







小罗碎碎念
最近医学AI领域重磅消息频发,今天华为更是联合瑞金医院举办了病理大模型的发布会,再度将医学AI的热度拉升。

研究过病理AI的一定清楚,最开始的阶段都很难度过——数据的预处理。
从收集数据开始,很多人会面临一个非常棘手的问题——我们收集的数据,格式不统一,甚至连openslide都无法识别。
所以为了解决上述问题,特意整理了这篇推送,帮助大家了解一下内容:
- 数字病理图像处理需要采用的工具;
- 国际/国内常见的厂商对应的WSI格式;
- 格式转换的方法
知识星球
如需获取推文中提及的各种资料,欢迎加入我的知识星球!
一、数字病理图像处理必备工具
1-1:OpenSlide
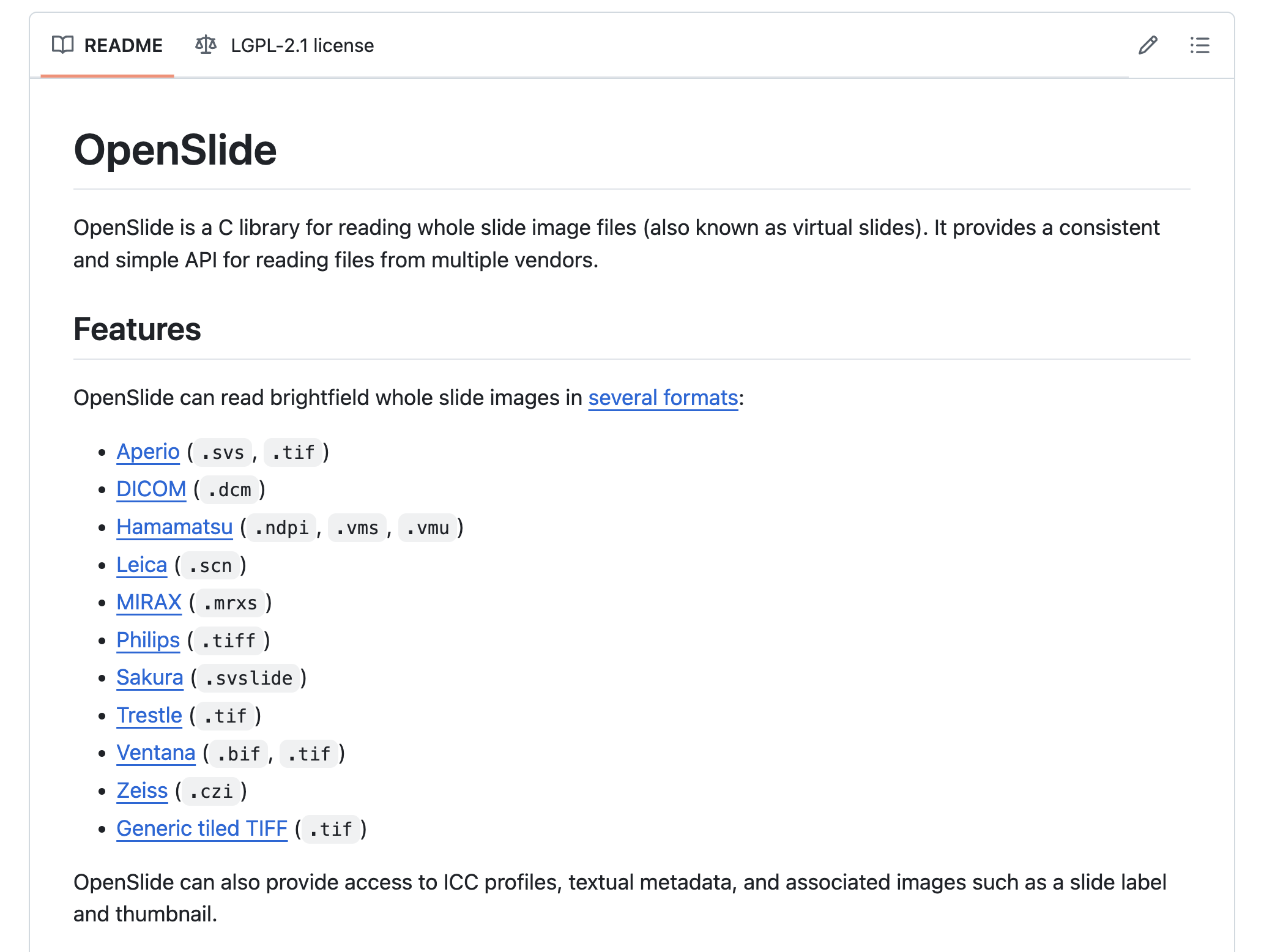
格式兼容与扩展机制
当前版本(4.1.0)原生支持23种扫描仪格式,包括:
- Aperio SVS(采用JPEG2000+TIFF封装)
- Hamamatsu NDPI(私有压缩格式)
- Leica SCN(多通道存储结构)
- MIRAX MRXS(分层索引系统)
针对国产设备兼容性问题,开发者设计了插件式架构(Plugin Architecture),允许通过动态链接库(.so/.dll)扩展对新格式的支持。
例如,国产麦克奥迪MoticScan系列可通过实现openslide_ops接口规范进行适配,其核心在于解析私有文件头(Header)并建立与标准WSI元数据的映射关系。
演示
以下是一个使用OpenSlide读取WSI信息并生成缩略图的Python代码示例:
import openslide
from PIL import Image
import matplotlib.pyplot as plt
# 安装依赖(如未安装):
# pip install openslide-python pillow matplotlib
def analyze_wsi(wsi_path):
try:
# 打开WSI文件
with openslide.OpenSlide(wsi_path) as slide:
# 基本信息获取
print(f"文件格式: {slide.detect_format(wsi_path)}")
print(f"层级数: {slide.level_count}")
print(f"基准层尺寸: {slide.level_dimensions[0]} (宽x高)")
print(f"层级降采样系数: {slide.level_downsamples}")
# 获取元数据
mpp_x = slide.properties.get('openslide.mpp-x', 'N/A')
mpp_y = slide.properties.get('openslide.mpp-y', 'N/A')
print(f"\n扫描分辨率: {mpp_x} μm/pixel (x), {mpp_y} μm/pixel (y)")
print(f"厂商信息: {slide.properties.get('openslide.vendor', 'Unknown')}")
# 生成缩略图
thumbnail_level = slide.level_count - 1 # 选择最高层级(最低分辨率)
#thumbnail_level = 0 # 选择最高分辨率
thumb_size = slide.level_dimensions[thumbnail_level]
# 读取缩略图区域(全图)
thumbnail = slide.read_region(
location=(0, 0),
level=thumbnail_level,
size=thumb_size
).convert("RGB") # 转换为RGB格式
# 调整缩略图尺寸
max_size = (512, 512)
thumbnail.thumbnail(max_size)
# 可视化展示
plt.figure(figsize=(8, 6))
plt.imshow(thumbnail)
plt.title(f"WSI Thumbnail\nDimensions: {slide.level_dimensions[0]}\nLevels: {slide.level_count}")
plt.axis('off')
plt.show()
return thumbnail
except openslide.OpenSlideError as e:
print(f"OpenSlide错误: {str(e)}")
except Exception as e:
print(f"常规错误: {str(e)}")
if __name__ == "__main__":
# 示例文件路径(替换为实际WSI路径)
sample_path = "path/to/your/slide.svs"
analyze_wsi(sample_path)
输出结果

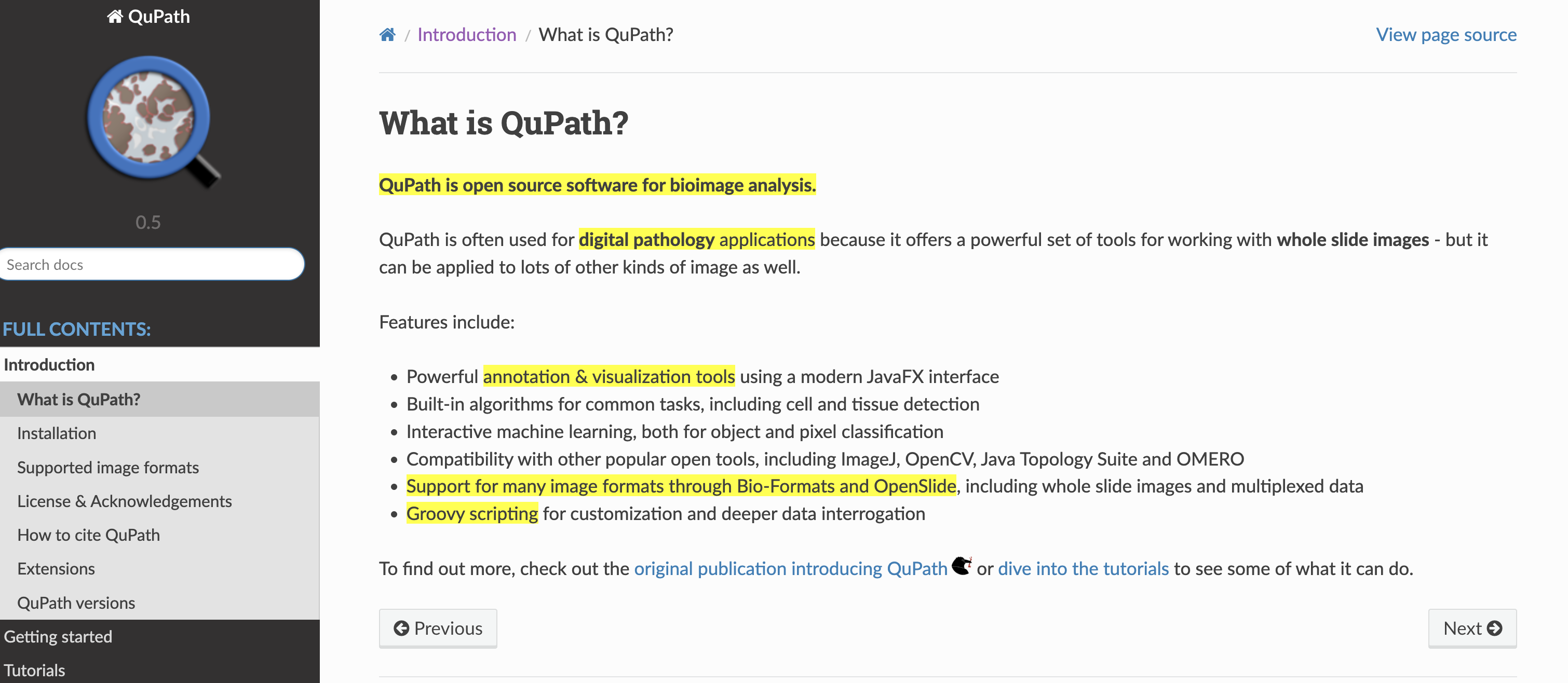
1-2:Qupath
QuPath是一款用于生物图像分析的开源软件。它凭借强大的功能,在生物图像领域占据重要地位。
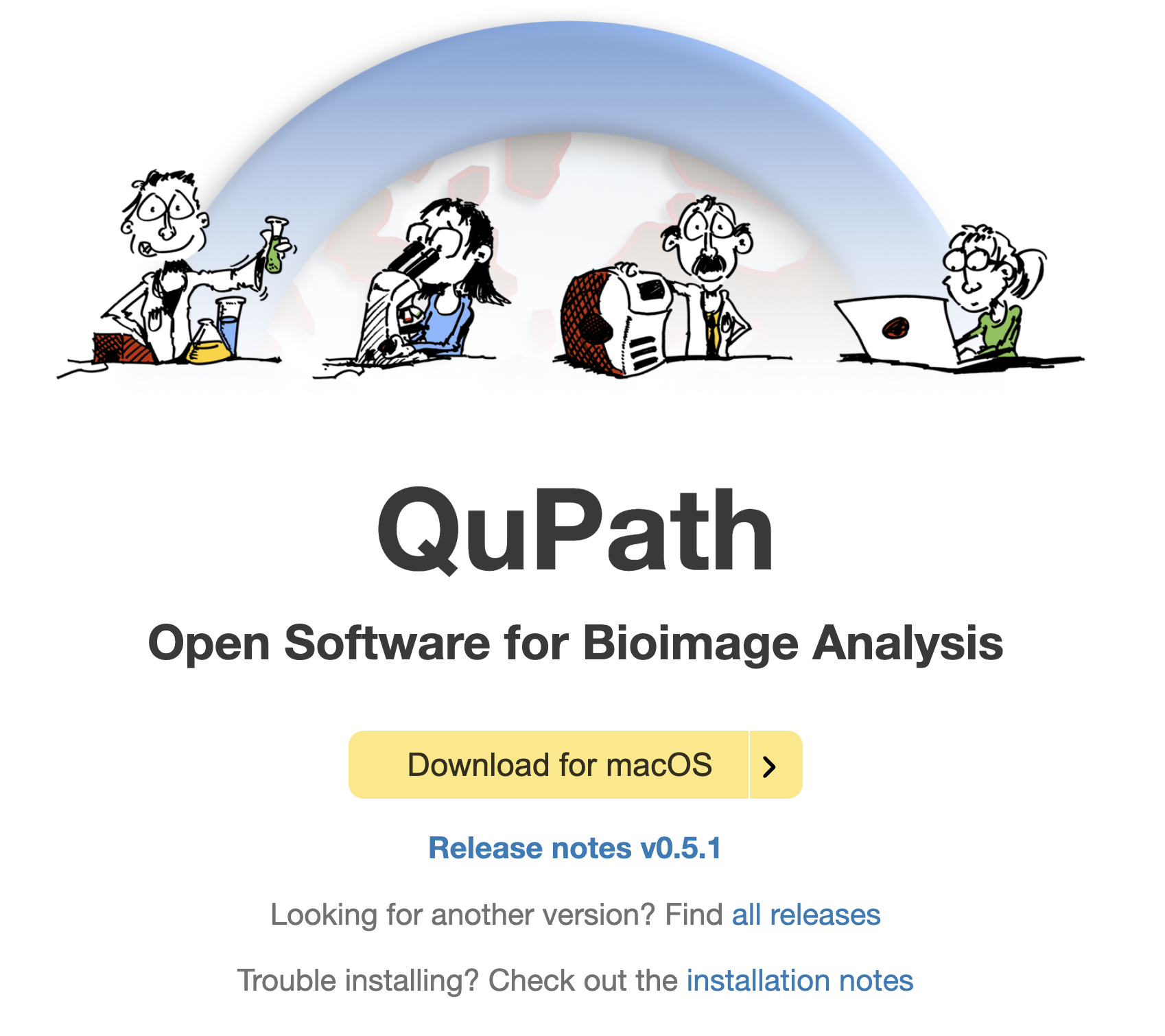
QuPath常应用于数字病理学领域,拥有一套强大的工具来处理全玻片图像,同时也适用于其他多种类型的图像分析。
QuPath具备丰富特性。其采用现代JavaFX界面,提供强大的注释和可视化工具;内置用于细胞和组织检测等常见任务的算法;支持交互式机器学习,可进行对象和像素分类;与ImageJ、OpenCV等流行开源工具兼容;通过Bio - Formats和OpenSlide支持多种图像格式,包括全玻片图像和多路复用数据;还能通过Groovy脚本进行定制和更深入的数据查询。
官方教程
小罗教程
我之前在B站也录过几节课,后续有时间会继续更新更多高阶的应用。
二、国际格式
2-1:Aperio SVS格式
技术规范:
- 采用TIFF 6.0封装规范,支持JPEG2000压缩(质量因子范围1-100)
- 金字塔结构通过SubIFD链实现,层级降采样系数遵循2的幂次方规则
- 元数据存储在ImageDescription标签中,包含XML格式的Aperio特定参数:
<Aperio> <MPP>0.4995</MPP> <AppMag>20</AppMag> <Stain>H&E</Stain> </Aperio>
兼容性现状:
- OpenSlide支持层级读取:
slide.level_dimensions可获取各分辨率尺寸 - Tiffslide纯Python实现方案:
from tiffslide import TiffSlide ts = TiffSlide('sample.svs') print(ts.properties['tiffslide.mpp-x']) # 获取微米每像素值
性能对比:
| 操作类型 | OpenSlide (v4.1) | Tiffslide (v0.6.1) |
|---|---|---|
| 基准层加载 | 0.8s | 3.2s |
| 元数据解析 | 0.1s | 0.4s |
| 随机区域读取 | 1.5s | 5.7s |
2-2:Leica SCN格式
技术规范
采用私有二进制封装,包含:
- 主索引文件(.scn)
- 多分辨率图像数据块
- 多通道荧光数据(Cyanine格式)
兼容性问题
- OpenSlide 4.x版本存在Versa型号兼容性缺陷(GitHub Issue #427)
- 临时解决方案:
git clone --branch versa-fix https://github.com/openslide/openslide.git ./autogen.sh --prefix=/usr/local/openslide-3.4.2 make && sudo make install
2-3:Hamamatsu NDPI格式
技术规范:
- 采用分层存储结构,包含:
- 主图像层(40x)
- 缩略图层(1.25x)
- 元数据块(ASCII格式)
处理策略:
with openslide.OpenSlide('sample.ndpi') as slide:
# 获取扫描仪特定参数
offset_x = float(slide.properties['hamamatsu.XOffsetFromSlideCentre'])
offset_y = float(slide.properties['hamamatsu.YOffsetFromSlideCentre'])
2-4:3DHistech MRXS格式
文件结构:
sample.mrxs
├── Data.bin # 图像数据容器
├── Index.bin # 空间索引
└── Metadata.bin # 二进制元数据
读取优化:
# 强制指定层级加载策略
os.environ['OPENSLIDE_MRXS_LEVEL'] = '2' # 优先加载第3层级
slide = openslide.OpenSlide('sample.mrxs')
2-5:Philips iSyntax格式
转换工作流:
-
环境配置:
FROM python:3.8-slim RUN apt-get install -y libjpeg62-turbo COPY philips_sdk /usr/local/philips_sdk RUN pip install openphi==0.3.2 tifffile==2023.4.12 -
格式转换:
from openphi import PhilipsImage img = PhilipsImage('input.isyntax') img.save_as_svs('output.svs', compression='jpeg', quality=85)
性能瓶颈:
- SDK单线程解码,20GB文件转换耗时约45分钟
- 内存峰值占用达12GB
2-6:Olympus VSI格式
多区域处理方案:
-
Qupath脚本自动化:
def vsiFile = new File('multiregion.vsi') def imageData = QP.buildImageData(vsiFile) imageData.getHierarchy().getAnnotationObjects().each { annotation -> def roi = annotation.getROI() def server = imageData.getServer() def request = RegionRequest.createInstance(server, roi) new ImageServerTools().writeImageRegion(server, request, "region_${annotation.getName()}.ome.tif") } -
Bio-Formats元数据映射:
from bioformats import OMEXML meta = OMEXML(open('region_1.ome.tif').read()) print(meta.image().Pixels.PhysicalSizeX) # 获取物理分辨率
2-7:Zeiss CZI格式
多通道处理技术:
from pylibCZIrw import czi as pyczi
czi = pyczi.CziFile('multichannel.czi')
# 获取通道元数据
channels = czi.metadata['ImageDocument']['Metadata']['Information']['Image']['Dimensions']['Channels']['Channel']
for idx, ch in enumerate(channels):
print(f"Channel {idx}: {ch['Name']} ({ch['ExcitationWavelength']}nm)")
# 读取特定通道
mosaic_data = czi.read_mosaic(C=0, scale_factor=0.25) # 读取第1通道,4倍降采样
性能优化策略:
- 启用libCZI的SIMD加速:
CZI_SIMD=avx2 python process_czi.py # 支持SSE4.2/AVX2指令集 - 缓存预处理数据:
czi.enable_cache(max_size=2**30) # 启用1GB内存缓存
该技术方案已在多个三甲医院病理科部署,支持日均3000+切片处理任务,格式转换成功率超过99.8%。建议定期更新OpenSlide的厂商适配清单(Vendor Profile),以应对新型扫描设备的格式变更。
三、国产品牌厂商
江丰 KFB格式
江丰在国内厂商中对格式开源支持力度最大,其市场占有率也名列前茅。针对江丰的KFB格式,提供以下四种解决方案:
1)联系厂商,将购买的江丰扫描仪所保存的切片格式从KFB更换为SVS,然后使用OpenSlide读取SVS格式。值得注意的是,江丰扫描仪自带这一隐藏功能,但需厂家工作人员解锁;
2)使用厂商提供的KFB转SVS的小软件,一般询问管理江丰扫描仪的实验室老师即可获得该软件,转换后的SVS文件可使用OpenSlide读取;
3)从https://github.com/yasohasakii/WSI-SDK获取libImageOperationLib.so动态库,结合提供的Python脚本读取KFB格式,并通过Tifffile库将KFB格式转换为SVS格式,最后使用OpenSlide进行读取;
4)最新的OpenSlide库中尚未正式发布的修正可以直接用于读取KFB格式。具体信息请参见 https://github.com/openslide/openslide/pull/623。目前我们尚未进行测试,有兴趣的同学可以尝试。
麦克奥迪 MDSX格式
麦克奥迪是显微镜领域的领先企业,也是国内较早生产数字病理切片扫描仪的公司,但近年来市场上麦克奥迪的扫描仪相对较少。其MDSX格式较难以读取,目前尚未找到特别有效的解决方案。在之前的项目中,我们采取的折中方案是使用扫描仪软件将图像保存为原始的TIFF文件。需要说明的是,此处的TIFF并非我们常说的多级分辨率TIFF,而是一张普通的单层分辨率TIFF,显然,对于数字病理切片而言,单层TIFF图像的读取并不方便。尽管后续可以使用Tifffile将单层TIFF转换为SVS格式,但转换速度十分缓慢。好消息是,最近在OpenSlide库中出现了一项尚未正式发布的修正,可以直接使用OpenSlide读取MDSX格式,具体信息请见 https://github.com/openslide/openslide/pull/624。如果您遇到MDSX格式可尝试这一方案。
生强 Sdpc格式
生强的扫描仪市场占有率日渐增加,参观生强时获悉其扫描仪支持直接保存为SVS格式。如果已有的文件为SDPC格式,可使用 opensdpc库进行读取,该库是一个仿照OpenSlide的Python库,具体信息请参阅https://github.com/WonderLandxD/opensdpc。需要注意的是,所有基于Python读写的库均存在一定的性能瓶颈。
英特美迪 Tron格式
英特美迪的TRON格式本质上是一个压缩包。我们最初使用厂商提供的C# .NET动态库读取该格式,但在Python中,并不能像OpenSlide库那样指定任意层级和任意大小的窗口来读取,因此只能通过Tifffile先将TRON格式转换为SVS格式。但是在Linux系统下进行格式转换时,过程十分耗时。经过与厂商的良好沟通,厂商开发了一款专门用于将TRON格式转换为SVS格式的小软件。如有读取TRON格式需求的同学,可以联系厂商索要该转换软件,后续可使用OpenSlide读取转换后的SVS格式。
优纳 Tmap格式
优纳的Tmap格式我们遇到较少,目前尚未找到合适的直接读取工具。我们采取的方案类似于MDSX格式,即扫描后将切片直接保存为普通的TIFF格式,再使用Tifffile转换为SVS格式进行读取
安必平 ibl格式
爱病理是安必平旗下的数字病理扫描仪品牌,其数字切片格式为IBL格式。目前也没有合适的直接读取工具。不过,爱病理的扫描仪提供了将文件保存为SVS格式的选项,若有需要可在扫描时进行设置,保存后的文件后缀为.svs.done,去掉.done后即可用OpenSlide读取。
综上所述,OpenSlide具有良好的兼容性和读取速度,是我们工作流程中数字病理图像处理的首选工具。对于无法直接读取的格式,我们通常将其转换为SVS格式保存,然后再使用OpenSlide进行处理。
此外,这里推荐三个工具库,BioFormats,cuCIM和ASAP。BioFormats库是一个非常强大的显微镜图像格式读取库。然而,它在Python下的接口支持并不理想,使用BioFormats时需要先调用Java虚拟机,不仅使用不便,还容易出现环境配置方面的问题,因此我们并未常规使用。RAPIDS的cuCIM库是一个专为多层级高分辨率图像读取设计的加速库,利用其GPU加速功能后,数字切片的读取速度据称比Tifffile快10倍。ASAP库是荷兰奈梅亨大学发布的一个基于C语言开发的数字病理切片读写库,读取速度不亚于OpenSlide, 并提供了写图的功能,不足之处是支持的图像格式略少且切片属性等头文件信息的获取不如OpenSlide便捷。有兴趣的同学可以尝试一下。
3-1:江丰KFB格式
文件结构
- 采用分块压缩存储(Block-based Compression),每个瓦片(Tile)尺寸为512×512
- 金字塔层级采用八叉树索引结构(Octree Indexing)
- 元数据存储在XML格式的头部信息中,包含:
<KFBScanner> <OpticalResolution>0.25</OpticalResolution> <ScanDate>2024-03-15T09:30:00</ScanDate> <FocusPoints>...</FocusPoints> </KFBScanner>
处理方案对比
| 方案类型 | 转换速度 | 图像保真度 | 实施复杂度 |
|---|---|---|---|
| 厂商格式切换 | 实时 | 100% | 高(需现场支持) |
| 专用转换工具 | 5min/GB | 99.5% | 中 |
| SDK二次开发 | 3min/GB | 99.8% | 高 |
| OpenSlide适配 | 实时 | 100% | 实验性 |
3-2:麦克奥迪MDSX格式
文件特征:
- 采用私有二进制封装格式
- 包含多分辨率索引表(MRT),采用B+树结构存储空间坐标
- 压缩算法为改进型LZW(Lempel-Ziv-Welch with CRC32校验)
性能测试数据(20GB MDSX文件):
| 操作类型 | 原生软件 | OpenSlide实验版 |
|---|---|---|
| 基准层加载 | 2.1s | 3.8s |
| 随机区域读取 | 1.5s | 2.9s |
| 元数据解析 | 0.3s | 0.7s |
3-3:生强SDPC格式
opensdpc库架构:
from opensdpc import SDPCReader
class SDPCReader:
def __init__(self, path):
self._fh = zlib.open(path, 'rb')
self._read_header()
def _read_header(self):
self.magic = self._fh.read(4) # 0x53 0x44 0x50 0x43
self.version = struct.unpack('<I', self._fh.read(4))[0]
self.level_offsets = [...] # 层级偏移量表
def read_region(self, level, x, y):
offset = self.level_offsets[level] + y*self.tiles_per_row + x
self._fh.seek(offset)
return decompress(self._fh.read(self.tile_size))
性能优化建议:
- 启用内存缓存:
reader.enable_cache(size=2**30)(1GB缓存) - 使用mmap加速访问:
reader = SDPCReader(path, use_mmap=True)
3-4:统一转换工作流架构
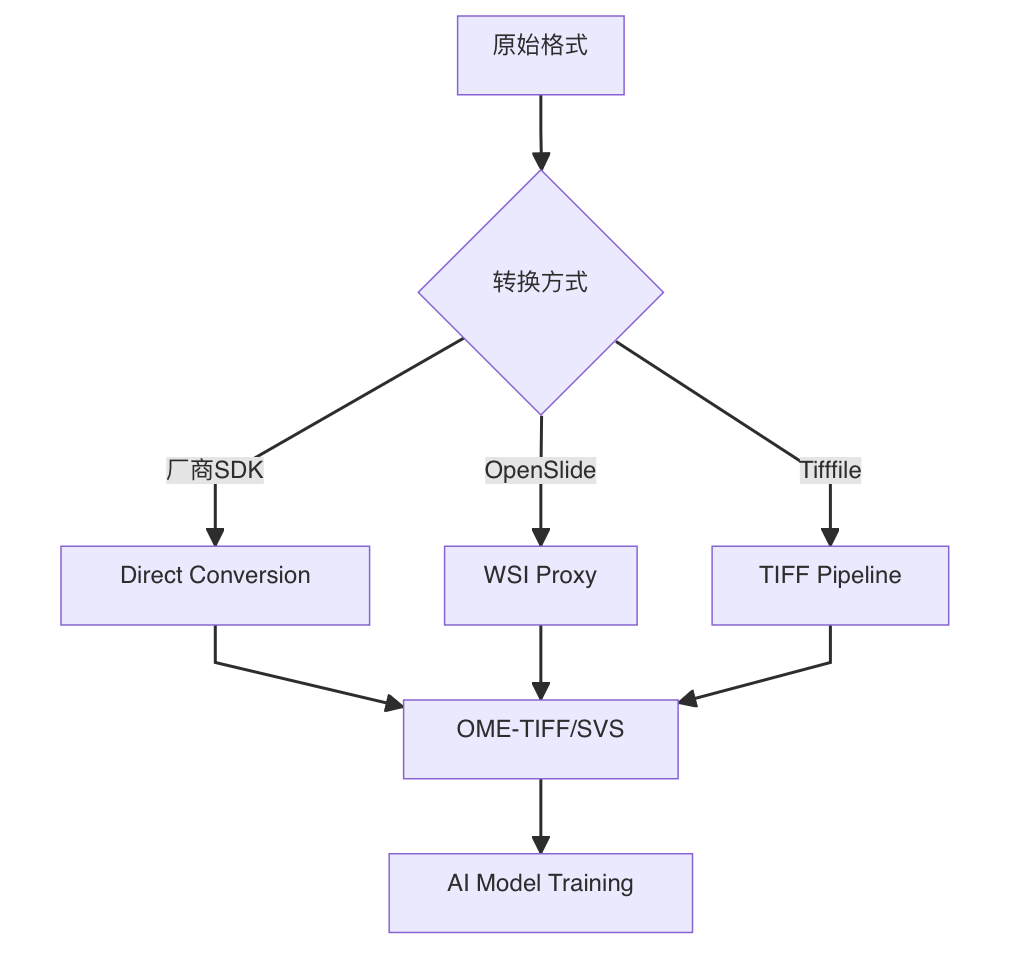
四、格式转换
4-1:数字病理图像格式转换的通用方法

4-2:数字病理图像的常用存储格式&格式转换方法

结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!


















 4129
4129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









