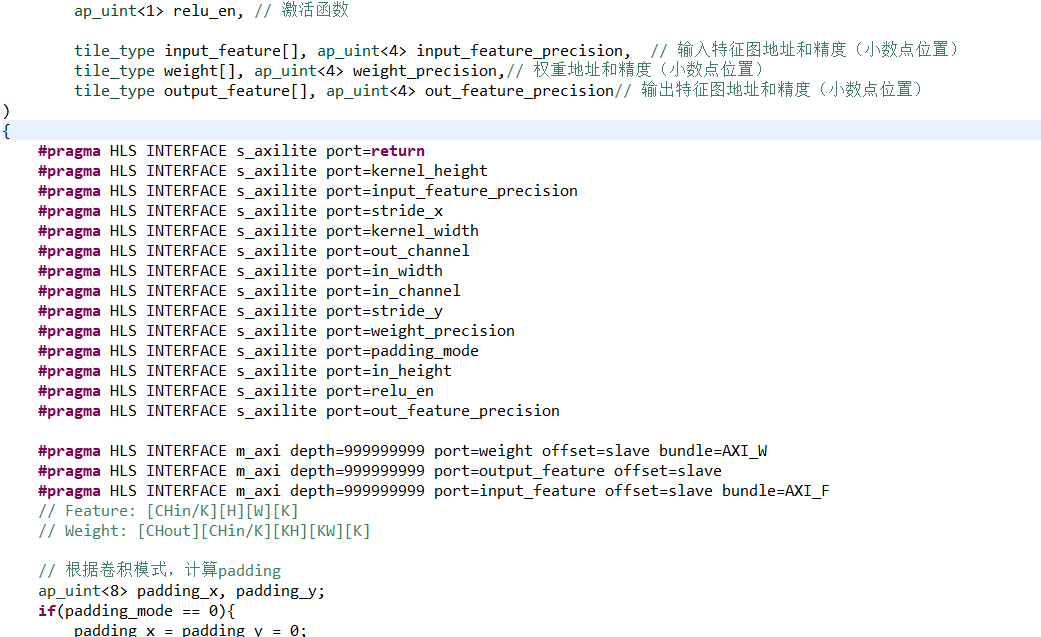
#include "conv_core.h"
void conv_core(
// 特征图参数
ap_uint<16> in_channel, // 输入特征的通道数
ap_uint<16> in_height, // 输入特征高度
ap_uint<16> in_width, // 输入特征宽度
ap_uint<16> out_channel, // 输出特征通道数
// 卷积核参数
ap_uint<8> kernel_width, // 卷积核宽度
ap_uint<8> kernel_height, // 卷积核高度
ap_uint<8> stride_x, // 宽度方向步长
ap_uint<8> stride_y, // 高度方向步长
ap_uint<1> padding_mode, // 卷积的模式; 0: valid(没有padding填充), 1:same(输入输出的图大小不变)
ap_uint<1> relu_en, // 激活函数
tile_type input_feature[], ap_uint<4> input_feature_precision, // 输入特征图地址和精度(小数点位置)
tile_type weight[], ap_uint<4> weight_precision,// 权重地址和精度(小数点位置)
tile_type output_feature[], ap_uint<4> out_feature_precision// 输出特征图地址和精度(小数点位置)
)
{
#pragma HLS INTERFACE s_axilite port=return
#pragma HLS INTERFACE s_axilite port=kernel_height
#pragma HLS INTERFACE s_axilite port=input_feature_precision
#pragma HLS INTERFACE s_axilite port=stride_x
#pragma HLS INTERFACE s_axilite port=kernel_width
#pragma HLS INTERFACE s_axilite port=out_channel
#pragma HLS INTERFACE s_axilite port=in_width
#pragma HLS INTERFACE s_axilite port=in_channel
#pragma HLS INTERFACE s_axilite port=stride_y
#pragma HLS INTERFACE s_axilite port=weight_precision
#pragma HLS INTERFACE s_axilite port=padding_mode
#pragma HLS INTERFACE s_axilite port=in_height
#pragma HLS INTERFACE s_axilite port=relu_en
#pragma HLS INTERFACE s_axilite port=out_feature_precision
#pragma HLS INTERFACE m_axi depth=999999999 port=weight offset=slave bundle=AXI_W
#pragma HLS INTERFACE m_axi depth=999999999 port=output_feature offset=slave
#pragma HLS INTERFACE m_axi depth=999999999 port=input_feature offset=slave bundle=AXI_F
// Feature: [CHin/K][H][W][K]
// Weight: [CHout][CHin/K][KH][KW][K]
// 根据卷积模式,计算padding
ap_uint<8> padding_x, padding_y;
if(padding_mode == 0){
padding_x = padding_y = 0;
}else{
padding_x = (kernel_width-1)/2;
padding_y = (kernel_height-1)/2;
}
// 计算分块个数
ap_uint<16> div_tile_num = (in_channel + K-1) / K;
// 计算输出截断精度
ap_uint<5> out_truncate = input_feature_precision + weight_precision - out_feature_precision;
/*
* [x x x] x x x
* x x [x x x] x
*/
// 计算输出宽度和高度
ap_uint<16> out_width = (in_width + padding_x*2) / stride_x + 1;
ap_uint<16> out_height = (in_height + padding_y*2) / stride_y + 1;
// 计算输出特征中一个tile的数据
ap_int<16> out_tile = 0;
// 相乘结果累加
acc_type sum=0;
// 选择输出特征的第y行,第x列,第c_out个输出通道的数据
// 选择第c_out个权重的第y行,第x列,第tile_index个分块
LOOP_out_height:
for(int i = 0; i < out_height; ++ i){
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
LOOP_out_width:
for(int j = 0; j < out_width; ++ j){
#pragma HLS LOOP_TRIPCOUNT min=10 max=10 avg=10
LOOP_out_channel:
for(int out_index = 0; out_index < out_channel; ++ out_index){
#pragma HLS LOOP_TRIPCOUNT min=10 max=10 avg=10
LOOP_kernel_height:
for(int kh = 0; kh < kernel_height; ++ kh){
#pragma HLS LOOP_TRIPCOUNT min=5 max=5 avg=5
LOOP_kernel_width:
for(int kw = 0; kw < kernel_width; ++ kw){
#pragma HLS LOOP_TRIPCOUNT min=5 max=5 avg=5
LOOP_div_tile_num:
for(int tile_index = 0; tile_index < div_tile_num; ++ tile_index){
#pragma HLS PIPELINE II=1
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
// 获取计算点
ap_uint<16> in_h = i*stride_y-padding_y + kh;
ap_uint<16> in_w = j*stride_x-padding_x + kw;
// 获取输入特征和权重的一个块数据
tile_type data_tile, weight_tile;
// 有padding会越界
if(in_h >= 0 && in_h < in_height && in_w >= 0 && in_w < in_width){
data_tile = input_feature[in_width*in_height*tile_index + in_width*in_h + in_w];
weight_tile = weight[kernel_width*kernel_height*div_tile_num*out_index
+ kernel_width*kernel_height*tile_index
+ kernel_width*kh+kw];
}else{
data_tile = 0; weight_tile = 0;
}
// 块数据相乘
mul_tile_type mul_tile_data;
for(int k = 0; k < K; ++ k)
mul_tile_data.range(k*32+31, k*32) =
(data_type)data_tile.range(k*16+15, k*16)*
(data_type)weight_tile.range(k*16+15, k*16);
// 相乘结果累加
for(int k = 0; k < K; ++ k)
sum += (mul_tile_type)mul_tile_data.range(k*32+31, k*32);
if(tile_index == div_tile_num-1 && kh == kernel_height-1 && kw == kernel_width-1){
// 激活函数
if(relu_en & sum < 0) sum = 0;
// 截断多余精度
acc_type res = sum >> out_truncate;
if (res > 32767)
res = 32767;
else if (res < -32768)
res = -32768;
// 先缓存下来,下面一次写入
out_tile.range((out_index % K) * 16 + 15, (out_index % K) * 16) = res;
sum = 0;
// 存tile里的一个数据
// 一个tile都存完了或者存到最后一个通道凑不够一个tile
if((out_index%K) == K - 1 || out_index == (out_channel - 1)){
output_feature[(out_index/K)*out_width*out_height + out_width*i+j] = out_tile;
out_tile = 0;
}
}
}
}
}
}
}
}
}
Export RTL 生成IP核
解决Vivado HLS 高层综合失败_竹灬鹿的博客-CSDN博客
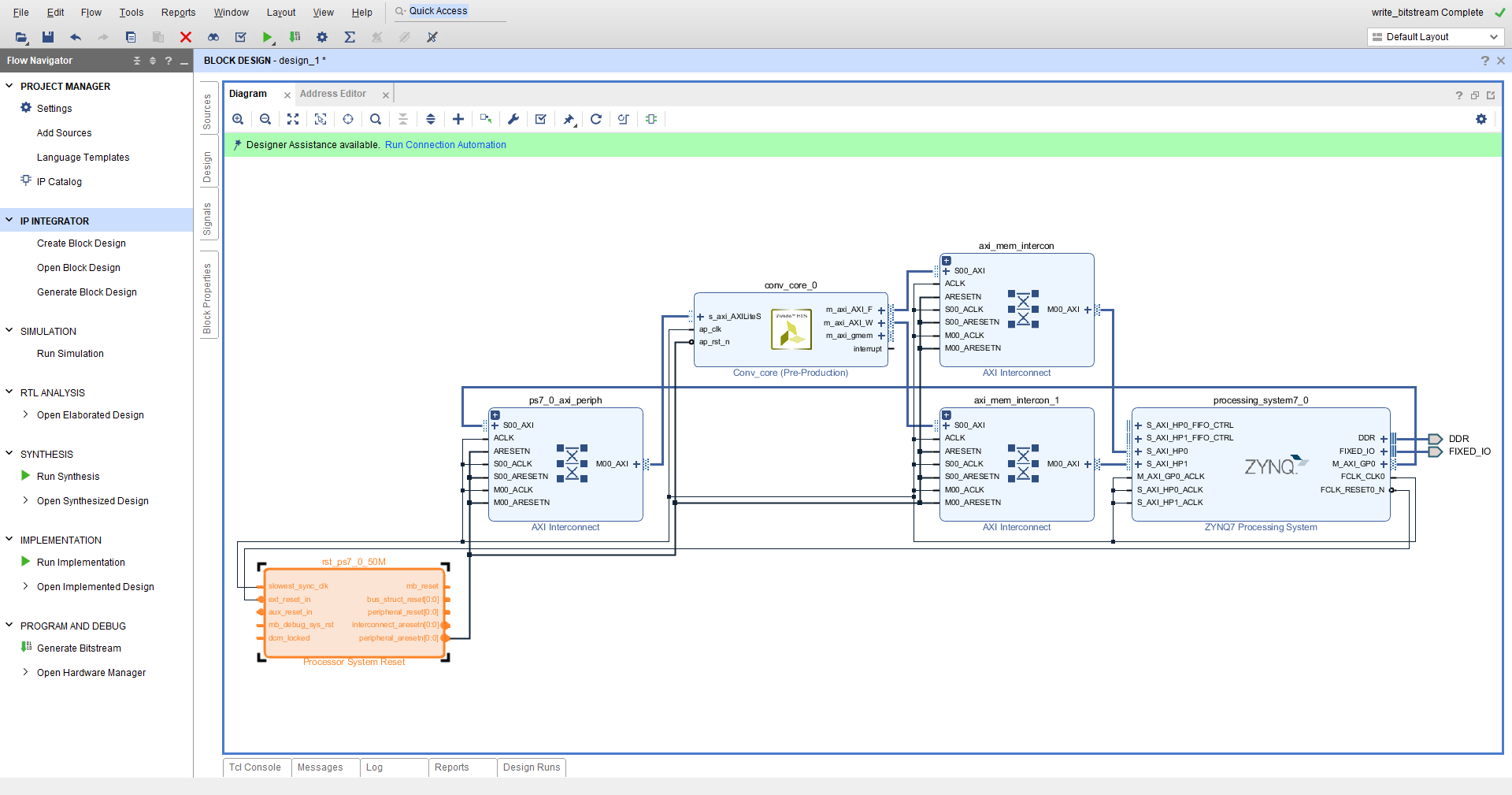
新建Vivado工程,导入IP核
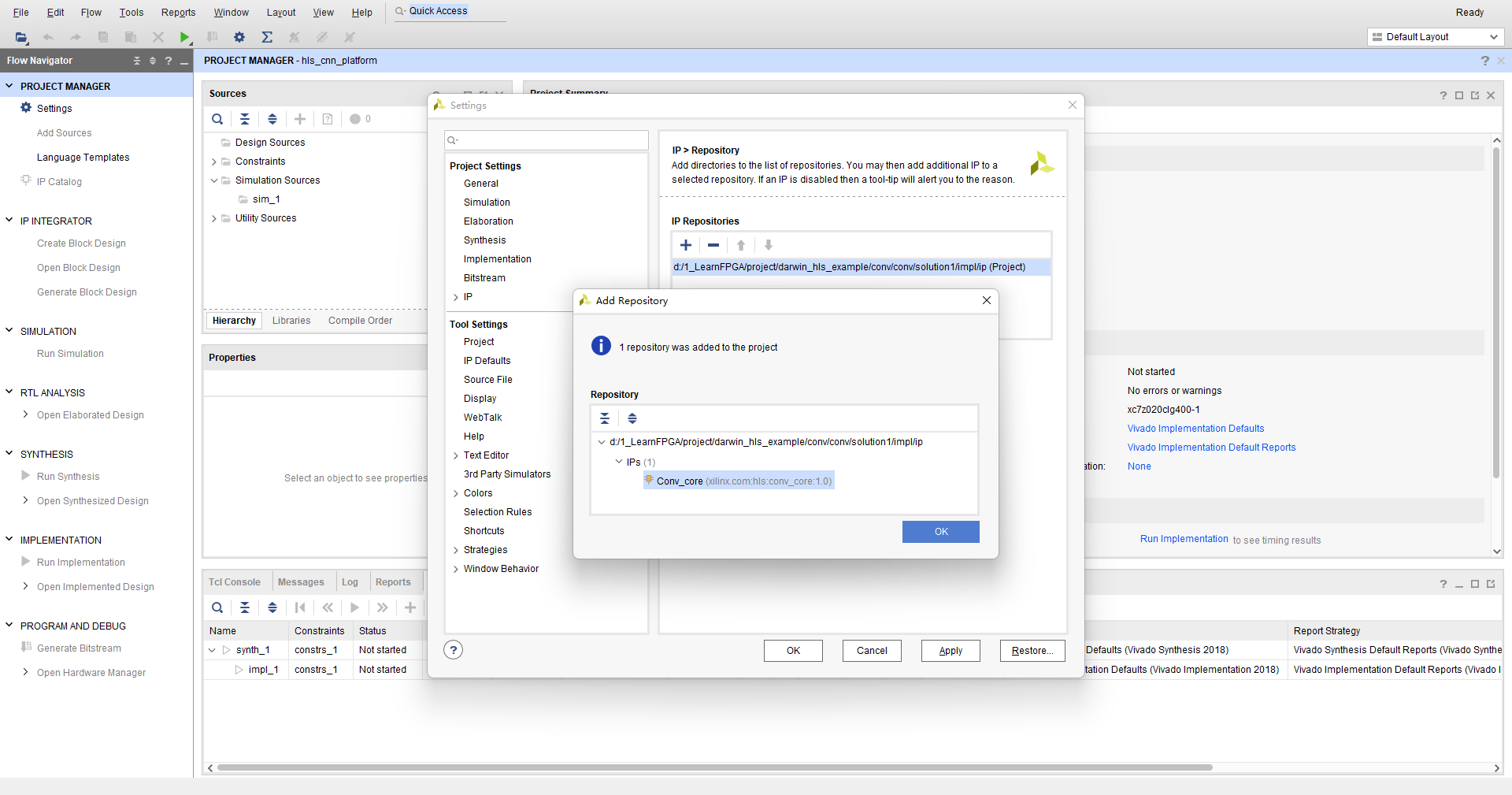
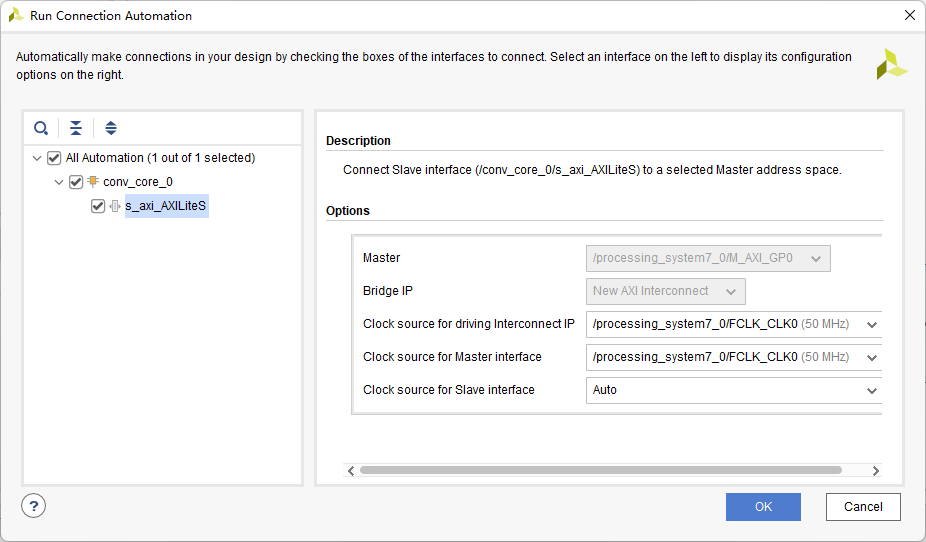
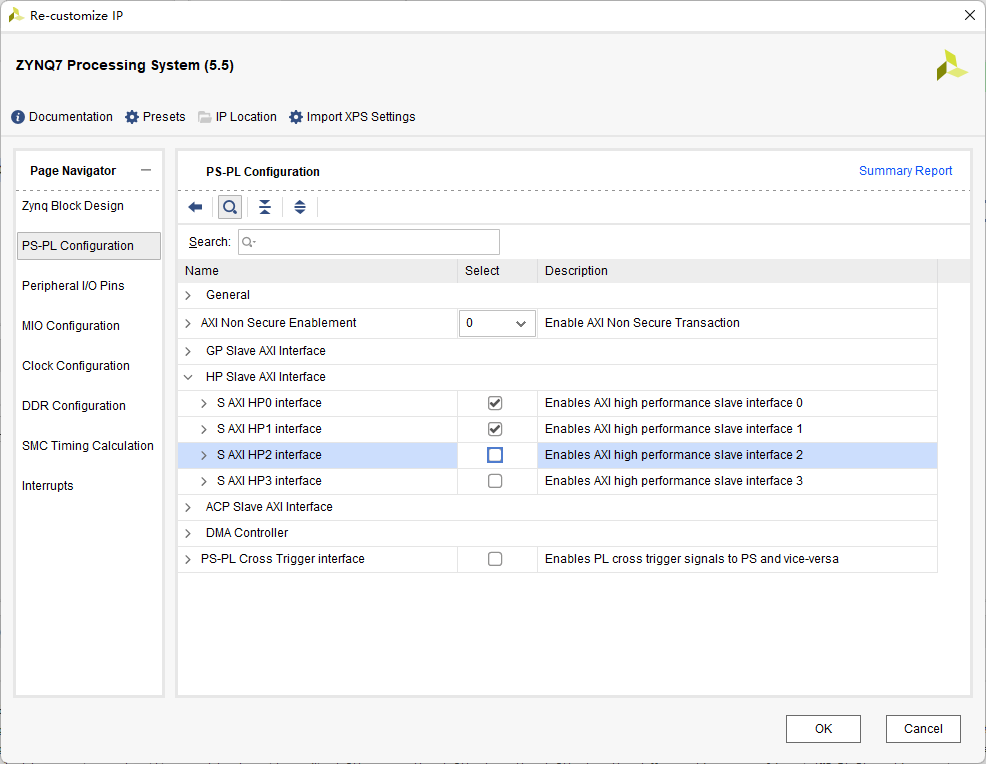
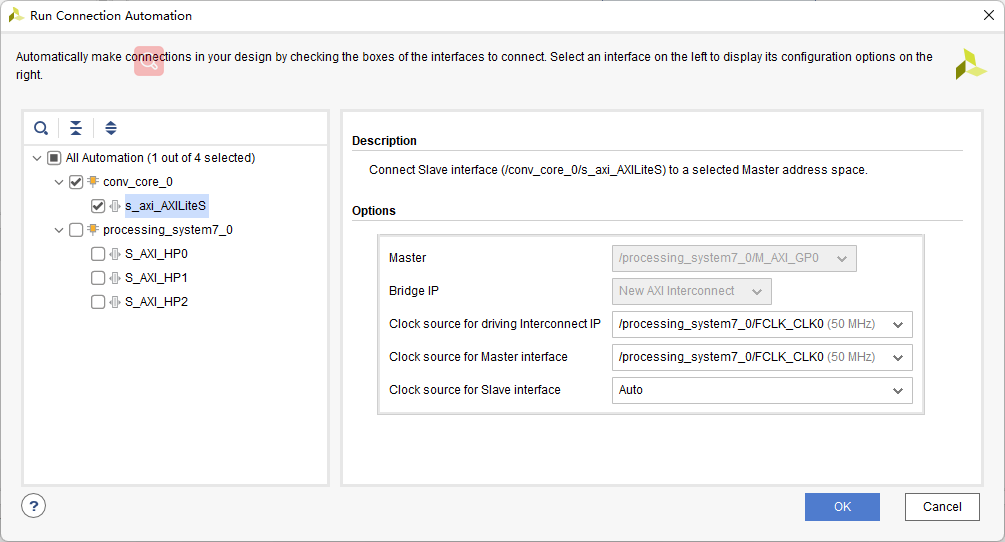
开两个HP口用于控制和数据的传输:
控制端口AXILite AXI_F和AXI_W用HP口相连,注意要选new AXI Inerconnect:
包装,生成product,然后生成bit流文件
zynq 主机程序
from pynq import Overlay
import numpy as np
from pynq import Xlnk
import time
import random
K=8
in_width=40
in_height=40
in_channel=8
Kx=5
Ky=5
Sx=2
Sy=2
RELU_EN=0
MODE=0 #0: valid, 1:same
X_PADDING=(Kx-1)//2 if MODE==1 else 0;
Y_PADDING=(Ky-1)//2 if MODE==1 else 0;
out_channel=6
out_width=(in_width+2*X_PADDING-Kx)//Sx+1
out_height=(in_height+2*Y_PADDING-Ky)//Sy+1
xlnk=Xlnk()
ol=Overlay("conv.bit")
ol.download();
print(ol.ip_dict.keys())
conv=ol.Conv_0
dat_in=xlnk.cma_array(shape=((in_channel+K-1)//K,in_height,in_width,K),cacheable=0,dtype=np.int16)
wt=xlnk.cma_array(shape=(out_channel,(in_channel+K-1)//K, Ky,Kx,K),cacheable=0,dtype=np.int16)
dat_out=xlnk.cma_array(shape=((out_channel+K-1)//K,out_height,out_width,K),cacheable=0,dtype=np.int16)
dat_out_soft=xlnk.cma_array(shape=((out_channel+K-1)//K,out_height,out_width,K),cacheable=0,dtype=np.int16)
for i in range(dat_in.shape[0]):
for j in range(dat_in.shape[1]):
for k in range(dat_in.shape[2]):
for l in range(dat_in.shape[3]):
if(i*K+l<in_channel):
dat_in[i][j][k][l]=random.randint(-1000,1000) #(j*dat_in.shape[2]+k);
for i in range(wt.shape[0]):
for j in range(wt.shape[1]):
for k in range(wt.shape[2]):
for l in range(wt.shape[3]):
for m in range(wt.shape[4]):
wt[i][j][k][l][m]=random.randint(-1000,1000) #j*Kx+k;# if(m==0) else 0;#j*Kx+k;
def Run_Conv(chin,chout,kx,ky,sx,sy,mode,relu_en,feature_in,feature_in_precision,weight,weight_precision,feature_out,feature_out_precision):
conv.write(0x10,chin)
conv.write(0x18,feature_in.shape[1])
conv.write(0x20,feature_in.shape[2])
conv.write(0x28,chout)
conv.write(0x30,kx)
conv.write(0x38,ky)
conv.write(0x40,sx)
conv.write(0x48,sy)
conv.write(0x50,mode)
conv.write(0x58,relu_en)
conv.write(0x60,feature_in.physical_address)
conv.write(0x68,feature_in_precision)
conv.write(0x70,weight.physical_address)
conv.write(0x78,weight_precision)
conv.write(0x80,feature_out.physical_address)
conv.write(0x88,feature_out_precision)
#print("conv ip start")
starttime=time.time()
conv.write(0, (conv.read(0)&0x80)|0x01 ) #start pool IP
#poll the done bit
tp=conv.read(0)
while not((tp>>1)&0x1):
tp=conv.read(0)
#print("conv ip done")
endtime=time.time()
print("Hardware run time=%s s"%(endtime-starttime))
def Run_Conv_Soft(chin,chout,kx,ky,sx,sy,mode,relu_en,feature_in,feature_in_precision,weight,weight_precision,feature_out,feature_out_precision):
if(mode==0):
pad_x=0
pad_y=0
else:
pad_x=(kx-1)//2
pad_y=(ky-1)//2
for i in range(chout):
for j in range(feature_out.shape[1]):
for k in range(feature_out.shape[2]):
sum=np.int64(0)
for c in range(chin):
for ii in range(ky):
for jj in range(kx):
row=j*sy-pad_y+ii
col=k*sx-pad_x+jj
if not (row<0 or col<0 or row>=feature_in.shape[1] or col>=feature_in.shape[2]):
dat=feature_in[c//K][row][col][c%K]
wt=weight[i][c//K][ii][jj][c%K]
#print("%d %d=%d, wt=%d "%(row,col,dat,wt))
sum=sum+int(dat)*int(wt)
res=sum>>(feature_in_precision+weight_precision-feature_out_precision)
if(res>32767):
res=32767
else:
if(res<-32768):
res=32768
feature_out[i//K][j][k][i%K]=res
Run_Conv(in_channel,out_channel,Kx,Ky,Sx,Sy,MODE,RELU_EN,dat_in,5,wt,0,dat_out,0);
starttime=time.time()
Run_Conv_Soft(in_channel,out_channel,Kx,Ky,Sx,Sy,MODE,RELU_EN,dat_in,5,wt,0,dat_out_soft,0);
endtime=time.time()
print("Software run time=%s s"%(endtime-starttime))
flag=1
for i in range(dat_out.shape[0]):
for j in range(dat_out.shape[1]):
for k in range(dat_out.shape[2]):
for l in range(dat_out.shape[3]):
if(dat_out[i][j][k][l]!=dat_out_soft[i][j][k][l]):
flag=0
print("Out_ [%d][%d][%d][%d]=%d"%(i,j,k,l,dat_out[i][j][k][l]));
print("Out_Soft[%d][%d][%d][%d]=%d"%(i,j,k,l,dat_out_soft[i][j][k][l]));
if(flag==1):
print("============================\n result_match\n============================\n");
else:
print("============================\n result_mismatch\n============================\n");















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









