







- 国庆出去浪了几天,继续更新面试问题总结,加油,冲!

面试中遇到的问题及解答
14.关于Dropout的内容
1.什么是dropout及其具体工作流程?
Dropout指暂时丢弃一部分神经元及其连接。
具体工作流程:在前向传播的时候,让某个神经元的激活值以一定的概率停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。把输入x通过修改后的网络前向传播,把得到的损失结果进行梯度下降法等等更新对应的参数w和b。

2.数学原理

上图中,wi表示权重系数,其中r1,r2,r3是0~1之间的变量,伯努利分布指的就是以p的概率为1,以1-p的概率为0。
上图就是dropout的数学原理,在原本z = w×y+b的基础上加一个随机生成的r1变量。使得z = w×r×y+b。
3.dropout的训练与预测
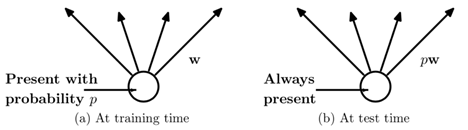
在训练的时候,因为r是符合伯努利分布的,所以就是以p(p就是r)的概率保存这个神经元,以1-p的概率丢弃这个神经元,所以这时候每个神经元的期望值是pwx(p表示概率,w表示权重系数,x表示输入)。
在训练的时候,每个神经元是以p的概率保存,1-p的概率丢弃,而在测试预测的时候,是计算每一个神经元的,但在其权重前乘上一个p,相当于把权重做了一个缩放,变成之前的p倍。
4.为什么dropout可以解决过拟合问题?
a.dropout减少神经元之间的联合依赖性,使得每个神经元都被逼着独当一面;
b.取均值的原因:假设用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,含有dropout的模型采用5个结果均值的方式去决定最终结果,综合起来取均值的策略可有效防止过拟合的问题;
c.dropout类似生物进化中的角色,因为每个基因片段都要与来自另一个随机个体的基因片段协同工作。
5.dropout的缺点?
a.算法过拟合可以使用dropout,没有过拟合的时候一般不用dropout;
b.使用dropout后,代价函数不再被明确定义,导致每次迭代损失函数值可能不会总体上单调递减;
c.有dropout网络的训练时间是没有dropout网络的2~3倍。
6.CNN中能否用dropout,为什么?
CNN中可以用dropout,因为dropout不仅可以用在隐藏层,也可以用在输入层,只不过在输入层中一般设置0.8及以上(表示保存80%的数据),隐藏层一般输入是0.5。(但我看网上的经验贴中有人实际做过实验,只有在全连接的时候用dropout,在卷积之间应该用 batch normalization)
15.anchor聚类的具体实现与原理
YOLOv2中使用了5个anchor,v3和v4中使用了9个,这些个数和大小是作者基于他训练集的物体边框数据集上通过Kmeans聚类得到的,个数是作者通过实验得到的经验值,关于大小,各个数据集适用的anchor boxes大小不同,所以我们在训练自己的数据集时,也要通过Kmeans聚类生成自己的anchor boxes大小。
关于Kmeans聚类,如果用欧式距离来度量的话,显示是不合理的,因为大的预测框会产生大的欧式距离,小的预测框会产生小的欧氏距离,但我们需要大小框产生同样的效果影响,所以使用IOU,IOU是和box的大小无关的,公式如下:
d(box, centroid) = 1 - IOU(box, centroid)
(其中box表示某个类别的ground truth,centroid表示聚类中心框)
16.正则化,L1正则与L2正则,L1、L2正则化的作用和区别是什么?分别服从什么分布?
正则化通过避免训练完美拟合数据样本的系数而有助于算法的泛化,解决过拟合问题。
L1、L2正则化的作用是解决过拟合问题,提高算法的泛化。之所以能解决过拟合原因:模型复杂是因为它需要兼顾各个测试数据点,就会导致函数值变化很剧烈,处于一种动荡的状态,这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大,而加入正则能抑制系数过大的问题。
区别:L1正则化公式是直接在原来的损失函数基础上加上权重参数的绝对值;L2正则化公式是直接在原来的损失函数基础上加上权重参数的平方和。/ L1正则化比L2正则化更易于得到稀疏解。
L1是拉普拉斯分布,L2是高斯分布。

17.感受野
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。
卷积神经网络中,越深层的神经元看到的输入区域越大,即越深层的神经元的感受野越大。
所以,感受野是个相对概念,某层feature map上的元素看到前面不同层上的区域范围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。
18.YOLOv3和v2、v1的改进
YOLO系列损失函数理解:https://blog.csdn.net/weixin_43384257/article/details/100986249
YOLOv3和YOLOv2的主要区别:
①loss不同:作者在YOLOv3中替换了原来YOLOv2中的softmax loss 变成logistic loss,而且每个ground truth只匹配一个先验框。
②anchor bbox的数量不同:YOLOv2中作者用了5个anchor,是一个折衷的选择,所以在YOLOv3中用了9个anchor,提高了IOU。
③detection的策略不同:YOLOv2中只有一个detection,YOLOv3中一下变成了3个,分别是一个下采样的,feature map为13×13,还有2个上采样的eltwise sum,feature map为26×26、52×52,也就是说在YOLOv3中的416×416版本已经用到了52×52的feature map,而YOLOv2把多尺度考虑到训练的data采样上,最后也只是用到了13×13的feature map,这应该是对小目标影响最大的地方。
④backbone不同:这和上一点是有关系的,YOLOv2的darknet-19变成了YOLOv3的darknet-53,为啥呢?就是需要上采样啊,卷积层的数量自然就多了,另外作者还是用了一连串的3×3、1×1卷积,3×3的卷积来增加channel,而1×1的卷积在于压缩3×3卷积后的特征表示,这波操作很具有实用性,一增一减,效果很棒。
smoothL1 loss的好处
参考博客https://blog.csdn.net/qq_45445740/article/details/115962430中
的2.4 CIoU-loss小节。

Smooth L1 Loss结合了L2 Loss收敛更快,且在0点有导数,便于收敛的好处,也结合了L1 Loss的好处,在0左右侧都是直线,意味着不管对于什么样的输入都有着稳定的梯度,下降就很稳,不会出现梯度爆炸和梯度消失的问题。
YOLO里面是向上取整还是向下取整
我记得代码里面在卷积层公式直接使用了/号,去掉了余数,向下取整。而pool层中,使用了ceil函数,向上取整。
19.关于Batch Normalization(批归一化,BN)
1.BN层的主要思想
BN是对每一个神经元的响应进行标准化,而不是对某一层的输出进行标准化,BN层一般在神经网络线性计算之后,激活函数之前进行BN操作。
在训练阶段:比如batch size为32,表示每次训练的时候喂进去32张图片,某层的某个神经元会输出32个响应值,对这32个响应值减去均值除以标准差,将其变成以0为均值,标准差为1的分布,再做归一化,把归一化后的响应值乘上γ再加上β,即yi = γxi+β,每个神经元都训练一组γ、β。
在测试阶段:测试阶段均值、方差、γ、β都用训练阶段全局求出的参数,BN层相当于做线性变换。
这么做使得损失函数能发生较大的变化,从而使得梯度变大,避免了梯度消失的问题,同时梯度变大能够加快模型的收敛速度,提高训练的速度。
2.BN层的作用
因为在神经网络的训练过程中,若每一层的输入都保持相同的分布,随着网络层数的加深,训练会变得困难,则BN层的作用是加快收敛、改善梯度,因为很多的激活函数比如说sigmoid激活函数,在0附近是非饱和区,如果输入太大或者太小的话,就会进去饱和区,就意味着梯度消失难以训练。(训练和测试时的BN层不一样)
3.结合YOLO问了BN
作者在YOLOv2中每一个卷积之后增加了BN层,提高了网络训练的速度,加快了收敛。
4.BN的公式,BN是怎么更新的

如何更新:见上面BN层的主要思想的训练和测试阶段,总的来说就是通过前面三步标准化工序然后得出两个参数γ、β,测试阶段用来验证可以不断调整参数。
5.为什么加了BN之后,就不用再使用dropout?
因为加了BN之后,就不需要用dropout了,甚至那个偏置项也可也不需要了,因为BN已经强行减去了均值,均值为0了,且期望为0。
6.Pytorch中BN层在训练和测试中有什么不同,怎么实现的?
https://blog.csdn.net/huangjiahao0711/article/details/110138955
7.用代码实现BN层
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换
20.对比SSD,为何YOLOv3小物体的检测效果这么好?
不仅仅因为YOLO V3引入FPN结构,同时它的检测层由三级feature layers融合;而SSD的六个特征金字塔层全部来自于FCN的最后一层,其实也就是一级特征再做细化,然而做的再多也只能补充SSD最后一层信息的不完整,却不能扩充到总的特征容量;很明显一级feature map的特征容量肯定要弱于三级,尤其是浅层包含的大量小物体特征。
YOLO是怎么克服小目标检测缺陷的?(YOLO做小目标检测的思考)
通过多尺度特征融合,低层的特征语义信息比较少,但是目标位置信息准确;高层的特征语义信息比较丰富,但是目标位置信息比较粗略。
YOLOv2网络结构中有一个特殊的转换层(Passthrough Layer),假设最后提取的特征图的大小是13×13,转换层的作用就是将前面的26×26的特征图和本层的13×13的特征图进行堆积(扩充特征维数据量),而后进行融合,再用融合后的特征图进行检测,这么做是为了加强算法对小目标检测的精确度。为达更好效果,YOLOv3将这一思想进行了加强和改进。
YOLO v3采用(类似FPN)上采样(Upsample)和融合做法,融合了3个尺度(13×13、26×26和52×52,13×13直接输出,13×13和26×26融合,26×26和52×52融合),在多个尺度的融合特征图上分别独立做检测,最终对于小目标的检测效果提升明显。
深度学习中检测小目标常用的方法?
①简单粗暴又可靠的Data Augmentation:有时候小目标检测之难其中也有数据集中小样本相对于大样本来说数量很少的因素;比如在同样一张图片里面,用分割的Mask抠出小目标图片再使用复制粘贴的方法(当然,也加上了一些旋转和缩放,另外要注意不要遮挡到别的目标)
②特征融合的FPN:就相当于YOLO中采用的特征融合。
③增加负责小目标检测的Anchor,来让训练时对小目标的学习更加充分。
21.如何解决目标检测两个物体重叠问题
非极大值抑制(Non-Maximum Suppression)
IoU:intersection-over-union,即两个边界框的交集部分除以它们的并集。
非极大值抑制的流程如下:
①根据置信度得分进行排序
②选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
③计算所有边界框的面积
④计算置信度最高的边界框与其它候选框的IoU。
⑤删除IoU大于阈值的边界框
⑥重复上述过程,直至边界框列表为空
所以一般具体解决办法就是减小 IoU threshold (IoU 阈值)
22.YOLOv3中416x416的输入有多少个anchor,为什么要sigmoid?
9个anchor,sigmoid的目的是让中心点落在grid cell中,可以防止bounding box的野蛮生长。
23.1×1卷积的作用
①实现信息的跨通道交互和整合;
②对卷积核通道数进行降维和升维,减小参数量。
















 1095
1095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











