









PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification) 等
官网:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
PASCAL VOC2012数据集介绍_pascal voc 2012-CSDN博客
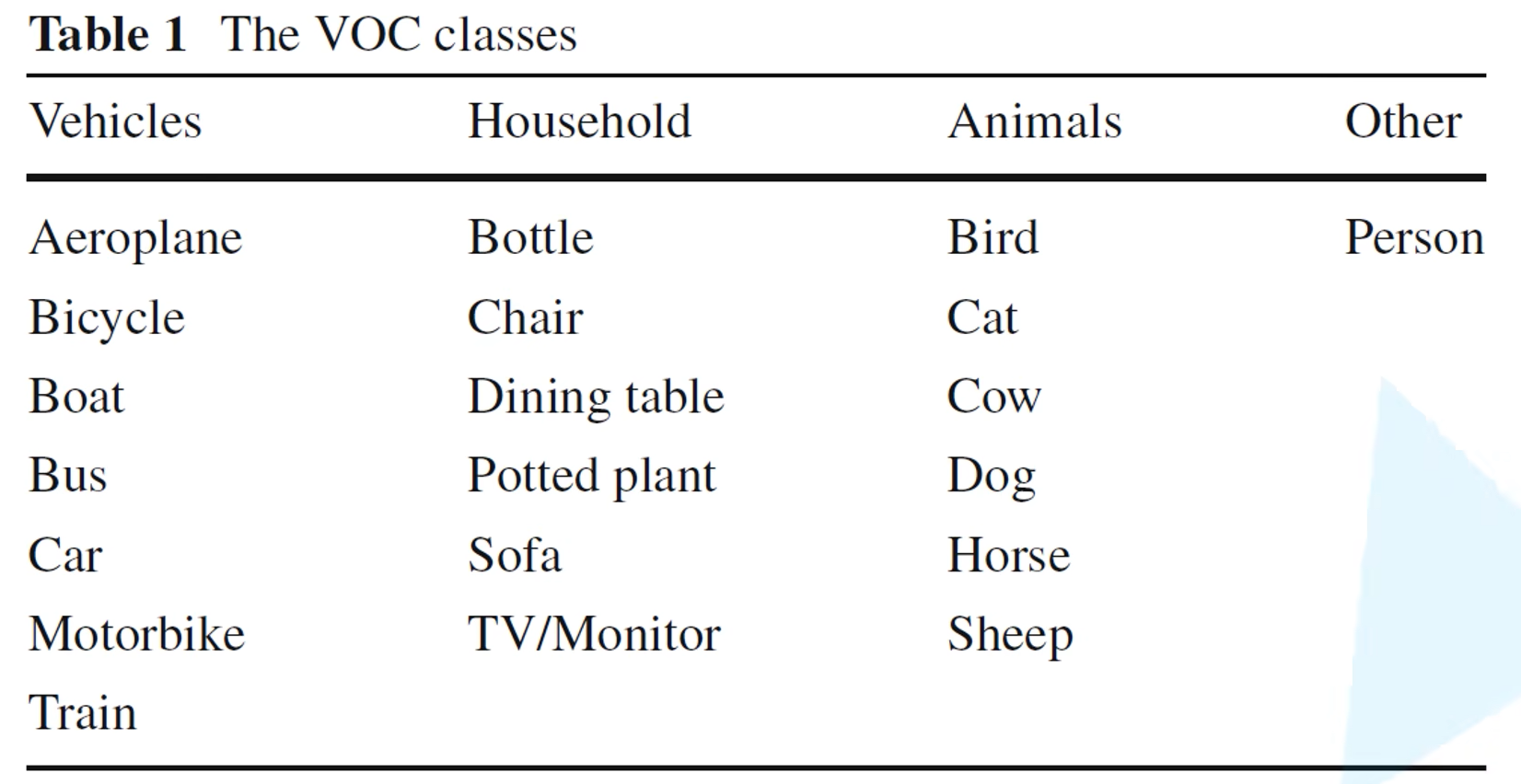
在Pascal VOC数据集中主要包含20个目标类别,下图展示了所有类别的名称以及所属超类。
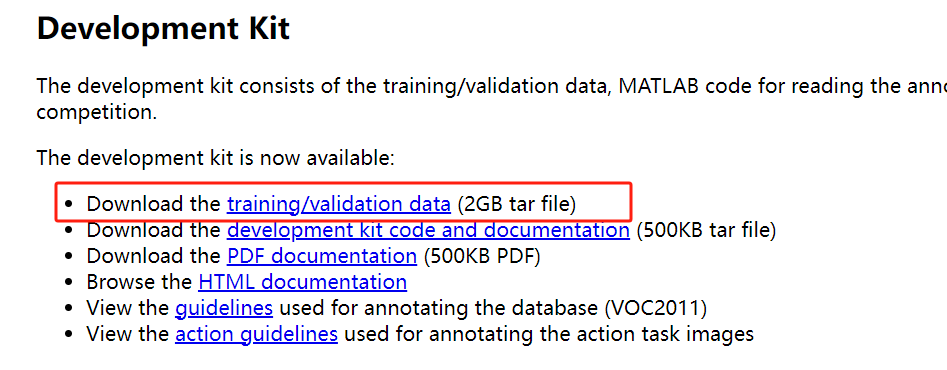
下载地址: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
打开链接后如下图所示,只用下载training/validation data (2GB tar file)文件即可。
下载后将文件进行解压,解压后的文件目录结构如下所示:
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)
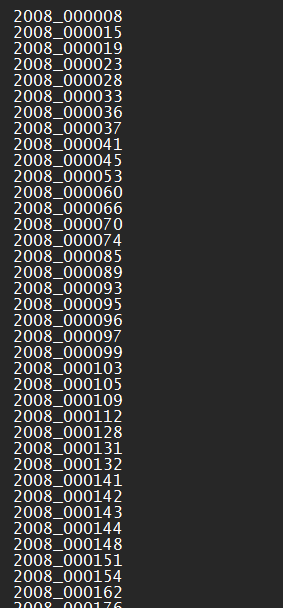
注意,train.txt、val.txt和trainval.txt文件里记录的是对应标注文件的索引,每一行对应一个索引信息,也就是图片名称。如下图所示:

目标检测任务
接下来简单介绍下如何使用该数据集中目标检测的数据。
- 首先在Main文件中,读取对应的txt文件(注意,在Main文件夹里除了train.txt、val.txt和trainval.txt文件外,还有针对每个类别的文件,例如bus_train.txt、bus_val.txt和bus_trainval.txt)。比如使用train.txt中的数据进行训练,那么读取该txt文件,解析每一行。上面说了每一行对应一个标签文件的索引。
├── Main 目标检测分类图像信息
│ ├── train.txt 训练集(5717)
│ ├── val.txt 验证集(5823)
│ └── trainval.txt 训练集+验证集(11540)
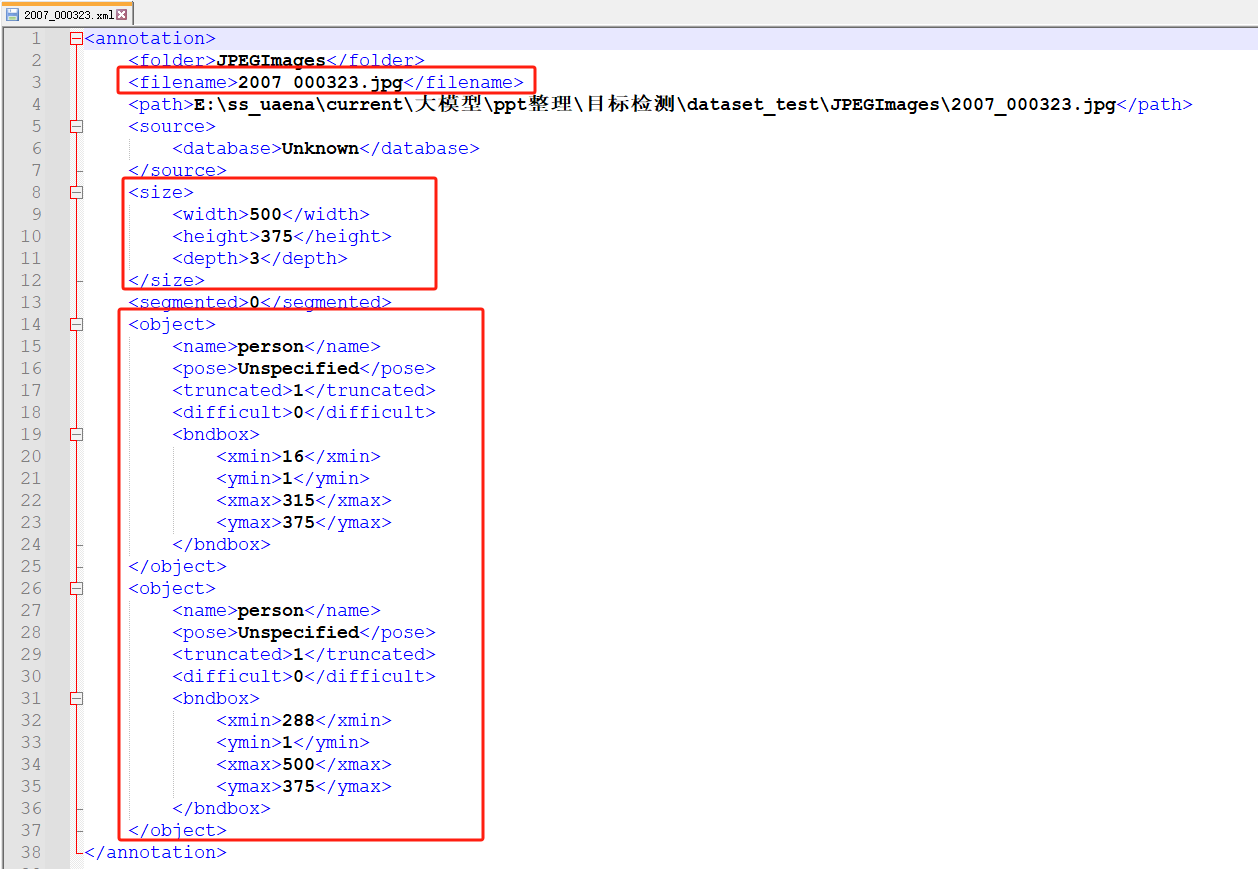
- 接着通过索引在Annotations文件夹下找到对应的标注文件(.xml)。比如索引为2007_000323,那么在Annotations 文件夹中能够找到2007_000323.xml文件。如下图所示,在标注文件中包含了所有需要的信息,比如filename,通过该字段能够在JPEGImages 文件夹中能够找到对应的图片。size记录了对应图像的宽、高以及channel信息。每一个object代表一个目标,其中的name记录了该目标的类别名称,pose表示目标的姿势(朝向),truncated表示目标是否被截断(目标是否完整),difficult表示该目标的检测难易程度(0代表简单,1表示困难),bndbox记录了该目标的边界框信息。
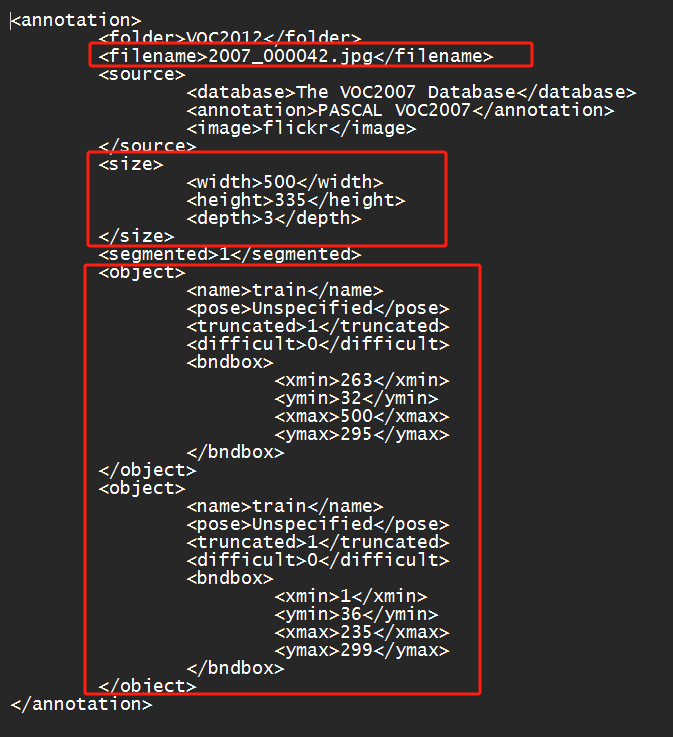
- 接着通过在标注文件中的filename字段在JPEGImages 文件夹中找到对应的图片。比如在2007_000323.xml文件中的filename字段为2007_000323.jpg,那么在JPEGImages 文件夹中能够找到2007_000323.jpg文件。
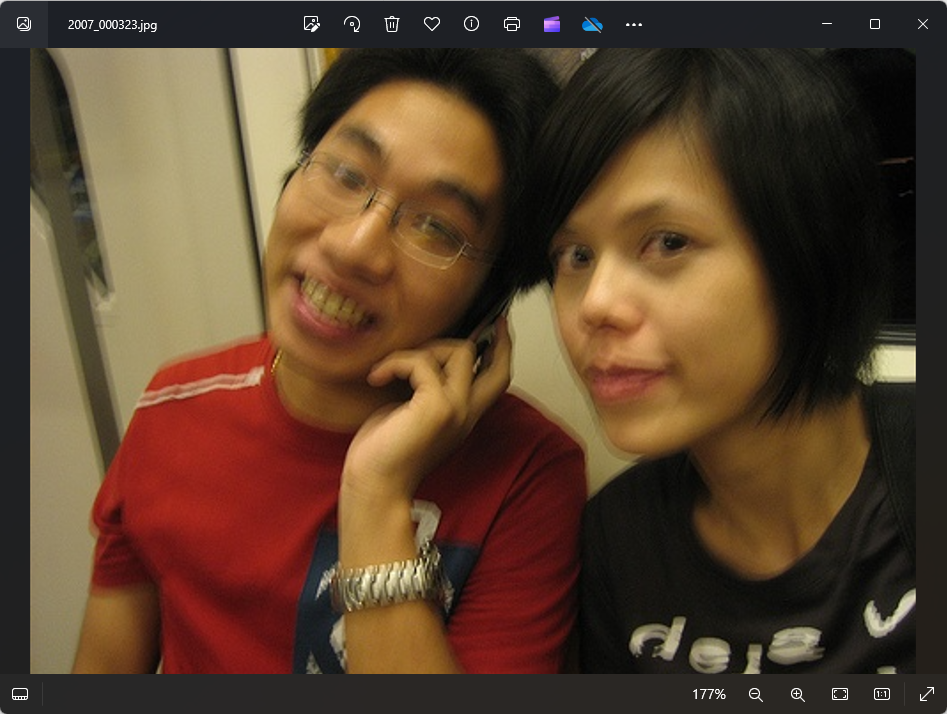
标注自己数据集
- 我们前面使用PASCAL VOC数据集(这个数据集已经给我们标注好了图片的xml信息) 通过 Faster R-CNN训练,能够预测该数据集中的20种类别。
- 但是实际中 我们自己的数据集可能有不同的类别,并且这些图片还没有标注(也就是还没有根据图片生成xml标记文件),所以我们需要自己确定好 自己数据集的类别,以及需要自己对图片标记,生成标记xml文件。并且这个xml文件的格式要和 PASCAL VOC数据集中的xml文件格式一致。
github标注图片的开源项目:https://github.com/HumanSignal/labelImg,这个开源项目可以生成xml文件。
使用流程:
- 前提准备:需要有 Annotations 和 JPEGImages 两个文件夹,一个用于存放生成的xml文件,一个用于存放我们原始的图片。和一个数据集类别的txt文件。

- 在上面三个文件的目录下,按住shift+右键,选择在此处打开powershell窗口,只有这样会进入conda的默认base环境下。下载并打开 labelImg,打开labelImg的时候,需要选择 生成 xml文件的文件夹,也就是第一步准备的Annotations文件夹。
# 下载工具
pip3 install labelImg
# 打开工具
labelImg
# 指定选项打开工具
# IMAGE_PATH为原始图片的路径。PRE-DEFINED CLASS FILE为我们数据集类别的txt文件
labelImg [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
- 打开之后是这样子的。点击左侧的change Save dir选择保存xml的路径
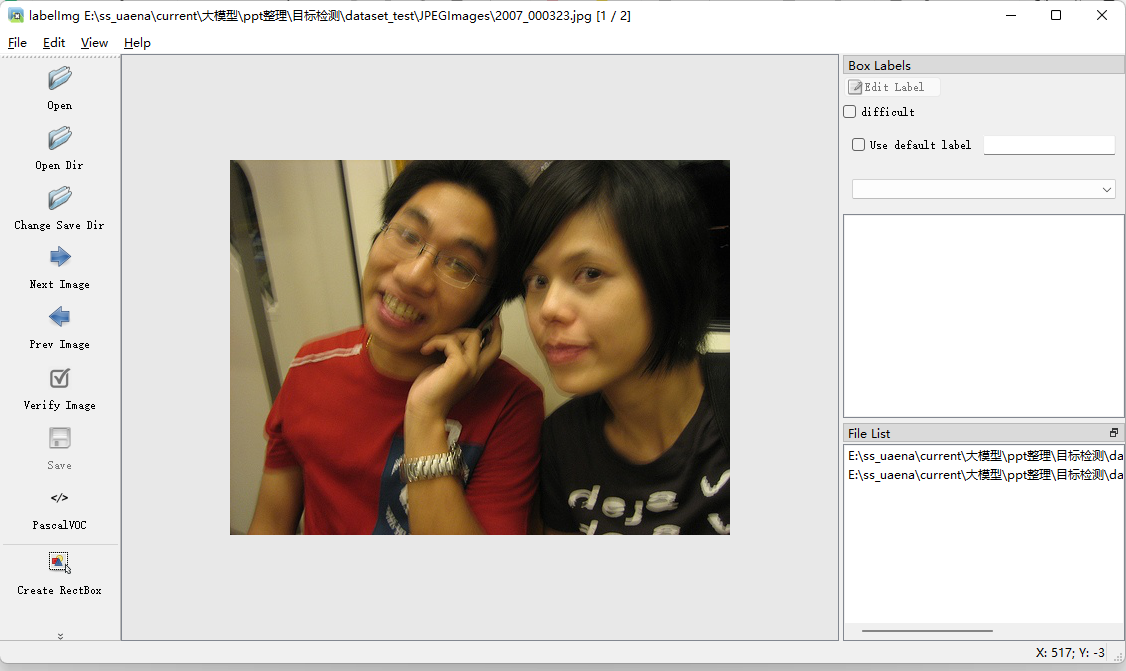
- 点击左侧的 Create RectBox 进行人工标记图片,并点击save保存
- 这样我们就生成了自己图片的xml标记文件。
- 把xml标记文件放到 Annotations中,把原始图片放到 JPEGImages中。注意还需要把 JPEGImages下的图片,按照一定的比例分成 训练集和 验证集,然后取标签文件名分别放到 train.txt 和 val.txt 中
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)
错误总结:
当使用 labelImg1.8.6 标记图片就闪退时。
- 说明python版本太高了,解决方法为创建一个python版本为3.9的虚拟环境,在虚拟环境中安装打开labelimg
- LabelImg的正常运行需要依赖一些库,如PyQt5、lxml等。如果这些依赖库没有正确安装或版本不兼容,也可能导致LabelImg闪退。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









