







调试处理
需要处理的参数:
| 参数 | 重要程度 |
|---|---|
| 学习率 α | ★★★★ |
| Momentum(动量梯度下降法)参数 β = 0.9 | ★★★ |
| 隐藏单元数量 | ★★★ |
| mini-batch size | ★★★ |
| 网络层数 | ★★ |
| 学习衰减率 | ★★ |
| Adam 优化算法的 β1 = 0.9,β2 = 0.999,ε =1e-8 | ★ |
-
在深度学习领域,常采用在超参数组成的矩阵中,随机选点进行参数搜索(试验了更多的不同的超参数值)
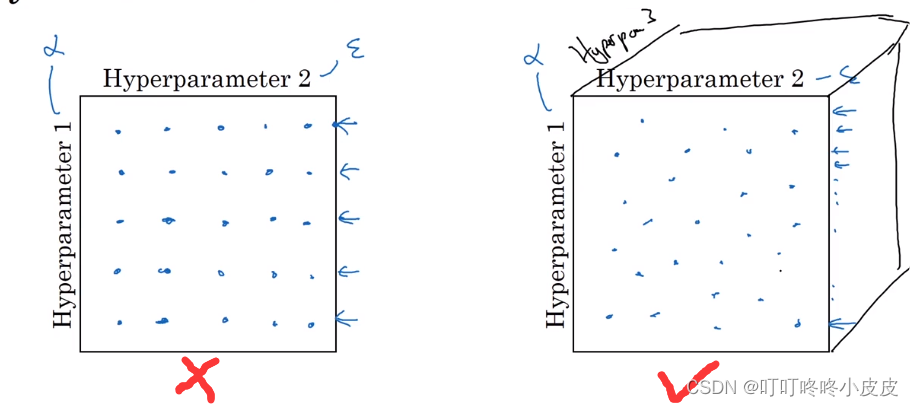
-
由粗糙到精细的策略,从最初的范围筛选,然后集中到可能更优的小区域进行更密集的搜索。
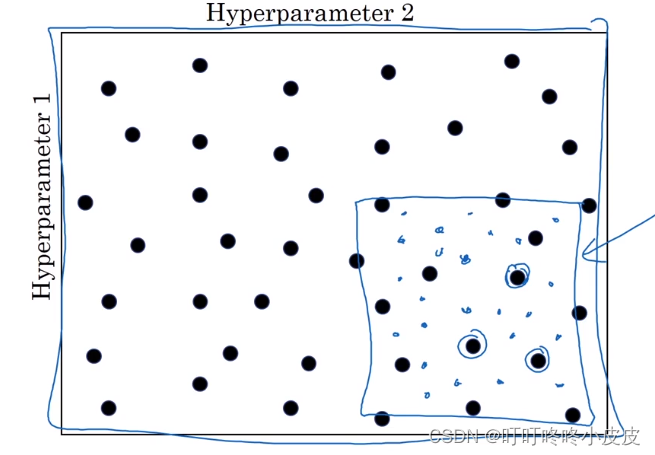
为超参数选择合适范围
- 在对数坐标上取值,会更加合理。否则像下面0.0001~1的范围内,就会出现90%的取值出现在0.1 ~ 1 之间,不能合理在 0…0001 ~ 0.1之间取值
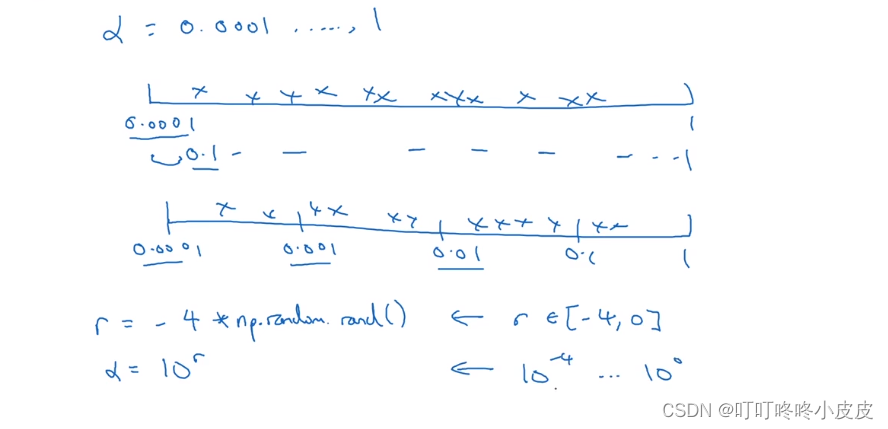
np.random.rand在(0,1)范围内随机取值,然后乘 -4 ,将其作为指数,最终范围限制在(0.0001~1)之间
β取值(公式在下面图片),用于计算指数的加权平均。 假设β是0.9到0.999之间的某个值。当计算指数的加权平均值时,取0.9就像在10个值中计算平均值,有点儿类似于计算10天的温度平均值,而取0.999就是在1000个值里面取平均。
如果想在0.9到0.999区间搜索,那就不能用线性轴取值,否则还是会产生取值不均匀的问题。最好的方法就是,探究1-β,此值在0.1到0.001区间内,所以会给1-β取值,这是10−1,10−3
所以要做的就是在[-3, -1]里随机均匀的给r取值。用这种方式,你在0.9到0.99区间取到的数量,和在0.99到0.999区间取到的一样多。

超参数训练实践:Pandas VS Caviar
- 在数据更新后,要重新评估超参数是否依然合适
- 没有计算资源,你可以试验一个或者少量的模型,不断的调试和观察效果(熊猫式)
- 有计算资源,尽管试验不同参数的模型,最后选择一个最好的(鱼卵式)
归一化网络的激活函数
归一化是为了加快训练速度
Batch归一化使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会使你的训练更加容易
对于任意一层的输入,我们通常将 z[i] 归一化,而不是归一化 a[i],也就是在激活前就进行归一化操作。
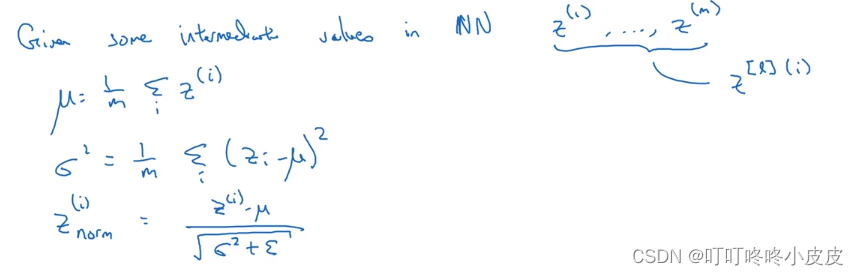
这里的Z(i)是第L层的神经元(省略了上标[L] ),计算均值和方差,并使用均值和方差进行归一化操作,得到Z(i)norm,使得本层的每个神经元平均值为0,方差为1。
但是我们不想让每一层的均值都为0,方差为1;也许有不同的层上,使用不同的分布更有意义,加上2个超参数 γ , β,均是学习参数,在梯度下降 / 类似梯度下降的算法(momentum / Adam)中更新,以控制Z~(i)
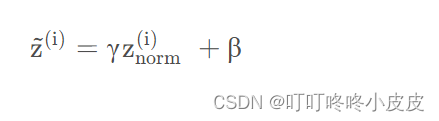
这里是上面式子的证明:
当γ和β分别等于Z(i)norm式的分母分子时,就能明显通过γ,β,Z(i)norm这三个参数确定Z~(i)
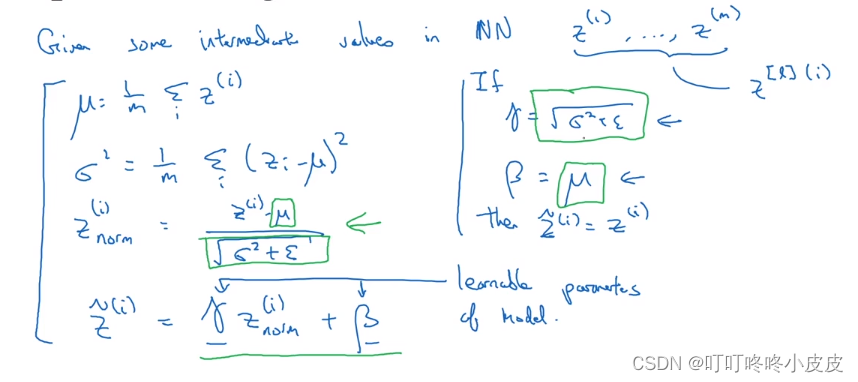
所以设置γ和β可以构造含其它均值和方差的隐藏单元值
将 Batch Norm 拟合进神经网络
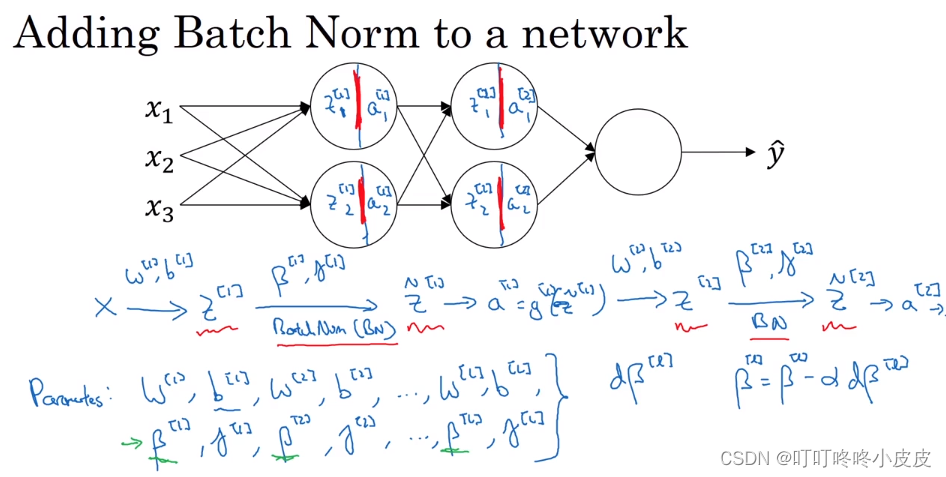
先输入X,借助参数w和b计算Z,再使用γ和β进行batch norm操作,得到Z~,再通过激活函数得到a。
此后,网络中参数除了w和b,还应该有各层的γ和β,并且这些γ和β也是通过和w类似的更新策略进行更新。
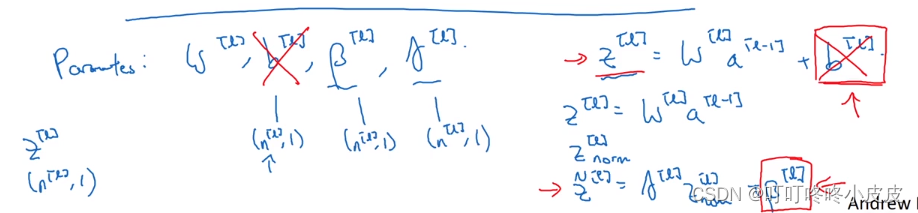
如果使用batch归一化,由于每层中每个单元的Z = WX+b中都加了b,回顾上面Z(i)norm的计算公式分子部分,相当于每个都加b,减去均值肯定也加b,等于没加。所以可以不考虑参数b。
提醒一下各参数的尺寸,β和γ均为 (n[l] , 1)
为何BN可以生效
- 原因1: 归一化使得输入特征、隐藏单元的值获得类似的范围,可以加速学习。
经常会出现一个问题:如果已经训练好x到y的映射,这时再更换x的分布,可能需要重新训练。
- 原因2 : 归一化可以保证,即使输入值变化,但是他们的均值和方差不会发生变化。因为这些值是由上面提到γ 和 β确定的。
作用:
限制了由于前面隐藏层发生参数变化,影响本层输入分布的程度,简单说就是增强了输入改变时的稳定性。
在每一层进行BN就可以使每一层与前一层 or 后一层的相互作用减弱,降低耦合度
同时,BN有轻微的正则化效果。
个人理解:正则化通过增加噪声防止过拟合,norm通过调整input的分布来降低训练集改变对后面层的影响,但会带来噪音,所以也有轻微正则化作用
测试时的 Batch Norm
训练时, μ和σ² 是在当前mini-batch上计算。

但是测试的时候,我们需要对每一个样本进行预测,无法进行均值和方差的计算。同样的道理,就像我们在训练的时候,可以得到权重W和偏置b,但是我们在测试的时候,则是通过这些参数来进行预测,而无法求出测试样本所对应的W和b。
你或许不能将一个 mini-batch 中的所有样本同时处理,可能需要逐一处理,需要使用加权平均运算μ和σ²的值。
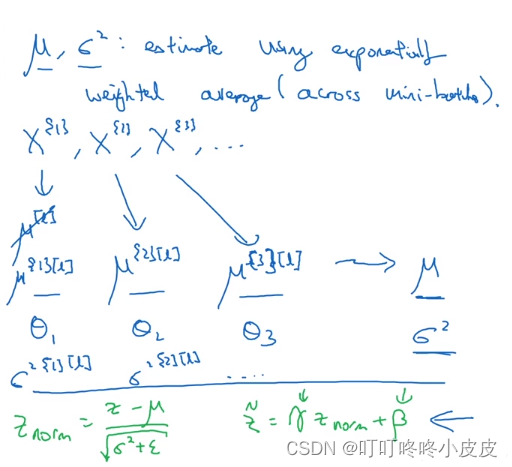

- 训练集:均值方差只用当前mini_batch计算
- 测试集:均值方差使用测试集样本的移动加权平均计算
softmax回归
相比softmax,其实之前还有hardmax(是将概率较大直接置1)
在处理多分类问题时,最后根据各个分量的概率,确定是哪个分类,通常使用C表示种类的个数。
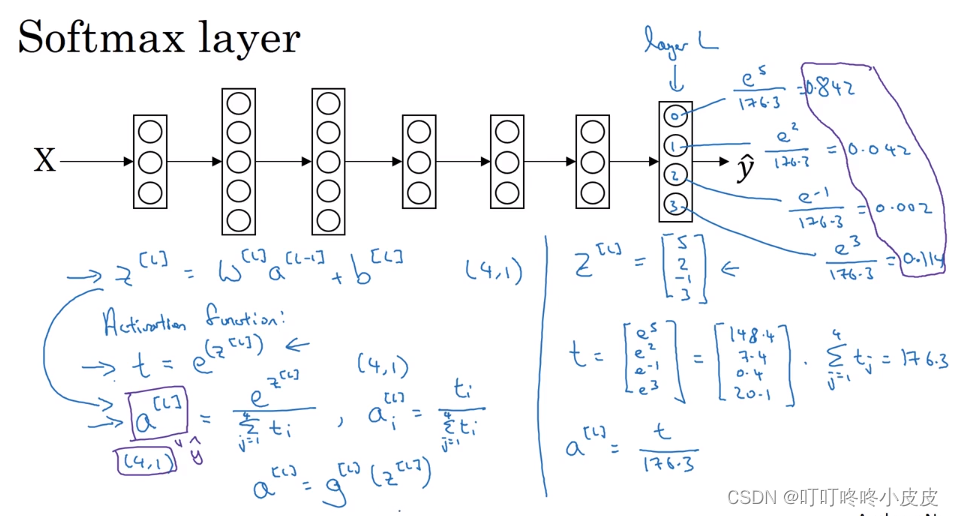
software在最后一层时,左边的a[L]可以理解为g(z[L]),其实这起到归一化效果。根据z输出判断a的结果。右边是一个例子,算得权重分别为:0.842, 0.042, 0.002, 0.114。输出为下标0的分类。
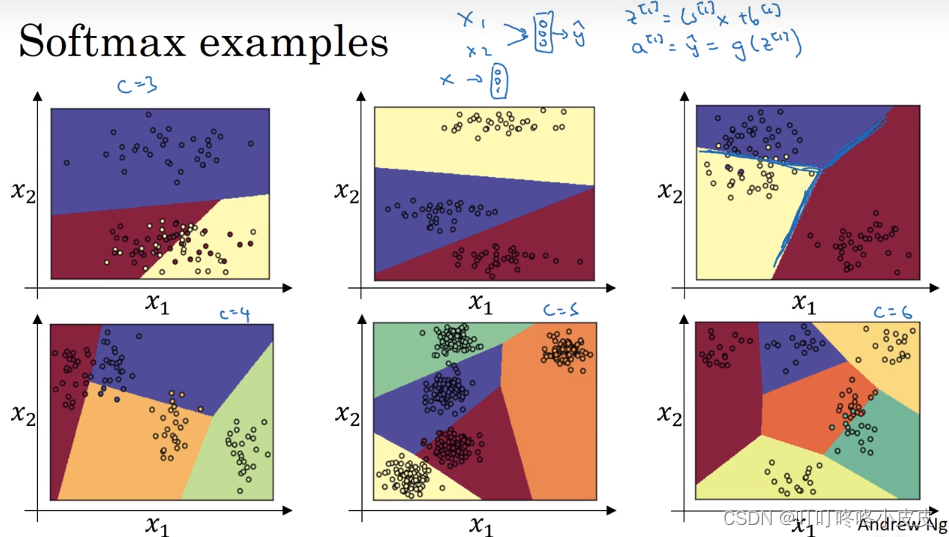
假设没有隐藏层,直接把坐标输入softmax层,不同的分类个数会产生图中的效果,因为没有中间的隐含层,所以决策边界是线性的。
训练一个softmax分类器
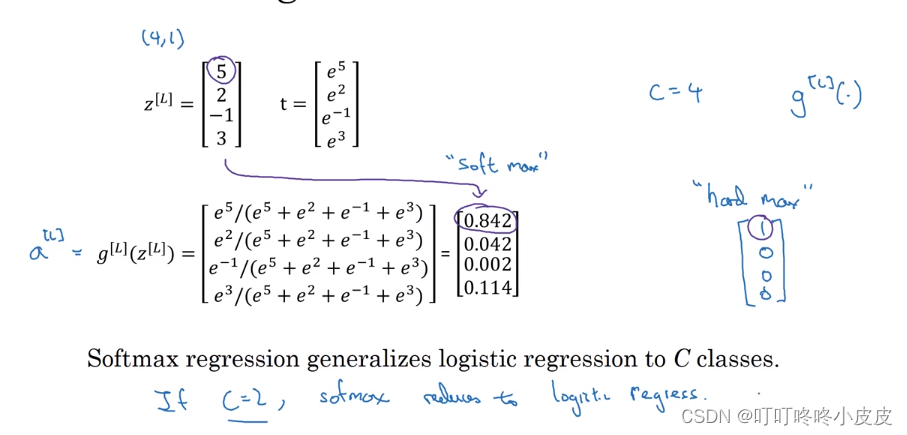
还是我们上一个例子,左边是softmax计算出来的各类型的概率,右边hardmax算法比较武断,直接置0置1。此外,如果C为2,那么其实就是逻辑回归。
softmax的损失函数
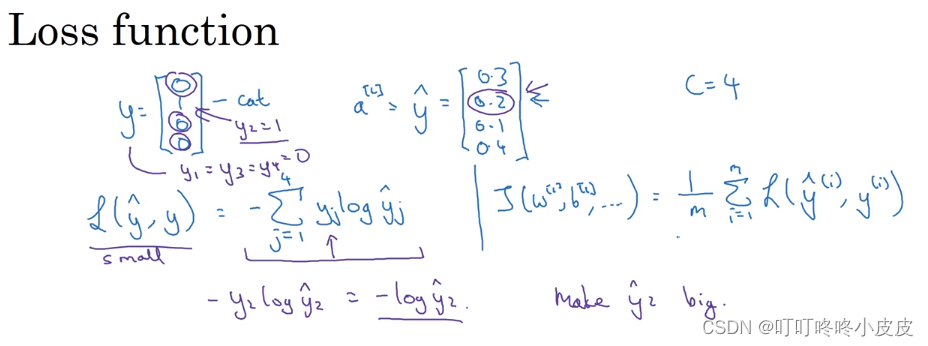
y是我们训练前的真值情况,意思是这个图片是cat。假设右侧是我们前向传播的预测概率,cat概率只有20%。
由于只有y2是1,所以观察代价函数L,如果期待代价函数变小,y2hat 的 值就要变大,其实也就是往正确的方向走。















 2767
2767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









