







目标检测入门知识
目录
目标检测任务与描述
1.目标检测算法分类
-
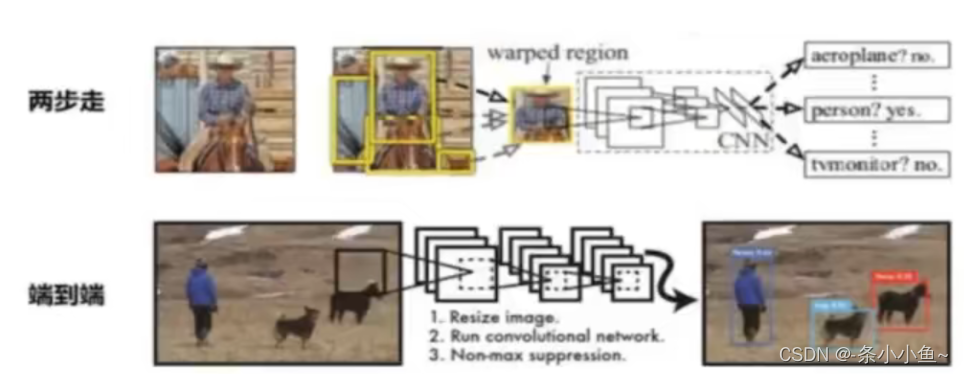
两步走的目标检测
-
先找出候选的一些区域
-
2.对区域进行调整分类
-
端到端的目标检测
-
采用一个 网络一步到位
-
输入图片,输出有哪些物体,物体在哪些位置
-
2.目标检测的任务
-
输入:图片
-
输出:物体类别,物体的位置坐标
-
(xmin,ymin),(xmax,ymax):物体的左上角、右下角坐标
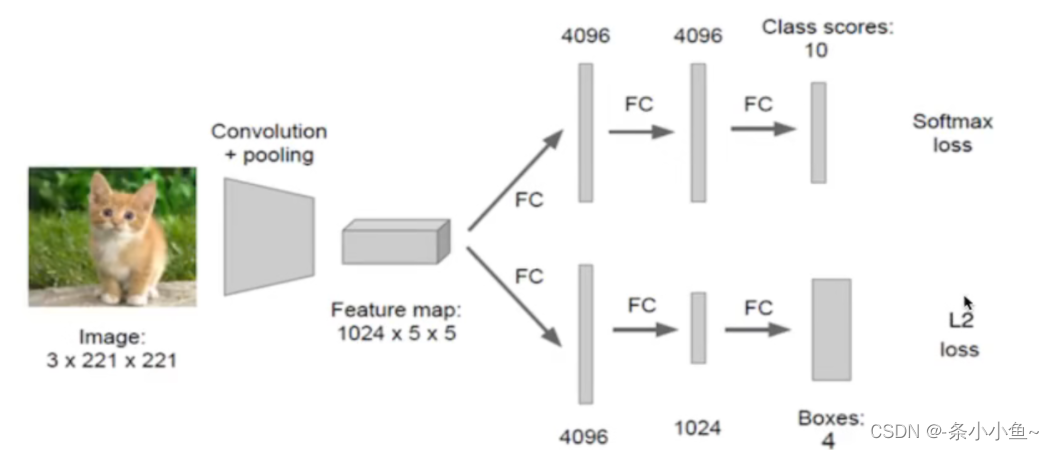
3.目标定位的简单实现思路
-
衡量网络的损失
- 分类的概率可以使用交叉熵损失衡量
- 位置信息具体的数值,可使用MSE均分误差损失(L2损失)
4.两种Bounding Box名称
-
Ground-truth bounding box:GT bbox 图片真实目标位置(标记结果)
-
Predicted bounding box:预测的时候标记
-
分类与定位:图片中只有一个物体需要检测
-
目标检测:图片中有多个物体需要检测
R-CNN
1.目标检测Overfeat模型
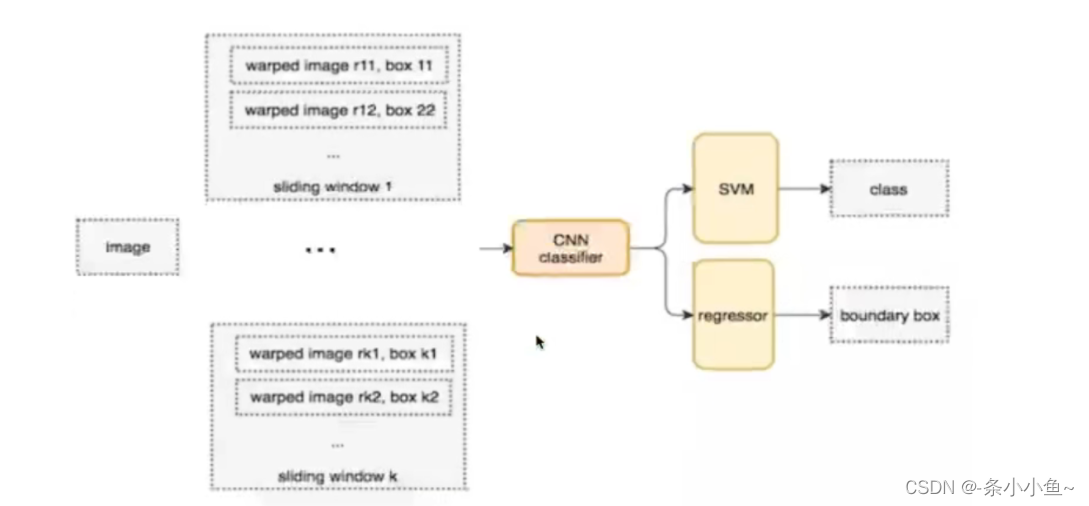
1.1滑动窗口
-
目标检测的暴利方法是从左到右,从上到下滑动窗口,利用分类识别目标。
-
为了在不同观察距离处检测不同的目标类型,我们使用不同大小和宽高比的窗口。如下所示:
-

注:这样就变成每张图片输出类别以及位置,变成分类问题。
但是滑动窗口需要初始设定一个固定大小的窗口,这就遇到一个问题,有些物体适应的框不一样
-
所以需要提前设定K个窗口,每个窗口滑动提取M个,总共K x M个图片,通常直接将图像变形转换成固定大小的图像,变形图像块被输入CNN分类器中,提取特征后,我们使用一些分类器识别类别和该边界框的另一个线性回归器。
Overfeat模型总结:这种方法类似一种暴利穷举的方式,会消耗大量的计算力量,并且由于窗口大小问题可能造成效果不准确。所以下面提供另外一种解决目标检测问题的思路——R-CNN
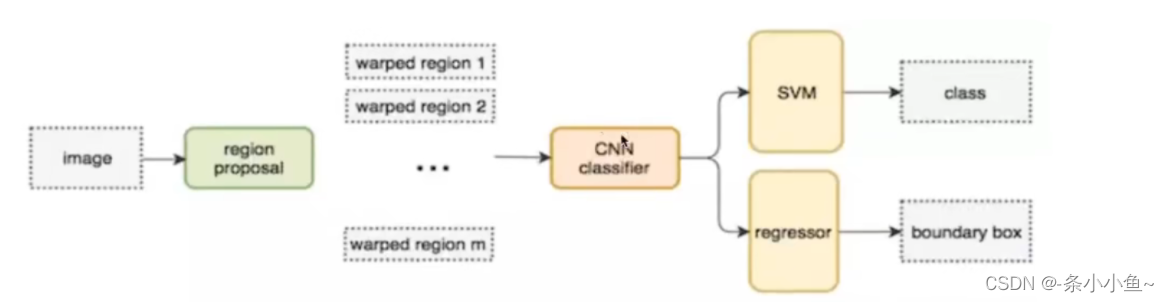
2. 目标检测R-CNN模型
-
不使用暴利破解的方法,而是使用候选区域方法(region proposal method),创建目标检测的区域,这改变了图像领域实现物体检测的模型思路(以R-CNN为基点,后续的SPPNet、Fast R-CNN 、Faster R-CNN模型都是照着这个物体检测思路)
-
R-CNN步骤(以AlexNet网络为基准)
-
找出图片可能存在目标的候选区域region proposal(默认对一张图片找出2000个候选区域)
-
将候选区域调整,为了适应AlexNet网络的输入图像的大小227 x 227,通过CNN对候选区域提取特征向量,2000个建议框的CNN特征组合成网络AlexNet最终输出:2000 x 4096维矩阵
-
将2000 x 4096维特征经过SVM分类器(20种分类,SVM是二分类器,则有20个SVM, 以前不用神经网络分类器,通常用SVM分类器),获得2000 x 20种类别矩阵
-
分别对2000 x 20维矩阵中进行非极大值抑制(NMS:non-maximum suppression)剔除重叠建议框,得到与目标物体评分最高的一些建议框
-
修正bbox,对bbox做回归微调
-
2.1 候选区域由Region of interest(ROI)得出
Selective Search在一张图片上提取出来约2000个候选区域,需要注意的事这些候选区域的长宽不固定。而使用CNN(这里指的是AlexNet网络)提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
2.2 CNN网络提取特征
在候选区域(调整过的适合AlexNet输入的大小的候选区:227 x 227)的基础上提取出更高级、更抽象的特征,这些高级特征是作为下一步的分类器、回归的输入数据
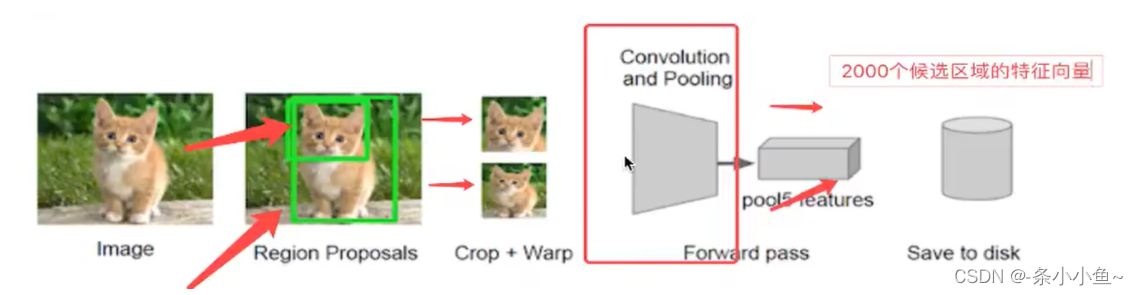
提取的这些特征将会保存在磁盘当中(这些提取的特征才是真正的要训练的数据)
2.3 特征向量的训练分类器SVM
-
假设一张图片的2000个候选区域,那么提取出来的就是2000 x 4096这样的特征向量(R-CNN中默认CNN层输出4096特征向量)
-
R-CNN选用SVM进行二分类。假设检测20个类别,那么就会提供20个不同类别的SVM分类器,每个分类器都会对2000个候选区域的特征向量分别判断一次,这样得出[2000,20]的得分矩阵,如下图所示

2.4 非极大抑制(NMS)
-
目的
-
筛选候选区域,目标是一个物体只保留最优的框,来抑制那些冗余的框
-
-
迭代过程
-
对于所有的2000个候选区域得分进行概率筛选,只保留概率大于0.5的候选区域
-
剩余的候选框
-
假设图片的真实个数为2(N),筛选之后候选框为5(P),计算N中每个物体位置与所有P的交并比IOU计算,得到P中候选框IOU最高的一个。如下图,A、C候选框对应左边的车辆,B、D、E对应右边的车辆。粉色的框代表GT(ground truth:物体的真实标记位置),则左边A候选框跟GT交并比的分数最高为0.8,右边同理B最高为0.9。
-
-
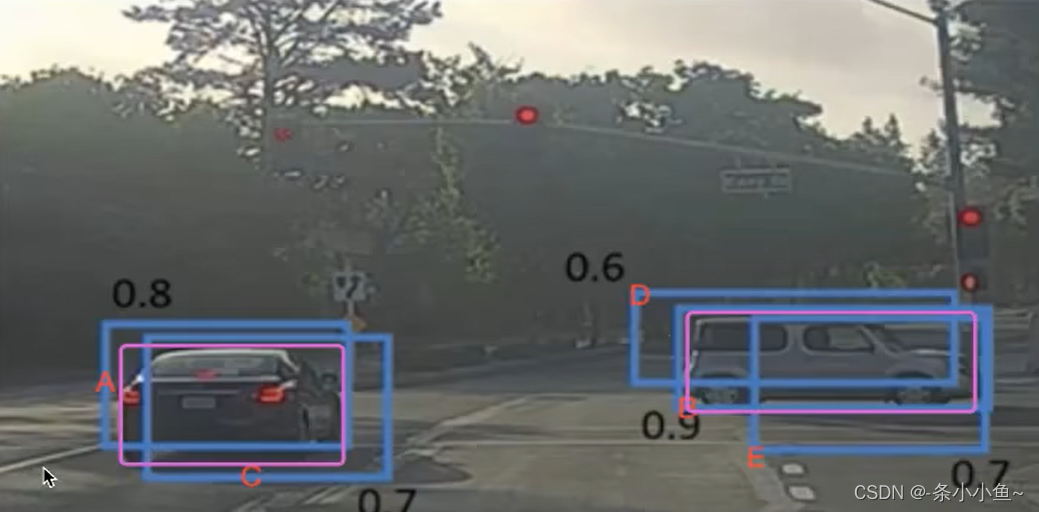
假设现在滑动窗口有:A、B、C、D、E 5个候选框
第一轮:对于右边车辆,假设B的得分最高(与GT的IOU为0.8),删除与B的IOU > 0.5候选框(D与B的IOU为0.6,E与B 的IOU为0.7),则删除D、E,B作为一个预测结果
第二轮:对于左边车辆,A的得分最高,则C与A计算IOU,结果>0.5,删除C,A作为一个结果
最终在这5个中检测除了两个目标A和B,则每一个GT都有一个候选框预测
SS(Selective Search)算法得到的物体位置已经固定了,但是我们筛选出的位置不一定就是特别准确,需要对A和B进行最后的修正
2.5 修正候选框
通过非极大值抑制筛选出来的候选框不一定非常准确怎么办?R-CNN提供了一个方法,建立一个bbox regressor
-
回归用于修正筛选后的候选区域,使之回归于ground-truth,默认认为这两个框是线性关系,应为在最后筛选出来的候选区域和ground-truth很接近了
修正过程(线性回归)

3. 评价指标
3.1 IOU交并比

-
IOU(交并比)
-
两个区域的重叠程度overlap:候选区域和标定区域的IOU值
-
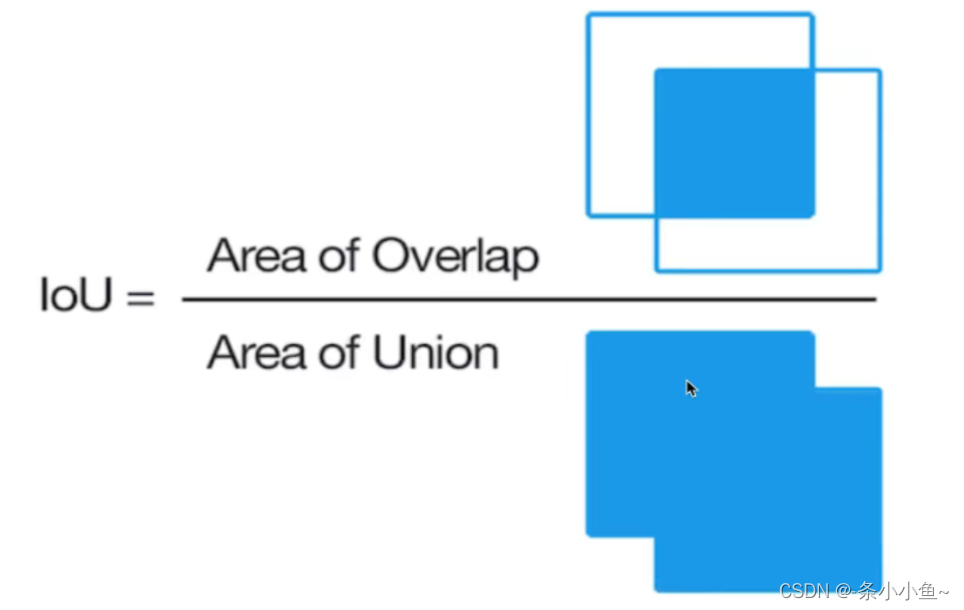
相交的值比较小,NMS过滤条件给的不严格
3.2 平均精确率(mean average precision)map
目标检测中衡量识别精度的指标
多个类别目标检测中,每个类别都可以根据recall(召回率)和percision(准确率)绘制一条曲线。AP就是该曲线下的面积,mAP意思是对每一类的AP再求平均















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









