







 这篇论文介绍了Chain-of-Thought(CoT)提示策略,通过引导大型语言模型生成中间推理步骤来提高其在数学、常识和符号推理任务中的表现。实验表明,CoT不仅提升了模型的解决问题能力,而且对模型规模有显著影响,小模型受益较小,大模型表现更佳。消融实验证实了CoT在推理过程中的核心作用。
这篇论文介绍了Chain-of-Thought(CoT)提示策略,通过引导大型语言模型生成中间推理步骤来提高其在数学、常识和符号推理任务中的表现。实验表明,CoT不仅提升了模型的解决问题能力,而且对模型规模有显著影响,小模型受益较小,大模型表现更佳。消融实验证实了CoT在推理过程中的核心作用。
论文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
⭐⭐⭐⭐⭐
NeurIPS 2022, Google Research
目录
这篇文章提出了思维链(Chain-of-Thought,CoT)的提示策略,也就是引导 LLM 来生成一系列中间推理过程来得到最终答案。
下图是使用 CoT 的示例:
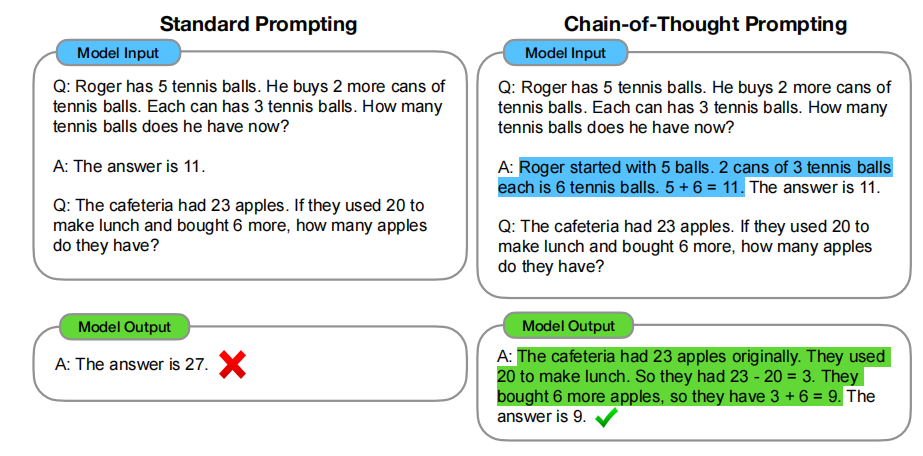
左图没有使用 CoT,右图使用了 CoT,具体的使用方法其实就是,在 in-context learning 的所给的 QA 示例中,answer 不只是一个答案,还包括了产生这个最终答案的中间推理过程,这样,模型就学会了在回答时也产生类似的推理思路,从而得到最终的问题答案。
这个示例就展示了:当输入给 LLM 的问题示例中加入 COT 推理过程,那 LLM 也可以产生 COT 推理。这就是使用思维链来提示模型的具体使用方法。
论文总结了 CoT 的几个有趣的特性:
- CoT 允许模型将多步骤问题分解为多个中间步骤来解决
- CoT 为模型的行为提供了一个可解释的窗口,来表明模型是如何得出答案的
- CoT 擅长用于解决数学、常识推理、符号操作等问题中,并且也可能适用于人类通过语言解决的任何任务
- CoT 并不需要训练模型,只需要在 in-context learning 的 QA 示例中加入思维链推理过程即可
这篇论文有一大部分篇幅都是在介绍如何通过实验来作证 CoT 方法的有效性。论文主要做了三个实验:Arithmetic Reasoning(数学推理)、Commonsense Reasoning(常识推理)、Symbolic Reasoning(符号推理),下面分别介绍这三个实验中值得关注的地方。
论文实验
实验 1:Arithmetic Reasoning(数学推理)
三个实验差不多,所以我们重点关注一下第一个实验。
论文首先介绍了实验的设置,包括采用的数据集、prompt 的设计、采用的模型、采样策略等等:
- 数据集采用了 GSM8K 之类的,这些数据集都是包含很多 math word problem,比如下图:

- prompt 设计:把固定的一组带有思维链提示的 QA 示例作为 few-shots 的 exemplars,每个测试时都是把这些固定的 QA 样本先喂给模型,然后再向模型提问,然后判断模型是否回答正确。
- 采用的模型:使用了多种参数大小尺寸的 GPT-3、LaMDA、PaLM、UL2 和 Codex。
按照以上设置便开始进行实验:
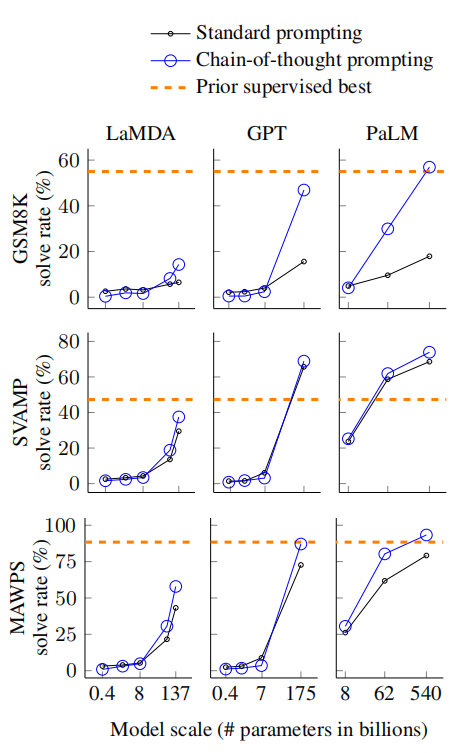
上面这张图:
- 三行图中,每一行图代表了不同的数据集:GSM8K、SVAMP、MAWPS
- 三列中,每一列代表了不同的模型:LaMDA、GPT、PaLM
- 每个坐标图中,横轴代表了模型的参数量,纵轴代表了问题解决成功的比例
- 每个坐标图中,橙色横线的 “Prior supervised best” 表示之前的监督型 SOTA 模型的表现
从这个实验中,论文得出了如下几个小结论:
- CoT 是模型规模的涌现能力之一,因为 CoT 的 prompt 对于小模型产生不了积极影响
- 对于越复杂的问题,CoT 带来的提升越大(因为越复杂的问题越需要推理)
- 带有 CoT 的生成式语言模型在表现上已经超过或接近之前监督模型的 SOTA
同时还对 LLM 的解答情况进行了分析,发现 LLM 的推导过程往往都是正确的(仅有个别推导错了却蒙对了最后答案),而那些最后答案错了的,也是 model 在思维推导过程中出现了小错误或者落掉了步骤。所以说 CoT prompting 是有用的。
另外,发现大的模型能够修复小的模型在思维推导过程中的错误,这也解释了为什么 CoT 在大的模型上才能发挥出作用,因为小的模型很容易在推导过程中产生错误。
论文还做了一些消融实验:
- Equation Only:模型仅被提示输出与问题相关的数学方程式,而不需要生成完整的思维链。这种方法测试了模型是否能够直接将问题转换为数学方程式,而不需要中间的自然语言推理步骤。
- Variable compute only:这个实验是让模型按照 problem 的字符数输出等量的 dots(
...)。这个实验的目的是测试是否是因为 CoT 让 model 有了更多的计算资源才解决了难题。 - Chain of thought after answer:让模型先输出答案,再输出思维推导过程。这样做是为了测试模型是否真的依赖于生成的思维链来给出最终答案。结果显示,这种方法的性能与基线相当,这表明顺序推理在思维链中是有用的,不仅仅是为了激活知识。
消融实验的结果如下:
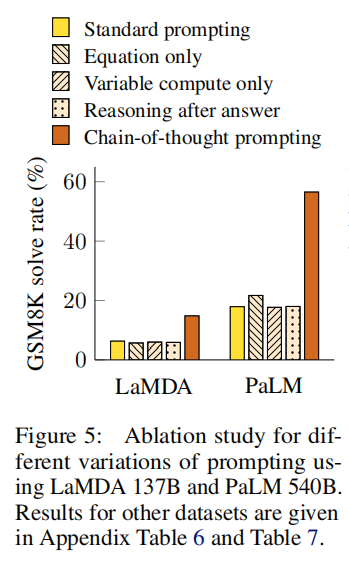
可以看出,xxx-only 都与普通的 prompt 表现相当,远远不及 CoT 的表现,从而佐证 CoT 的思想才是让模型表现优异的原因。
之后,实验又证明了 CoT 方法对于不同思维链的写作风格、不同示例、不同示例的输入顺序、示例的不同数量、不同的语言模型有着鲁棒性,不会因为这些变量的变动会大大影响 CoT 的效果。做这个实验的原因是,对于 prompt 方法来说,对样本的敏感性是很重要的。因为很多 prompt 方法对适用场景十分挑剔。
实验 2:Commonsense Reasoning(常识推理)
实验设置与之前基本一样,将数据集更换为 CSQA 等数据集。
这个实验证明了 CoT 能够大大提升模型在常识推理任务上的表现。
实验 3: Symbolic Reasoning(符号推理)
符号推理尽管对于人来说往往很简单,但对于机器却有很大的挑战。这里使用了两个 toy tasks 来测试模型:
- Last letter concatenation:比如输入
Amy Brown,需要输出各个单词的尾字母的拼接结果yn - Coin flip:一枚 coin 首先朝上的是正面或反面,经过一个场景下多次的反转,需要回答最后朝上的是正面还是反面
另外,测试还分成了 in-domain 测试和 out-of-domain(OOD)测试,两种测试区分如下:

实验结果如下:
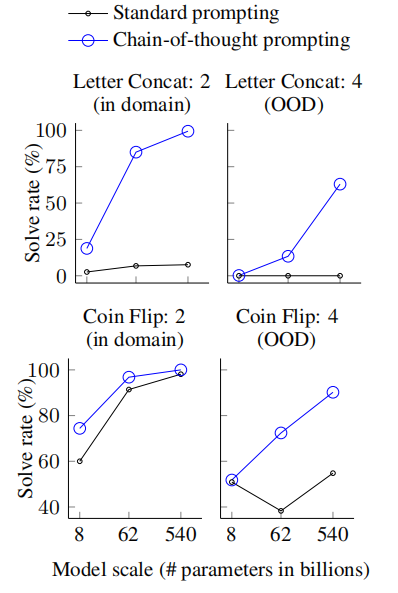
可以看出,OOD 整体表现不如 in-domain 的测试,有了 CoT 的加持也比 standard prompt 效果更好,而且这种效果提升在尺寸较大的模型上表现更好。
论文的 Related Work
CoT 的提出,主要是受以下两个研究方向启发:
- 使用中间过程去解决推理问题
- prompting 的工作
具体相关工作可以参考原论文。
总结
可以说,CoT 通过在 prompt 中加入思维链推导过程,实现了在不需要对 LLM 做任何训练的前提下,明显提高了 LLM 在解决复杂推理问题时的表现,同时拓宽了语言模型所能够解决的推理问题的范围。















 3214
3214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









