







什么是ML策略
如何改善模型的性能?
- 收集更多数据
- 训练集多样性(如,识别猫,收集各种姿势的猫,以及反例)
- 训练的时间更长一些
- 尝试不同的优化算法(如 Adam优化)
- 尝试规模 更大 / 更小 的神经网络
- 尝试 DropOut 正则化
- 尝试添加 L2 正则化
- 设计新的网络结构(修改激活函数,隐藏单元数目)
以上方法都可以改变模型的性能,但是需要判断哪些是有效的,哪些是可以放心舍弃的。
正交化
对于目标,设置两个及以上变量, 他们之间夹角90°,互相不会产生影响,最好没有耦合关系,称之为正交化。
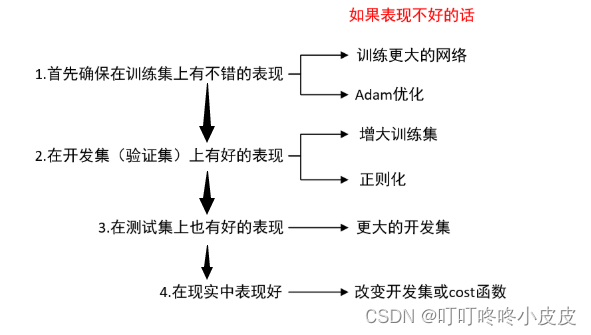
可以在不同阶段发现问题,然后根据位置调整参数。
early stopping,就是一个不那么正交化的方法
过早停止,影响训练集准确率,同时它又可以改善在开发集的准确率
它同时影响两件事情,尽量用其他的正交化控制方法
单一数字评估指标
通过某个单一指标,可以快速知道,新的调整是更好/更坏

查准率(precision):对于某个样本,正确识别的可能性
查全率(recall):对于所有样本,正确识别了其中多少
例如A在查全率上表现较好,B在查准率上表现较好。其中一个结合查准率和查全率的指标是F1分数,可以视为查全率和查准率的平均值:
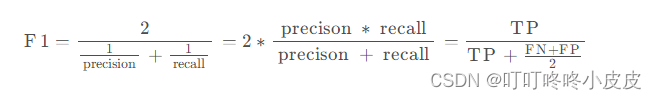
满足和优化指标

考虑 N 个指标,有时候选择其中一个做为优化指标是合理的。
尽量优化那个指标,然后剩下 N-1 个指标都是满足指标,意味着只要它们达到一定阈值,你不再关心指标在阈值内的大小。
训练集,开发集,测试集 划分
开发集:又称交叉验证集,用来评估不同ideal的效果
对测试集和开发集的选择,应该完全随机打乱所有的数据,重新划分。
开发集和测试集的大小

何时改变开发/测试集的指标

当原本设计的指标,错误的预测算法A是更好的,其实算法A的准确度不可接受的时候,就该改变指标/开发集/测试集了。

后面L函数用来统计分类错误的例子,通过增加权重部分,赋予涩情图片更大的权重,一旦把涩情图片识别为猫,立刻导致Error变大。
本课重点在于,当你发现误差指标不合适,立即停用。
再比如:你的开发/测试集都是很清晰的专业图片,而应用最终上线是针对不专业的图片(模糊,角度不好等),那么就要更改开发/测试集,加入不专业图片作为训练数据。
人类的表现水平
把机器学习的水平和人类的水平相比较是很自然的。
当机器水平次于人类时,有方法让他逼近人类水平
但是超过人类后,很难有方法比人类做的更好

贝叶斯错误率是理论上的最低错误率
可避免误差
- 当人类和训练集差距很大时候,先处理偏差。
- 当训练集和开发集差距很大时候,先处理方差。

将贝叶斯错误率与训练错误率之间的差值,称为可避免误差,可能是各种原因造成,没有必要绝对逼近。可以以上面0.5%为一个指标
理解人的表现

由于人类医生团队已经能达到0.5%的错误率,那么可能有更厉害的团队能达到能低的错误率,所以贝叶斯错误率最高接受0.5%错误率,理论上错误率应该更低,一定低于0.5%
人类水平错误率:可以作为贝叶斯错误率的替代品

超过人的表现

情况B:超过 0.5% 的门槛(比最好的医生的误差还低),要进一步优化你的机器学习问题就没有明确的选项和前进的方向了
改善你的模型的表现
改进偏差:
- 更大规模的模型
- 训练更久、迭代次数更多
- 更好的优化算法(Momentum、RMSprop、Adam)
- 更好的新的神经网络结构
- 更好的超参数
- 改变激活函数、网络层数、隐藏单元数
- 其他模型(循环NN,卷积NN)
改进方差:
- 收集更多的数据去训练
- 正则化(L2正则、dropout正则、数据增强)
- 更好的新的神经网络结构
- 更好的超参数















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









