







论文:Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
⭐⭐⭐
Tencent AI Lab, arXiv:2311.09210
文章目录
一、论文速读
这篇文章的主要关注于 RAG LLM 模型的以下两个方面:
- Noise Robustness:即能够自动忽视掉检索到的不相关的文档,不要让无关知识误导
- Unknown Robustness:当无法回答用户的提问时,应当承认自己的局限性并回答 “unknown”
本工作提出了 Chain-of-Noting,思路如下:
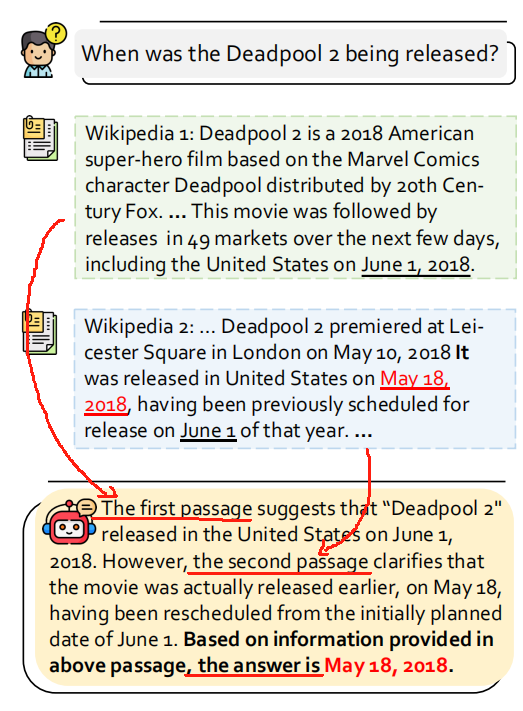
- 用户提出问题 user query q q q 和检索到的 k 个文档 [ d 1 , … , d k ] [d_1, \dots, d_k] [d1,…,dk]
- LLM 针对每一个检索到的文档,生成一段阅读笔记,即针对 passage
d
1
d_1
d1,就生成一段阅读笔记
y
d
1
y_{d_1}
yd1,比如上图中的
The first passage suggests ... - 基于阅读笔记
[
y
d
1
,
…
,
y
d
k
]
[y_{d_1}, \dots, y_{d_k}]
[yd1,…,ydk],LLM 综合这些信息来生成 final response
y
y
y,也就是上图中回答部分的黑体字
Based on information ...
这样就能得到最终的答案。
这里 LLM 是使用了训练的 LLaMa-2 7B 模型,为了能够实现 Noise Robustness 和 Unknown Robustness,关键的工作在于 prompt 的设计、训练数据的收集和对模型的训练。
二、实现的细节
这里关键的工作就是三个:
- Note Design:即设计出模型如何生成 reading notes
- Data Collection:收集用于训练 LLaMa 模型的数据
- Model Training:使用训练数据来训练 LLaMa
2.1 Note Design
阅读笔记(note)的主要目的是为了使模型能够系统地评估每个检索到的文档对输入问题的相关性。这些笔记帮助模型识别文档中的最关键和可靠的信息,同时过滤掉不相关或不可信的内容。
论文定义了三种类型的 note:
- 直接答案型:当检索到的文档直接回答了问题,模型会生成阅读笔记,并基于这些信息形成最终答案。
- 上下文推断型:如果文档没有直接回答问题,但提供了有用的上下文信息,模型会利用这些信息和自身的知识库来推断答案,并生成相应的阅读笔记。
- 无关答案型:当检索到的文档与问题不相关,且模型缺乏足够的知识来回答时,模型会生成表示“未知”的阅读笔记。
这些 note 都是文本形式的摘要,突出显示文档中与问题最相关的部分。
2.2 Data Collection
为了训练 LLaMa-2 7B 以整合 CoN 框架,作者需要收集包含 notes 和 answer 的训练数据。
数据收集过程如下:从 Natural Questions(NQ)数据集中随机抽取了 10,000 个 question,根据这些 question 和相应检索到的 passages,通过 prompt 让 ChatGPT 生成这个 question 的 notes 和 answer,CoN 的 prompt 如下:
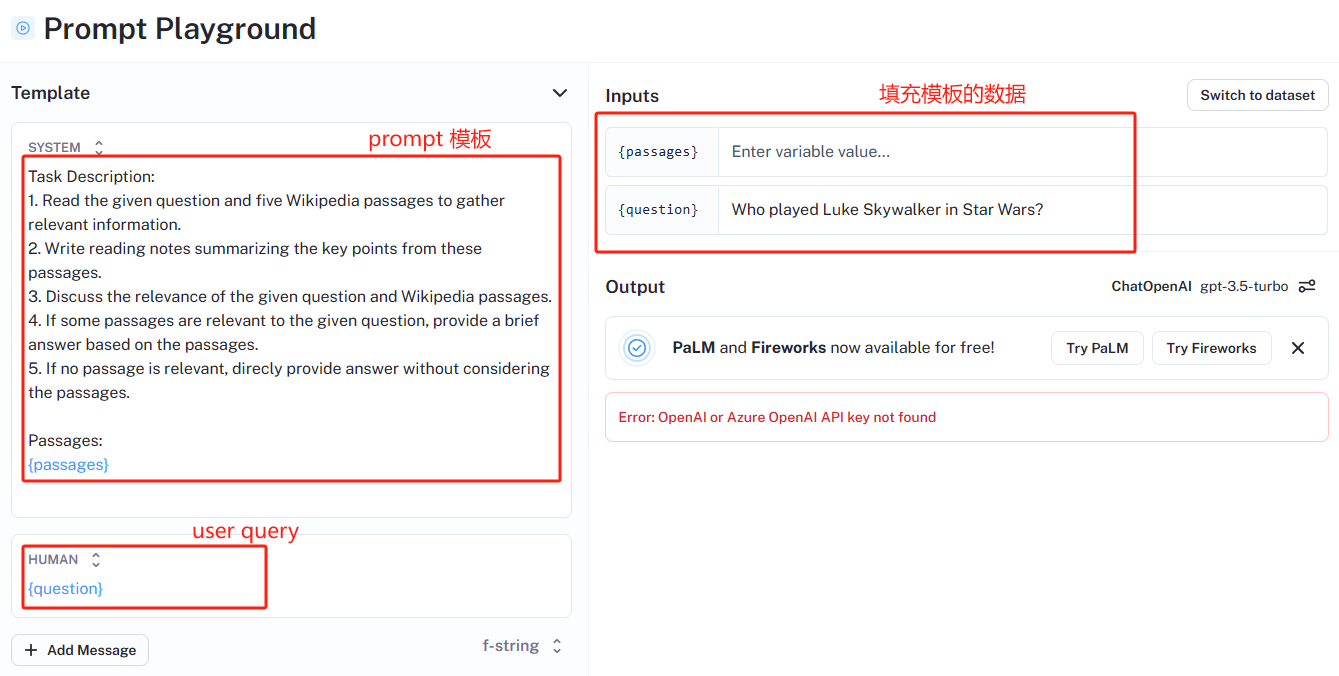
该 prompt 可以在 LangSmith 中体验到:https://smith.langchain.com/hub/bagatur/chain-of-note-wiki/playground?commit=6533425b
通过上面的 prompt,就可以让 ChatGPT 生成训练数据了。之后,ChatGPT 生成的训练数据需要进一步的人工校验。
2.3 Model Training
本工作基于 LLaMa-2 7B 训练,训练时,将 instruction、user question 和 retrieved passages 结合 prompt 作为 input,教 model 生成 notes 和 answer。
损失函数的设计:在 model 的生成中,包含 notes 和 answer,一个很明显的现象是 notes 比 answer 长很多,这样两者对 loss 的 contribute 就不太协调,为了克服这个问题,整个训练过程中 loss 的计算会有变化:
- 50% 的训练时间中,next token prediction 的 loss 是整个 notes 和 answer 的 token 序列的损失
- 50% 的训练时间中,next token prediction 的 loss 是只有 answer 的损失,这样能让 model 也更加专注于最终 answer 的准确度和可靠性
三、实验结果
3.1 QA Performance
如下数据体现了 CoN 的提升效果:

- 第一行是纯 LLaMa 的输出,即 answer = LLM( q q q )
- 第二行是使用 DPR 作为检索器,搭配 LLaMa 做 standard RAG 的效果
- 第三行则是在 standard RAG 上额外附加了 CoN 的效果
3.2 对 Noise Robustness 的实验
噪声数据指的是与查询不相关或误导性的信息,在该实验中,通过故意引入 noise data 来实验 CoN 模型的鲁棒性。
噪声比例(noise ratio)指的是不相关的文档在所有检索到的文档中的比例,通过调整噪声比例,作者们模拟了不同程度的噪声数据对模型性能的影响。
如果需要检索 k 个文档,当噪声比例为 20% 时,那么检索到的 k 个文档中有 1 个是噪声文档,其余 k-1 个是相关文档。
具体的分析可以参考原论文。
3.3 对 Unknown Robustness 的实验
这里使用了 RealTimeQA 数据集,这个数据集的测试内容(因为很新)完全不在训练模型的知识范围内。
在这个实验中,评估模型的拒绝率(RR),拒绝问题的数量/总问题。这突出了我们的模型在初始训练阶段识别和忽略不熟悉或未学习的信息的增强能力。
四、总结
我们都知道,RAG中的召回阶段并不能保证一直能检索出最相关或者最值得信赖的信息。不相关的信息可能会对模型带来错误的指导,即使模型内部已经包含了回答问题的信息,也可能会被忽视。因此,如何进行 RAG 上下文召回的自适应可控回复,如典型的拒答,显得十分重要。
关于拒答逻辑,通过构造诚实样本,进行微调,也可以让模型具备拒答能力:

而本文提出了使用 CoT 类似的思路,使用 Chain-of-Note 提示让 LLM 生成阅读笔记,并用于 RAG 上下文的自适应增强,是可以与其他的思路进行交融的。















 1607
1607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









