







利用已经训练好的模型,给它提供输入,即该模型已经能对外进行应用
在github中可进行相关搜索
如:pytorch,再选择星数较多的,进行模仿
我们下载一张dog图片
在test.py中尝试调用dog.png
在同一层级,故需要一点,再根据其路径补充
import torch
import torchvision
from PIL import Image
from torch import nn
img_path = './imgs/dog.png'
image = Image.open(img_path)
print(image)
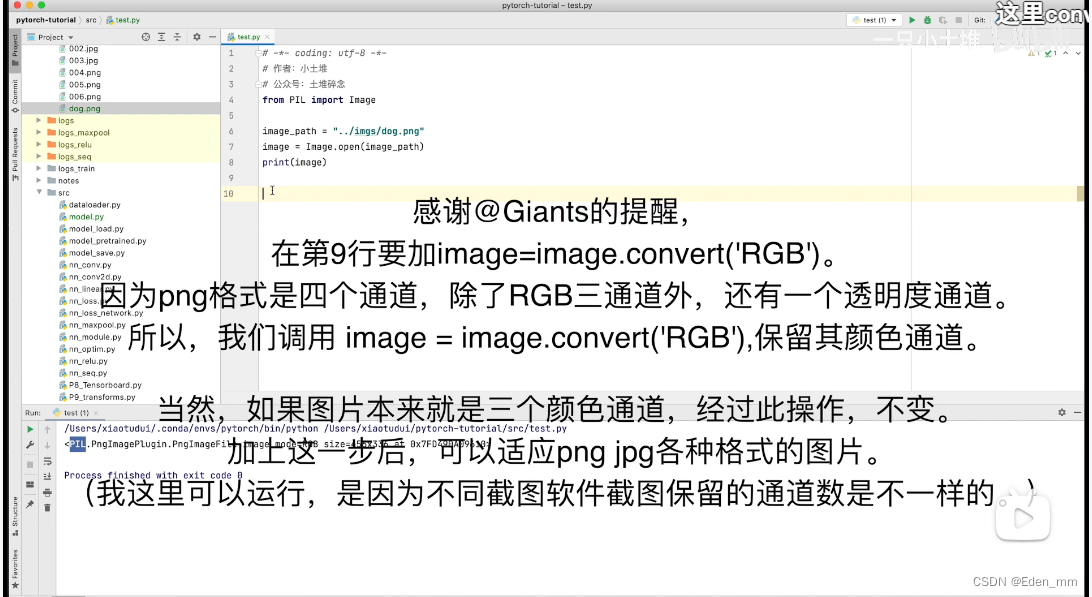
# png图片是4色通道,除RGB外,还有个透明通道,应调用image = image.convert(’RGB‘)进行保留,
# 若原图片本身仅RGB,则并不会改变。加上此步骤可适应各类格式图片。(由于截图软件原因,可能png图片也仅仅只有三通道)
image =image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
# 模型加载,因为我们是第一种模型保存方法,故采用第一种加载方法
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Lixinyu(nn.Module):
def __init__(self):
super(Lixinyu, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("lixinyu_epoch9.pth", map_location=torch.device("cuda"))
print(model)
image = torch.reshape(image, [1, 3, 32, 32])
image = image.to(device)
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))

















 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











