









池化算法设计
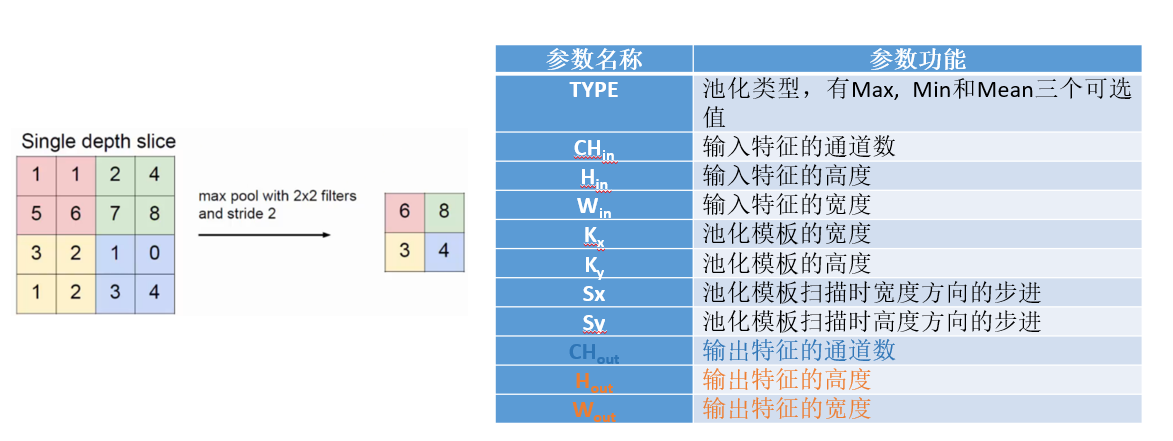
将池化操作分为两步horizontal和vertical:
- 先做横向的池化,将池化结果存下来,传给垂直方向的池化
- 再做垂直方向的池化
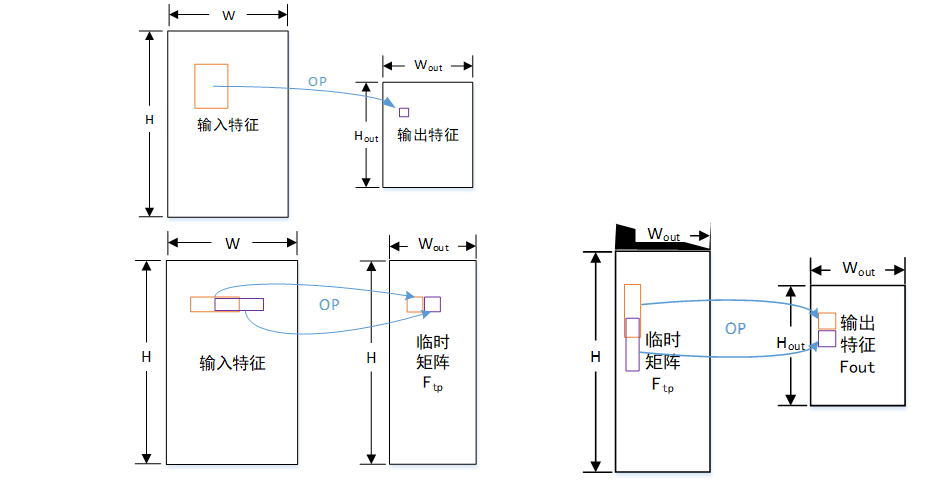
例如一个3*2的池化
先做水平horizontal方向的1*2的池化:
再做垂直vertical方向3*1的池化:
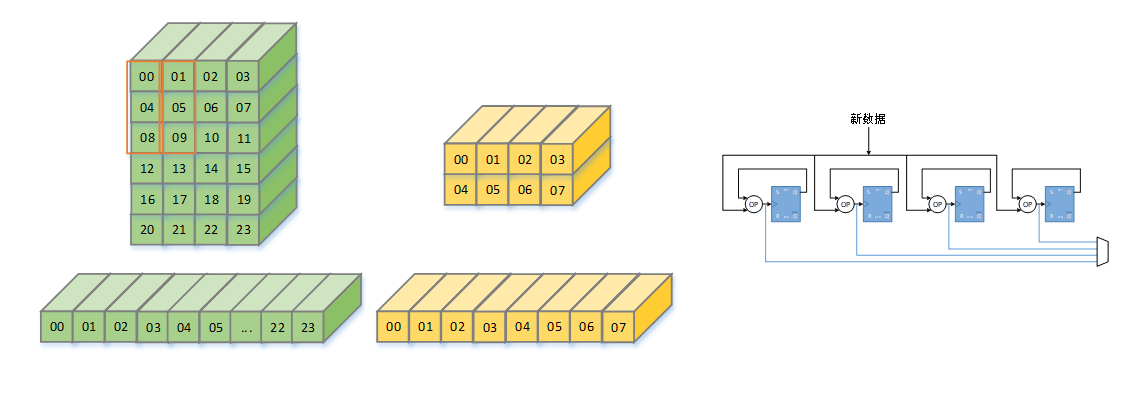
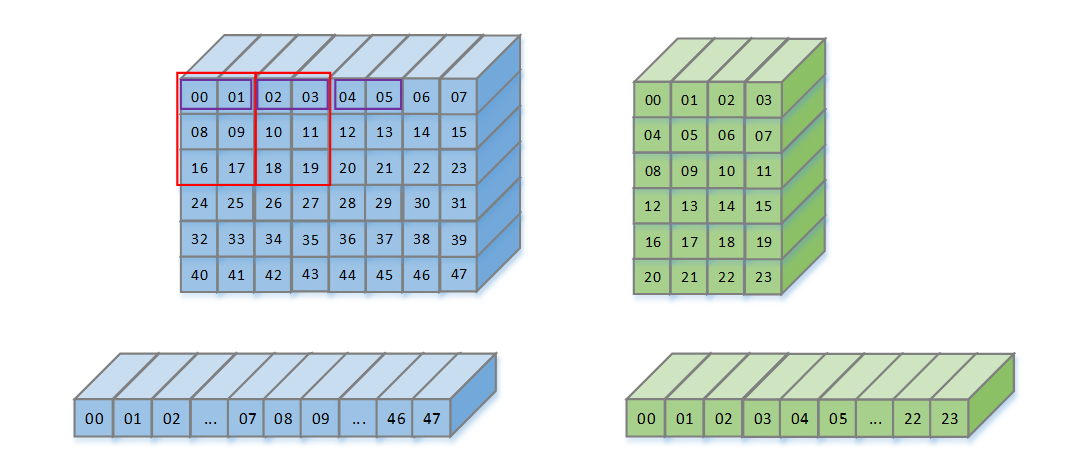
硬件设计
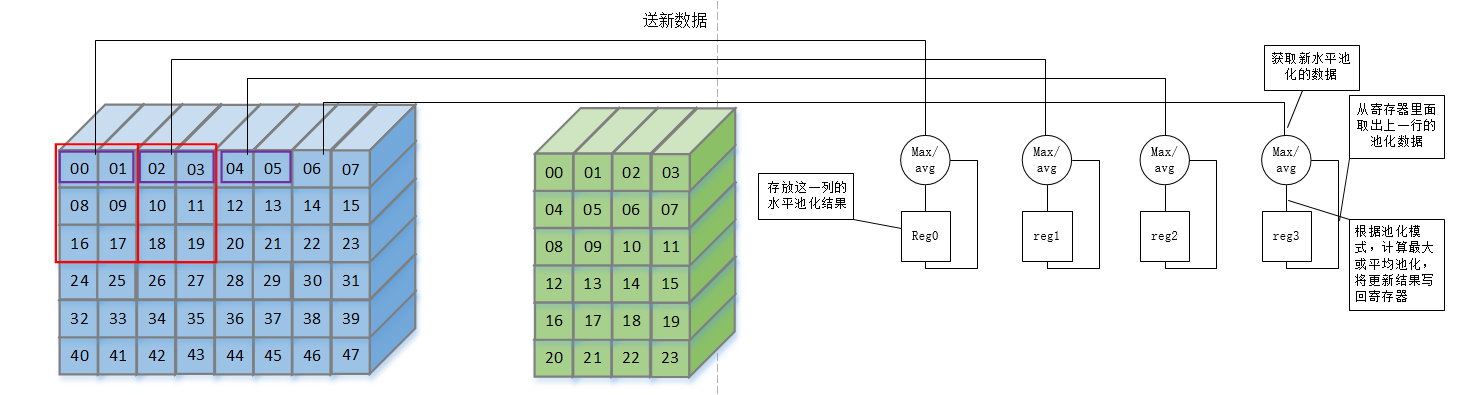
128*128的特征图,需要128*8*16bit = 16k的寄存器,需要寄存器的数量太多
可以用16K的BRAM来实现,从对寄存器的读和写,变为对地址的读和写
stream设计实现
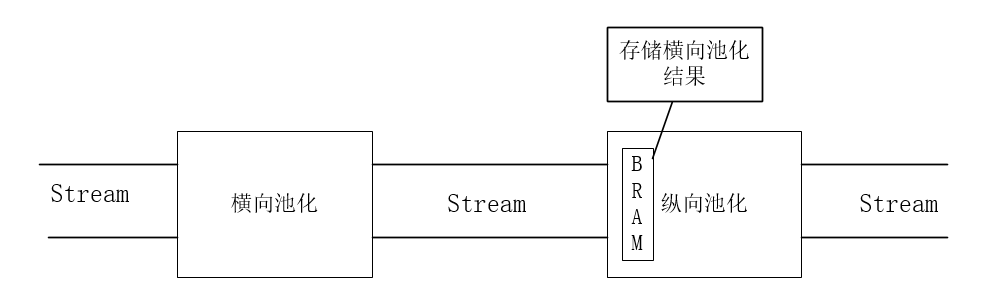
接口设计
- 用AXI-HP接口:

数组a储存在外部存储器之中,HLS生成的电路会从数组a对应的地址依次读回数据。这样写确实可以实现对数组a的访问,但是很可惜,这些访问在电路实现时采用的是基于AXI-HP协议的单次访问的形式,而不是突发传输,因此总线利用效率极低
- HLS工具生成的AXI-HP口进行突发传输,只能通过使用memcpy函数:

使用memcpy进行传输,依旧有一定的弊端。首先,这会使对于数组a的访问不再那么灵活,且需要一块内部存储区(数组val)对外部存储器a中的数据进行缓存。其次,memcpy函数依旧无法使用AXI-HP中outstanding的特性,对于DDR这类需要预充电的外部存储器而言,其总线利用效率依旧不高。
- 基于axi-stream的数据访问是一种比AXI-HP更加高效的方法:
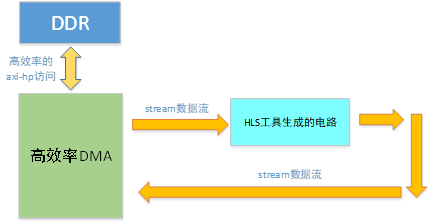
一个高效的DMA作为stream的source,而HLS生成的电路作为stream的sink。高效的DMA本身通过AXI-HP接口从外部存储器中获取数据,并通过axi-stream送给HLS生成的运算电路。此方法与之前的方法相比,优势在于电路外部的DMA工作时可以使用axi-hp的burst与outstanding的特性,总线利用效率比使用HLS工具生成的axi-hp接口的效率高出很多。
代码
pool.h
#ifndef __POOL_H__
#define __POOL_H__
#include <iostream>
#include <ap_int.h>
#include <hls_stream.h>
#define K 8
#define POOL_2D_BUF_DEP 512
#define MAX(A, B) ((A>B)?A:B)
typedef ap_int<16> data_type;
typedef ap_int<16*K> tile_type;
typedef struct{
tile_type data;
bool last;
}stream_out_type;
void pool(hls::stream<tile_type> &stream_in, hls::stream<stream_out_type> &stream_out,
ap_uint<16> div_tile_num, ap_uint<16> in_height, ap_uint<16> in_width,
ap_uint<16> out_height, ap_uint<16> out_width,
ap_uint<16> padding_x, ap_uint<16> padding_y);
void pool_1D(hls::stream<tile_type> &stream_in, hls::stream<tile_type> &stream_out_1d,
ap_uint<16> div_tile_num, ap_uint<16> in_height, ap_uint<16> in_width,ap_uint<16> padding_x);
void pool_2D(hls::stream<tile_type> &stream_out_1d, hls::stream<tile_type> &stream_out_2d,
ap_uint<16> div_tile_num, ap_uint<16> in_height, ap_uint<16> out_width,ap_uint<16> padding_y);
void hs2axis(hls::stream<tile_type> &stream_out_2d, hls::stream<stream_out_type> &stream_out,
ap_uint<16> div_tile_num,ap_uint<16> out_height, ap_uint<16> out_width);
#endif
pool.cpp
#include "pool.h"
void pool(hls::stream<tile_type> &stream_in, hls::stream<stream_out_type> &stream_out,
ap_uint<16> div_tile_num, ap_uint<16> in_height, ap_uint<16> in_width,
ap_uint<16> out_height, ap_uint<16> out_width,
ap_uint<16> padding_x, ap_uint<16> padding_y)
{
#pragma HLS INTERFACE s_axilite port = return
#pragma HLS INTERFACE s_axilite port=div_tile_num
#pragma HLS INTERFACE s_axilite port=padding_x
#pragma HLS INTERFACE s_axilite port=in_height
#pragma HLS INTERFACE s_axilite port=in_width
#pragma HLS INTERFACE s_axilite port=out_height
#pragma HLS INTERFACE s_axilite port=padding_y
#pragma HLS INTERFACE s_axilite port=out_width
// dataflow 实现任务级并行
#pragma HLS DATAFLOW
// 基于axi-stream进行数据访问
#pragma HLS INTERFACE axis register both port = stream_out
#pragma HLS INTERFACE axis register both port = stream_in
hls::stream<tile_type> stream_out_1d;
#pragma HLS STREAM variable = stream_tp depth = 8 dim = 1
hls::stream<tile_type> stream_out_2d;
pool_1D(stream_in, stream_out_1d, div_tile_num, in_height, in_width, padding_x);
pool_2D(stream_out_1d, stream_out_2d, div_tile_num, in_height, out_width, padding_y);
hs2axis(stream_out_2d, stream_out, div_tile_num, out_height, out_width);
}
void pool_1D(hls::stream<tile_type> &stream_in, hls::stream<tile_type> &stream_out_1d,
ap_uint<16> div_tile_num, ap_uint<16> in_height, ap_uint<16> in_width,ap_uint<16> padding_x)
{
#pragma HLS INTERFACE ap_stable port = in_width
#pragma HLS INTERFACE ap_stable port = padding_x
#pragma HLS INTERFACE ap_stable port = in_height
#pragma HLS INTERFACE ap_stable port = div_tile_num
tile_type dff;
for (int c = 0; c < div_tile_num; c++)
{
#pragma HLS LOOP_TRIPCOUNT min = 1 max = 1 avg = 1
for (int i = 0; i < in_height; i++)
{
#pragma HLS LOOP_TRIPCOUNT min = 20 max = 20 avg = 20
for (int j = 0; j < in_width; j++)
{
#pragma HLS PIPELINE II = 1
#pragma HLS LOOP_TRIPCOUNT min = 20 max = 20 avg = 20
tile_type in_block = stream_in.read();
tile_type tp_out;
for (int k = 0; k < K; k++)
{
if (j % padding_x == 0) // width_index == 0,3,6,,,,, record first value
tp_out.range(16 * k + 15, 16 * k) = in_block.range(16 * k + 15, 16 * k);
else // update value data = max(pre data, now data)
tp_out.range(16 * k + 15, 16 * k) = MAX((data_type)dff.range(16 * k + 15, 16 * k), (data_type)in_block.range(16 * k + 15, 16 * k));
}
if ((j + 1) % padding_x == 0) // if need output:width_index = 2,5,8,,,,
{
stream_out_1d.write(tp_out);
// std::cout<<"pool_1D_out:"<<std::hex<<tp_out<<std::endl;
}
else // update max value block
dff = tp_out;
}
}
}
}
void pool_2D(hls::stream<tile_type> &stream_out_1d, hls::stream<tile_type> &stream_out_2d,
ap_uint<16> div_tile_num, ap_uint<16> in_height, ap_uint<16> out_width,ap_uint<16> padding_y)
{
#pragma HLS INTERFACE ap_stable port=div_tile_num
#pragma HLS INTERFACE ap_stable port=in_height
#pragma HLS INTERFACE ap_stable port=out_width
#pragma HLS INTERFACE ap_stable port=padding_y
static tile_type buf[POOL_2D_BUF_DEP];
int ptr = 0;
for (int c = 0; c < div_tile_num; c++)
{
#pragma HLS LOOP_TRIPCOUNT min = 1 max = 1 avg = 1
for (int i = 0; i < in_height; i++)
{
#pragma HLS LOOP_TRIPCOUNT min = 20 max = 20 avg = 20
for (int j = 0; j < out_width; j++)
{
//#pragma HLS DEPENDENCE variable=buf inter true
#pragma HLS PIPELINE
#pragma HLS LOOP_TRIPCOUNT min = 10 max = 10 avg = 10
tile_type in_block = stream_out_1d.read();
tile_type tp_in;
tile_type tp_out;
tp_in = buf[j];
for (int k = 0; k < K; k++)
{
if ((i % padding_y) == 0)
tp_out.range(16 * k + 15, 16 * k) = in_block.range(16 * k + 15, 16 * k);
else
tp_out.range(16 * k + 15, 16 * k) = MAX((data_type)tp_in.range(16 * k + 15, 16 * k), (data_type)in_block.range(16 * k + 15, 16 * k));
}
if ((i + 1) % padding_y == 0) // if need output
stream_out_2d.write(tp_out);
else
buf[j] = tp_out;
}
}
}
}
void hs2axis(hls::stream<tile_type> &stream_out_2d, hls::stream<stream_out_type> &stream_out,
ap_uint<16> div_tile_num,ap_uint<16> out_height, ap_uint<16> out_width)
{
#pragma HLS INTERFACE ap_stable port = out_height
#pragma HLS INTERFACE ap_stable port = out_width
#pragma HLS INTERFACE ap_stable port = div_tile_num
for (int i = 0; i < out_height * out_width * div_tile_num; i++)
{
#pragma HLS PIPELINE II = 1
#pragma HLS LOOP_TRIPCOUNT min = 200 max = 200 avg = 200
stream_out_type tp;
tp.data = stream_out_2d.read();
if (i == ( out_height * out_width * div_tile_num - 1))
tp.last = 1;
else
tp.last = 0;
stream_out.write(tp);
}
}
main.cpp
#include "pool.h"
#include <stdio.h>
void pool_soft(hls::stream<tile_type> &in,hls::stream<stream_out_type> &out,
int ch_div_K,int height_in,int width_in,
int height_out,int width_out,int Kx,int Ky);
int main(void)
{
hls::stream<tile_type> in,in_soft;
hls::stream<stream_out_type> out,out_soft;
int ch_div_K=4;
int height_in=4;
int width_in=4;
int Kx=2;
int Ky=2;
for(int c=0;c<ch_div_K;c++)
{
for(int i=0;i<height_in*width_in;i++)
{
tile_type tp;
for(int j=0;j<K;j++)
{
if(j==0)
tp.range(16*j+15,16*j)=rand()%4001-2000;
else
tp.range(16*j+15,16*j)=0;
}
in.write(tp);
in_soft.write(tp);
}
}
pool(in,out,ch_div_K,height_in,width_in,height_in/Ky,width_in/Kx,Kx,Ky);
pool_soft(in_soft,out_soft,ch_div_K,height_in,width_in,height_in/Ky,width_in/Kx,Kx,Ky);
int flag=1;
for(int c=0;c<ch_div_K;c++)
{
for(int i=0;i<(height_in/Ky)*(width_in/Kx);i++)
{
stream_out_type tp=out.read();
stream_out_type tp_soft=out_soft.read();
if(tp.data!=tp_soft.data)
{
flag=0;
std::cout<<"out :"<<i/(width_in/Kx)<<","<<i%(width_in/Kx)<<":\t"<<std::hex<<tp.data<<",last="<<tp.last<<std::endl;
std::cout<<"out_soft:"<<i/(width_in/Kx)<<","<<i%(width_in/Kx)<<":\t"<<std::hex<<tp_soft.data<<",last="<<tp.last<<std::endl<<std::endl;
}
}
}
if(flag==1)
printf("match\n");
else
printf("mis-match\n");
}
void pool_soft(hls::stream<tile_type> &in,hls::stream<stream_out_type> &out,
int ch_div_K,int height_in,int width_in,
int height_out,int width_out,int Kx,int Ky)
{
tile_type in_array[10000];
for(int i=0;i<height_in*height_in*ch_div_K;i++)
in_array[i]=in.read();
for(int m=0;m<ch_div_K;m++)
{
for(int i=0;i<height_out;i++)
{
for(int j=0;j<width_out;j++)
{
tile_type tp;
for(int k=0;k<K;k++)
tp.range(16*k+15,16*k)=-32768;
for(int ii=0;ii<Ky;ii++)
for(int jj=0;jj<Kx;jj++)
{
int row=i*Kx+ii;
int col=j*Ky+jj;
tile_type dat=in_array[m*width_in*height_in+row*width_in+col];
for(int k=0;k<K;k++)
tp.range(16*k+15,16*k)=MAX((data_type)tp.range(16*k+15,16*k),(data_type)dat.range(16*k+15,16*k));
}
stream_out_type tp_stream;tp_stream.data=tp;tp_stream.last=0;
out.write(tp_stream);
}
}
}
}
运行
C仿真:
C综合:

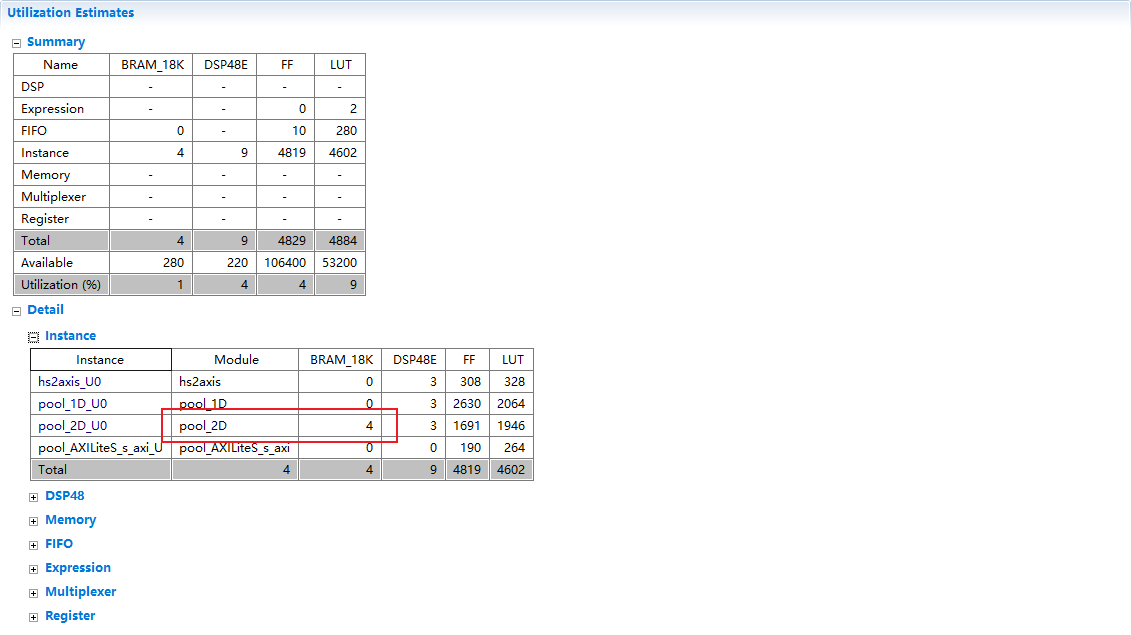
这里用了四个BRAM,是因为需要存的数据是512*(K=8)*16 = 64K/18K向上取整= 4*18K














 2151
2151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









