







小罗碎碎念
本期推文介绍的模型是CONCH(CONtrastive learning from Captions for Histopathology)——一个专门为计算病理学开发的视觉语言基础模型。
这个模型我在10-30的推文已经详细分析过,在这篇推送的基础上,我会进一步介绍如何具体使用模型,同时,为了方便大家理解本篇推送内容,我也会大致介绍一下CONCH的架构。

| 作者类型 | 作者姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Ming Y. Lu | 哈佛医学院布里格姆和妇女医院病理科 |
| 第一作者 | Bowen Chen | 哈佛医学院布里格姆和妇女医院病理科 |
| 第一作者 | Drew F. K. Williamson | 哈佛医学院布里格姆和妇女医院病理科 |
| 通讯作者 | Faisal Mahmood | 哈佛医学院布里格姆和妇女医院病理科 |
CONCH在14个不同的基准测试中进行了评估,这些测试涉及病理学图像和/或文本的多种下游任务,包括组织学图像分类、分割、描述生成以及文本到图像和图像到文本的检索。CONCH在这些任务上都取得了最先进的性能,并且可以在无监督微调的情况下直接改善其他模型的性能。
文章强调了数字病理学的快速发展以及深度学习在病理学任务中的应用,但也指出了模型训练中存在的标签稀缺问题,以及大多数模型仅利用图像数据的限制。CONCH模型通过结合图像和文本数据,模拟实际病理学家的工作流程,从而克服了这些限制。
研究结果表明,CONCH在多种病理学任务上都表现出色,包括零样本分类、检索和分割。此外,CONCH还展示了在罕见疾病分类和少量样本学习中的潜力。文章还讨论了CONCH在实际应用中的潜在价值,包括在病理学实践中的语言使用、教育和研究中的应用,以及在临床病理学中的潜在影响。最后,文章指出了当前视觉-语言预训练模型的局限性,并对未来的研究方向提出了建议。
一、什么是CONCH
CONCH(CONtrastive learning from Captions for Histopathology)是一种用于组织病理学的视觉语言基础模型,它在包含 117 万图像 - 标题对的视觉语言数据集上进行了预训练。与其他视觉语言基础模型相比,其在计算病理学的 14 项任务(涵盖图像分类、文本到图像、图像到文本检索、标题生成以及组织分割等)中展现出了最先进的性能。
关于使用 CONCH 的原因,与那些仅在苏木精 - 伊红(H&E)图像上进行预训练的、流行的计算病理学自监督编码器相比,CONCH 可为免疫组化(IHC)和特殊染色等非 H&E 染色图像生成更具性能优势的表征,并且可用于涉及组织病理学图像和 / 或文本的众多下游任务。
此外,CONCH 在预训练时未使用诸如癌症基因组图谱(TCGA)、宾夕法尼亚图像分析平台(PAIP)、基因型 - 组织表达(GTEX)等大型公共组织学切片集(这些在计算病理学的基准开发中常被使用),所以 CONCH 可供研究团体在构建和评估病理学人工智能模型时使用,且在公共基准或私人组织病理学切片集方面面临的数据污染风险极小。
1-1:数据清洗流程
-
数据源:公开的医学文献和数据库、内部病理图像和报告以及公开数据集
-
对象检测器(Object detector):使用YOLOv5模型来识别和提取图像中的对象。这个过程是为了从文献中自动提取病理图像。
-
标题分割器(Caption splitter):使用一个经过预训练的生成式变换器(GPT)模型来将描述多个图像的标题分割成单独的子标题。这个步骤是为了处理包含多个子图像的图像面板。
-
匹配器(Matcher):使用一个在清理过的教育数据集上训练的CLIP模型来将分割后的子图像与子标题进行匹配。这个过程通过计算图像嵌入和文本嵌入在对齐潜在空间中的余弦相似性得分来完成。
-
数据集过滤:从原始的179万图像-文本对数据集中,首先排除了非人类样本,创建了一个117万人类样本的数据集。然后,进一步通过训练一个分类器来识别H&E(苏木精和伊红)染色,从而过滤出457,373对H&E样本,以及713,595对IHC + 特殊染色样本。
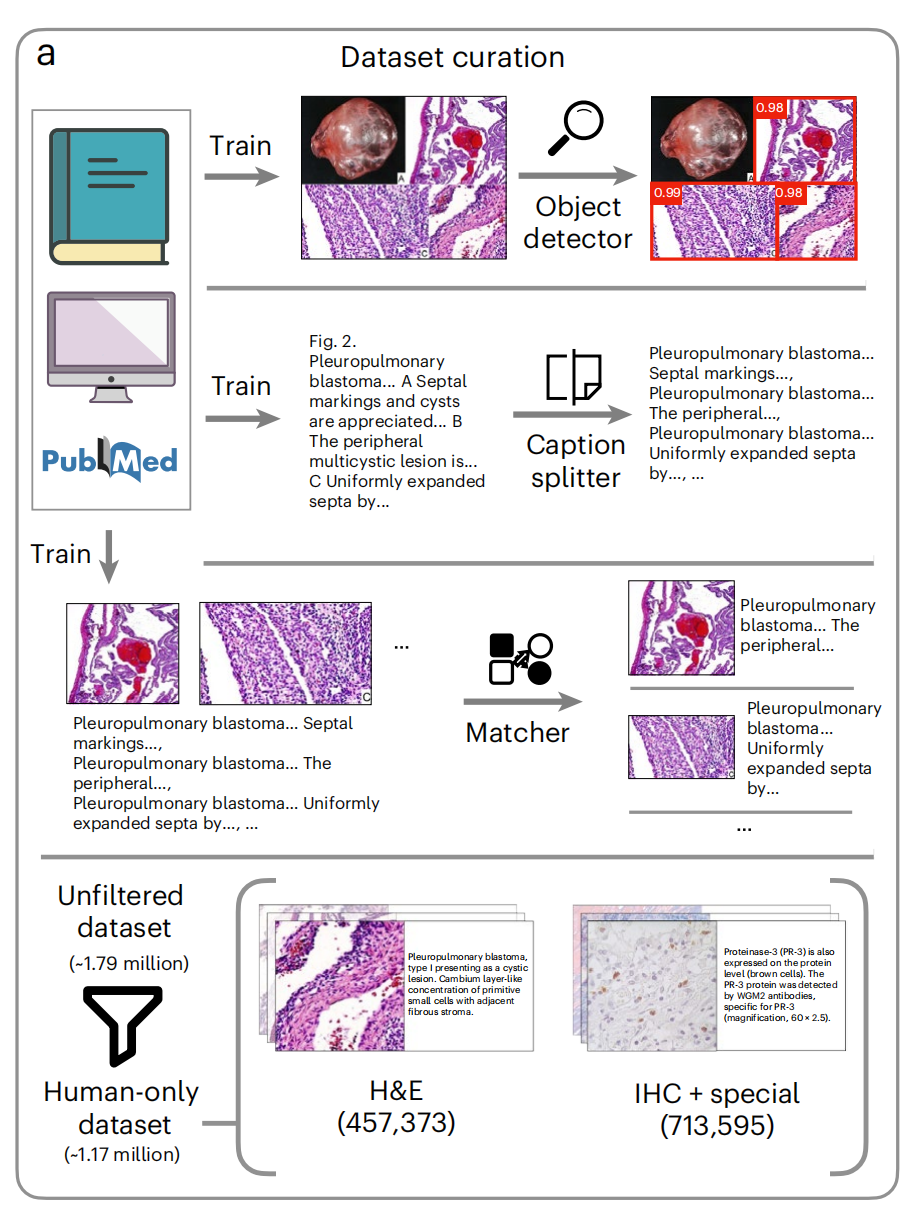
整体上,这个流程自动化地处理和过滤了大量病理图像和相关文本数据,为训练视觉-语言模型准备了一个清洗过的数据集。
1-2:数据集主题分布
这张图展示了数据集的特征描述,具体包括不同人体系统的图像数量和标题的字数分布。
-
人体系统图像数量:图中列出了多个人体系统,并为每个系统提供了图像数量。例如,胃肠道轨迹有最多的图像(121,209张),而眼睛的图像最少(11,569张)。
-
标题字数分布:右下角的直方图展示了标题字数的分布。图中有两个数据集的分布:PMC-Path(紫色)和EDU(蓝色)。可以看到,大多数标题的字数集中在较短的范围,随着字数增加,标题数量迅速下降。
-
数据集比较:从直方图可以观察到PMC-Path数据集的标题通常比EDU数据集的标题要长,这可能反映了两个数据源内容的差异。
-
图标表示:每个人体系统前都有一个简单的图标,帮助快速识别对应的系统。
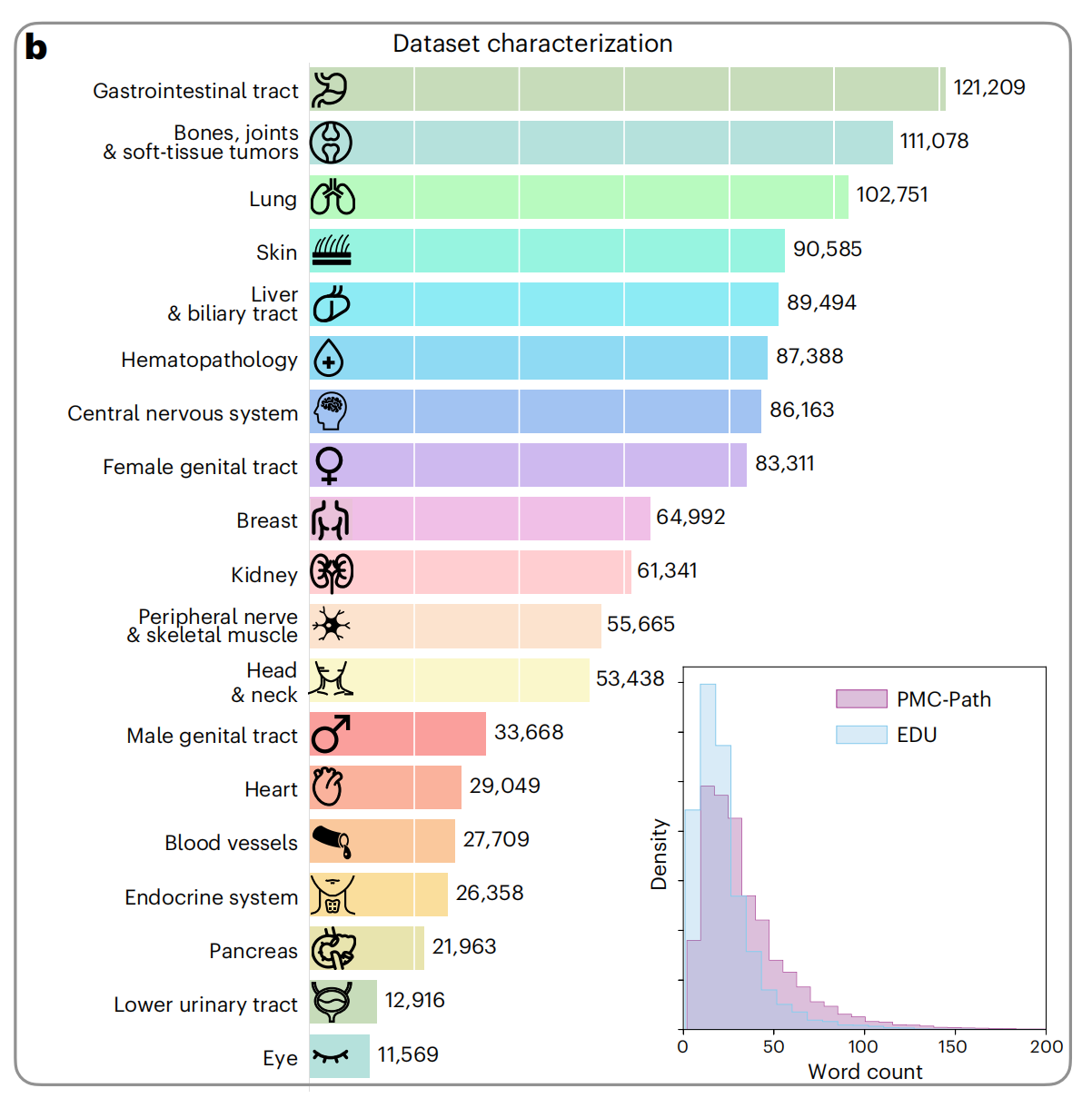
整体上,这个图表提供了数据集的概览,显示了不同人体系统的图像分布和标题的一般特征,对理解数据集的组成和特性很有帮助。
1-3:视觉-语言预训练设置
这张图展示了一个用于病理图像分析的预训练算法架构。
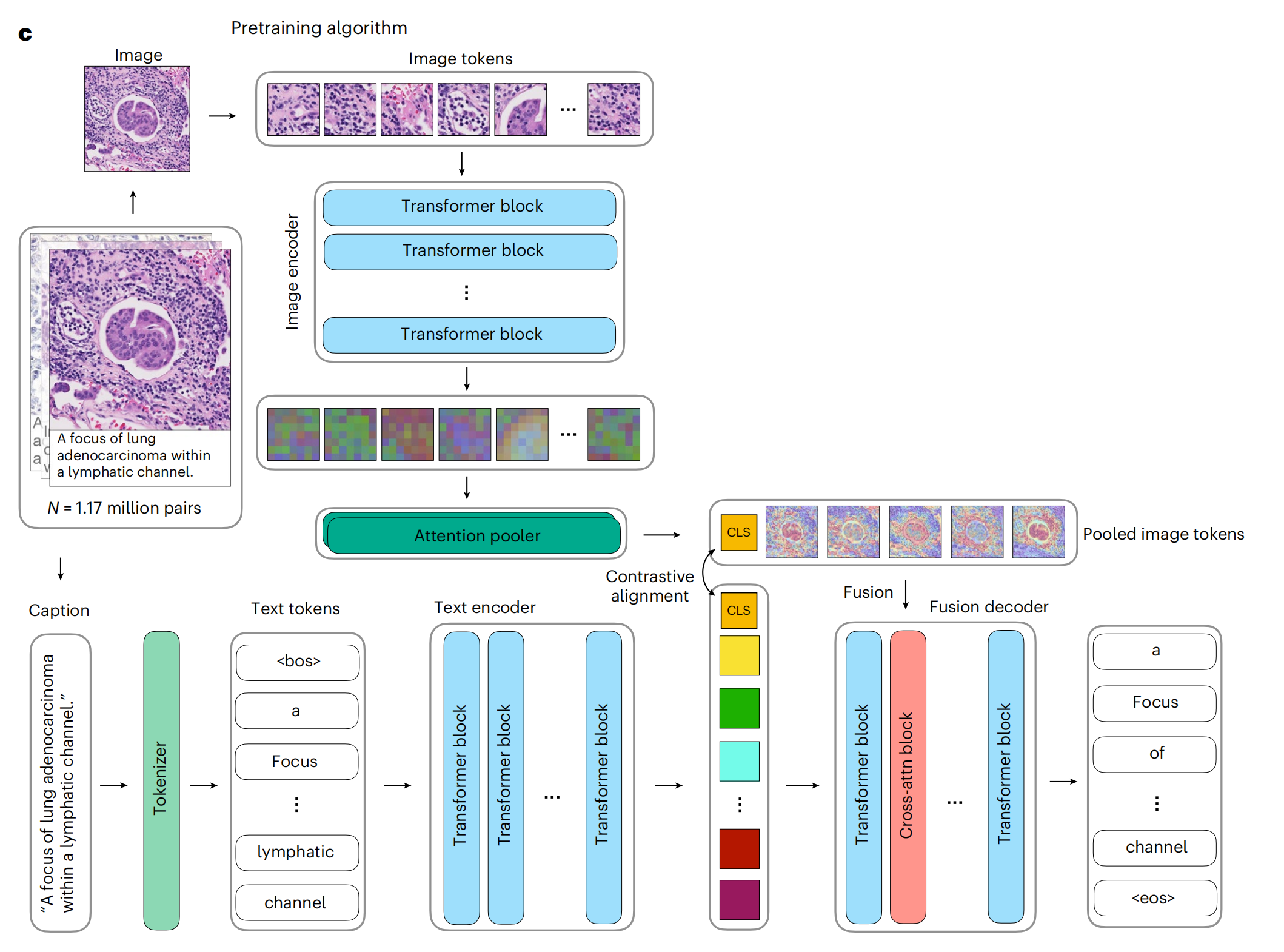
具体细节如下:
-
图像编码器(Image encoder):
- 接收输入为病理图像。
- 图像被分割成多个图像块(Image tokens),这些块随后被送入Transformer模块进行处理。
- Transformer模块由多个Transformer块(Transformer block)组成,用于提取图像特征。
-
注意力池化器(Attention pooler):
- 处理完所有图像块后,通过注意力池化器(Attention pooler)聚合信息,生成汇总的图像令牌(Pooled image tokens)。
-
文本编码器(Text encoder):
- 接收与图像相对应的描述性文本(Caption)。
- 文本被标记化(Tokenized),生成文本令牌(Text tokens)。
- 这些文本令牌同样通过Transformer块进行处理,以提取文本特征。
-
对比性对齐(Contrastive alignment):
- 目的是在图像和文本的特征空间中对齐它们,使得相关的图像和文本在特征空间中彼此靠近。
- 通过最大化图像和文本嵌入的余弦相似性来实现。
-
融合解码器(Fusion decoder):
- 结合图像和文本的特征,用于生成描述或执行其他多模态任务。
- 包含交叉注意力(Cross-attention)机制,允许模型在生成过程中同时考虑图像和文本信息。
-
预训练数据:
- 使用了117万图像-文本对进行预训练,这些数据对用于训练模型以理解图像内容和相关文本描述之间的关系。
整体上,这个架构通过结合图像和文本信息,利用Transformer架构和对比学习,来训练一个能够理解病理图像和对应文本描述的模型。这对于后续的细粒度分析、图像检索、自动报告生成等任务至关重要。
1-4:性能比较
这张雷达图展示了不同模型在多种下游任务上的性能表现。这些任务包括分类(Classification)、检索(Retrieval)和分割(Segmentation)。
图中比较了四种模型:CONCH(青色)、PLIP(黄色)、BiomedCLIP(蓝色)和OpenAICLIP(紫色)。
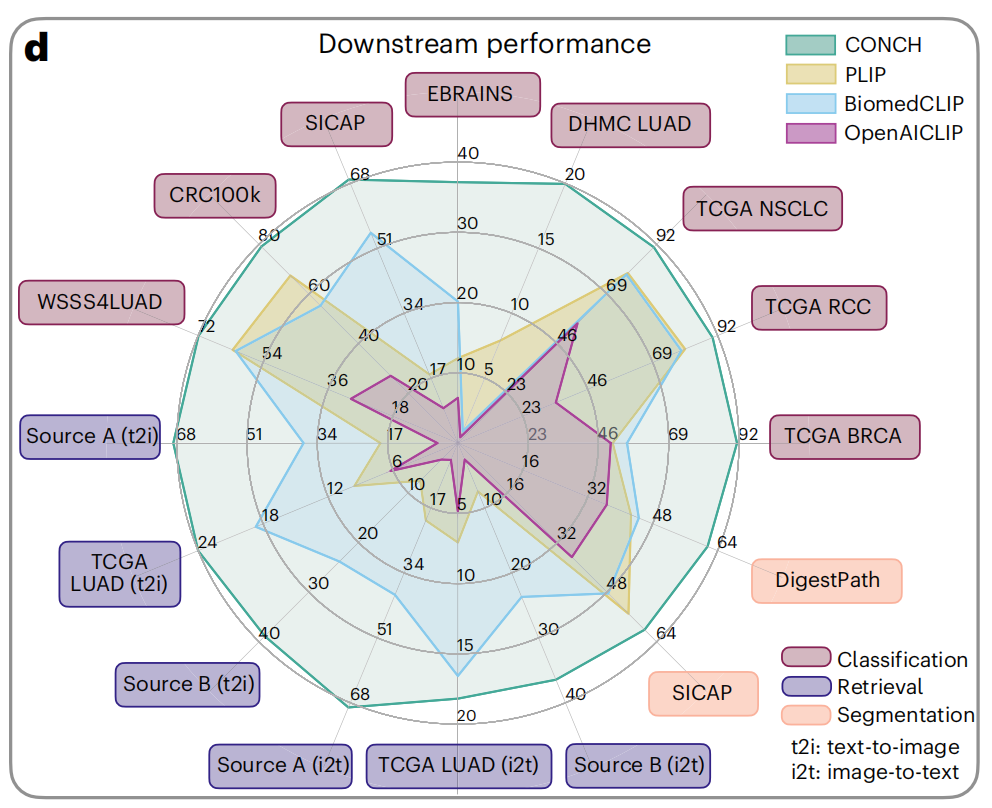
任务和数据集
- SICAP:前列腺癌的Gleason分级。
- EBRAINS:脑肿瘤的细粒度亚型分类。
- DHMC LUAD:肺腺癌的组织学模式分类。
- TCGA NSCLC:非小细胞肺癌的亚型分类。
- TCGA RCC:肾细胞癌的亚型分类。
- TCGA BRCA:乳腺癌的亚型分类。
- CRC100k:结直肠腺癌的组织分类。
- WSS4LUAD:肺腺癌的图像块分类。
- Source A (t2i) 和 Source B (t2i):两个用于文本到图像和图像到文本检索的数据集。
- TCGA LUAD (i2t):肺腺癌的图像块,用于图像到文本的检索。
性能指标
- 每个任务的得分范围从0到100,反映了模型在该任务上的性能。
- 图中每个轴代表一个任务,不同颜色的区域表示不同模型在该任务上的性能。
模型比较
- CONCH在大多数任务上都显示出较好的性能,特别是在分类任务上。
- PLIP和BiomedCLIP在某些任务上表现接近,但在其他任务上CONCH明显领先。
- OpenACLIP在某些任务上表现较弱,特别是在检索任务上。
二、配置模型
2-1:配置环境
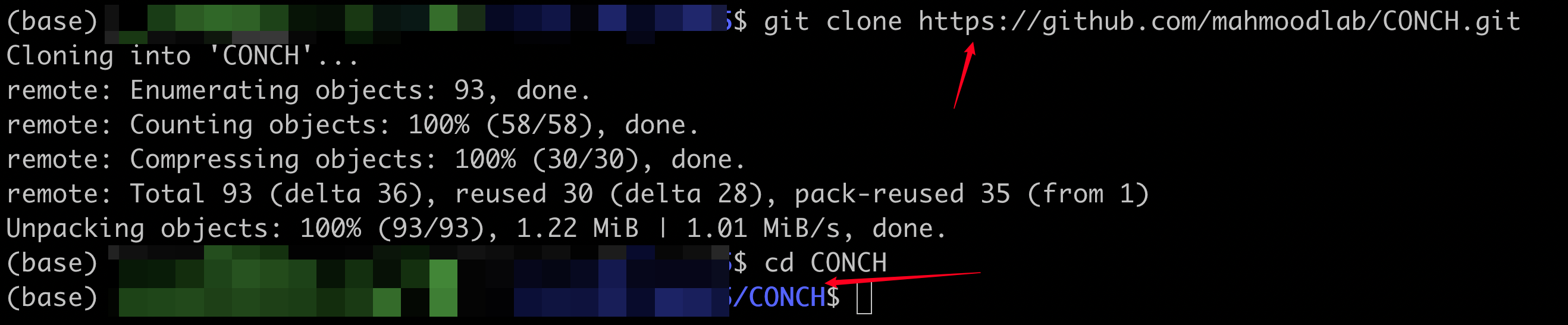
首先克隆该仓库,然后切换到相应目录。
(注:“cd”是计算机操作命令“change directory”的缩写,意为“切换目录”“改变目录”。)
git clone https://github.com/mahmoodlab/CONCH.git
cd CONCH
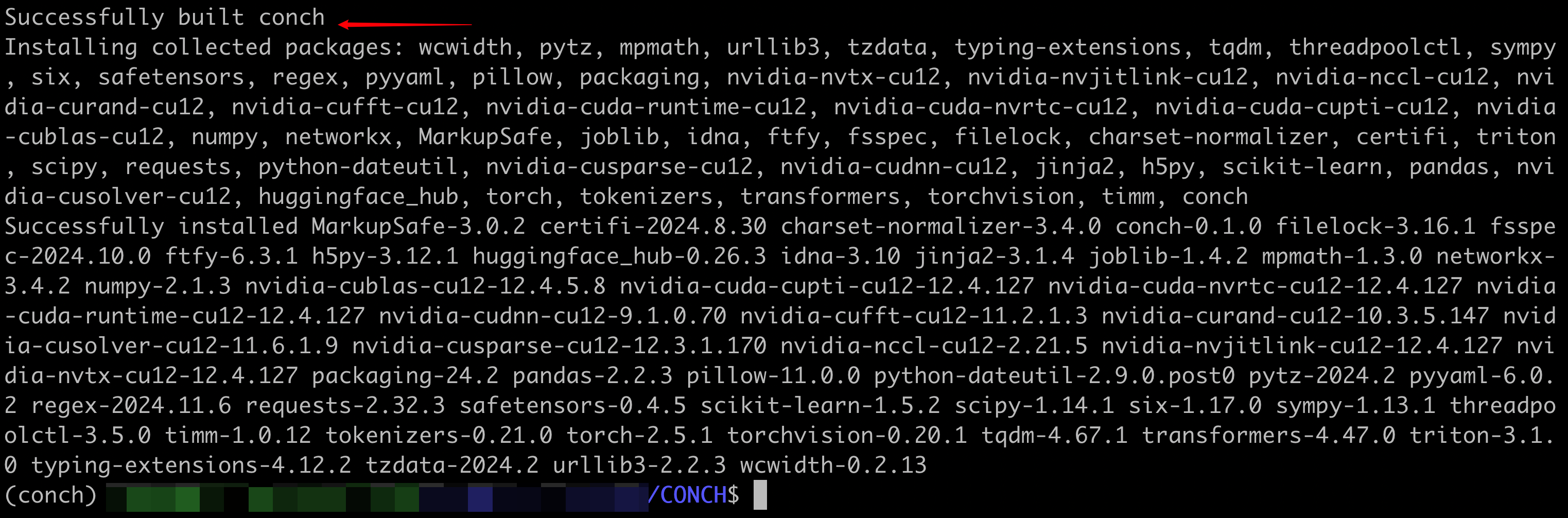
然后创建一个Conda环境并安装依赖项。
(注:“Conda”是一种开源的软件包管理系统和环境管理系统,常用于Python等编程语言的项目中,方便管理不同项目所需的各种软件包及其运行环境。依赖项,也就是项目运行所依赖的其他软件包、库等内容。)
# 使用conda创建一个名为conch的新虚拟环境,指定Python版本为3.10,并且自动确认(不需要手动输入y来确认)
conda create -n conch python=3.10 -y
# 激活名为conch的虚拟环境,这样后续的操作(比如安装包等)都会在这个虚拟环境内进行
conda activate conch
# 使用pip命令将pip工具本身升级到最新版本,确保可以使用最新的pip功能来安装其他包
pip install --upgrade pip
# 使用pip以可编辑模式(editable mode)安装当前目录(. 表示当前目录)下的Python包或项目,方便在开发过程中对代码修改后能即时生效,常用于开发阶段的本地项目安装
pip install -e.
2-2:准备&加载模型
从Huggingface模型页面申请获取模型权重的访问权限。
下载模型权重参数
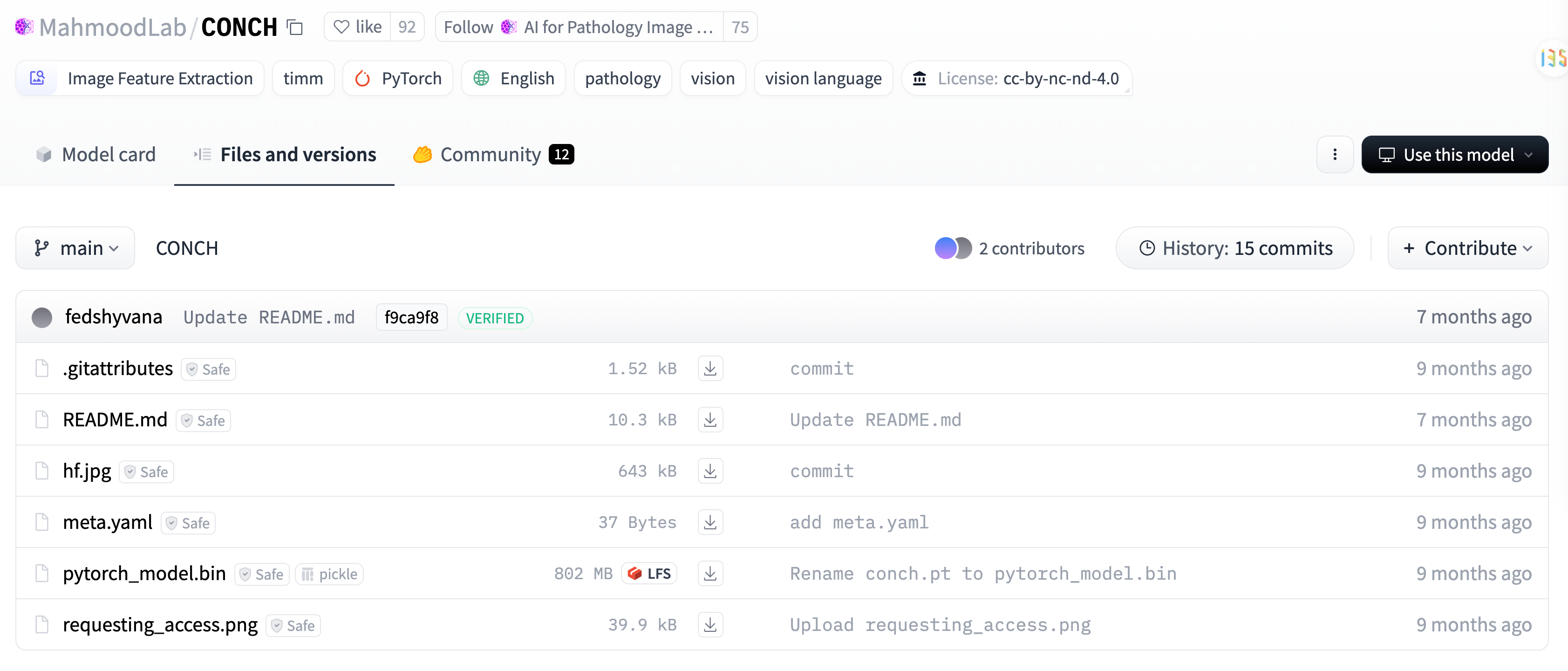
首先在仓库根目录内创建“checkpoints”文件夹。
(注:“checkpoints”通常可理解为检查点、保存点等意思,在这里指用来存放相关检查点数据等内容的文件夹;)
# 使用mkdir命令创建目录,-p参数表示如果上级目录(这里是checkpoints)不存在时,会自动创建上级目录以及所指定的完整目录路径(即checkpoints/conch/),
# 这条命令的目的就是确保创建出checkpoints/conch/这个目录结构,若已存在则不会重复创建已有的部分。
mkdir -p checkpoints/conch/

然后下载预训练模型(“pytorch_model.bin”文件),并将其放置在“CONCH/checkpoints/conch/”目录中。
可以下载到本地上传,也可以直接用链接下载到服务器。
cd conch
wget https://huggingface.co/MahmoodLab/CONCH/resolve/main/pytorch_model.bin?download=true
如果你提示无法链接huggingface的话,就自行上传一下吧。
2-3:加载模型
首先导入模型构建器。
# 从名为conch的模块(在CONCH目录下)下的open_clip_custom子模块中,
# 导入create_model_from_pretrained函数。这个函数是用于根据预训练的模型相关配置或权重等,
# 创建出对应的模型实例,方便后续在代码中使用该模型进行如推理、微调等操作。
from conch.open_clip_custom import create_model_from_pretrained
现在,你可以按以下方式加载模型(假设你已将模型权重放在“CONCH/checkpoints/conch/”目录中):
model, preprocess = create_model_from_pretrained("conch_ViT-B-16", checkpoint_path="checkpoints/conch/pytorch_model.bin")
或者,在申请访问权限后,你可以使用以下命令直接从Hugging Face(HF)下载并加载模型。
from conch.open_clip_custom import create_model_from_pretrained
model, preprocess = create_model_from_pretrained('conch_ViT-B-16', "hf_hub:MahmoodLab/conch", hf_auth_token="<your_user_access_token>")
你可能需要通过 hf_auth_token=<your_token> 将你的Hugging Face用户访问令牌提供给 create_model_from_pretrained 函数以进行身份验证。
注意:虽然原始的CONCH模型架构还包含一个使用CoCa标题生成损失进行训练的多模态解码器,但作为一项额外的预防措施,为确保不会无意泄露专有数据或受保护的健康信息(PHI),作者已从公开发布的CONCH权重中移除了解码器的权重。
文本编码器和视觉编码器的权重是完整的,因此论文中呈现的所有关键任务(如图像分类和图文检索)的结果不会受到影响。CONCH作为组织病理学图像和病理学相关文本的通用编码器的能力也依然不受影响。
2-4:视觉编码器
将该模型用作组织病理学图像的视觉编码器
鉴于预训练编码器目前对于计算病理学任务的重要性,在加载模型之后,现在你可以按如下方式使用它来对图像进行嵌入:
from PIL import Image
image = Image.open("path_to_image.jpg")
image = preprocess(image).unsqueeze(0)
with torch.inference_mode():
image_embs = model.encode_image(image, proj_contrast=False, normalize=False)
这将为你提供投影头和归一化之前的图像嵌入,适用于线性探测或在多示例学习框架下处理全切片图像(WSIs)。
对于图像-文本检索任务,你应当按如下方式使用经过归一化和投影的嵌入:
with torch.inference_mode():
image_embs = model.encode_image(image, proj_contrast=True, normalize=True)
2-5:特定用法
作者提供了用于加载模型以及将其用于推理的高级函数。
模型加载:
from conch.open_clip_custom import create_model_from_pretrained
文本分词:
from conch.open_clip_custom import tokenize, get_tokenizer
推理:
from conch.downstream.zeroshot_path import zero_shot_classifier, run_mizero, run_zeroshot
三、具体使用方式
前面的内容只是和大家介绍一下模型的基本内容,为了帮助大家更好的理解模型和应用模型,作者还提供了四个演示代码。
这一部分的内容大家可以在官方的代码仓库中获取,如果基础不好的同学,可以前往我的【知识星球】,我将从这一个项目开始,新建立一个【项目复现】专栏,后续与项目复现有关的文件都会上传到该专栏中。
如果觉得官方链接看着比较吃力的,后续可以前往知识星球【项目复现】专栏获取小罗撰写的教程(这期还没写完,介意的可以等我写完再订阅)。
3-1:加载/使用模型
官方链接
https://github.com/mahmoodlab/CONCH/blob/main/notebooks/basics_usage.ipynb
3-2:图像ROIs/tiles的零样本分类
ROIs(Region of Interest,感兴趣区域)和tiles(瓦片)是指图像中的特定部分。零样本(Zeroshot)分类意味着模型在没有看到特定类别样本的情况下,对新类别进行分类。
展示如何对图像的ROIs或tiles进行零样本分类
https://github.com/mahmoodlab/CONCH/blob/main/notebooks/zeroshot_classification_example_starter.ipynb
使用数据加载器(dataloaders)和提示集成(prompt ensembling)技术来提高分类的准确性。
https://github.com/mahmoodlab/CONCH/blob/main/notebooks/zeroshot_classification_example_ensemble.ipynb
3-3:使用MI-Zero模型对WSIs进行零样本分类
在进行分类之前,需要将WSIs分割成小块(tiling),然后使用CONCH视觉编码器模型将这些小块转换为嵌入。
https://github.com/mahmoodlab/CONCH/blob/main/notebooks/MI-zeroshot_classification_example_ensemble.ipynb
3-4:零样本跨模态检索(图像/文本)
跨模态检索涉及在不同类型数据(如图像和文本)之间建立联系,零样本跨模态检索意味着模型能够在没有特定模态对训练的情况下,检索出与给定模态相关的另一模态数据。
https://github.com/mahmoodlab/CONCH/blob/main/notebooks/zeroshot_retrieval_example.ipynb


















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









