



YOLOv12核心创新点解析:Area Attention, R-ELAN以及架构改进
在目标检测领域,YOLOv12 的出现标志着一个重要的里程碑。它通过引入注意力机制,显著提升了模型的性能,同时保持了实时性。本文将详细介绍 YOLOv12 的核心创新点,包括 Area Attention(区域注意力)、Residual Efficient Layer Aggregation Networks(R-ELAN)以及架构改进。
论文地址:https://arxiv.org/abs/2502.12524
代码仓库:https://github.com/sunsmarterjie/yolov12
1. Area Attention(区域注意力)
背景
注意力机制在计算机视觉任务中表现出色,但其计算复杂度较高,尤其是在处理高分辨率图像时。传统的全局注意力机制需要计算每个位置之间的相关性,导致计算量随着输入尺寸的增加而急剧上升。为了解决这一问题,YOLOv12 提出了一种简单而高效的区域注意力模块(Area Attention),通过将特征图划分为多个区域,减少了注意力机制的计算复杂度,同时保持了较大的感受野。

核心创新点
a. 简单而高效的区域划分:
- YOLOv12 将特征图划分为多个区域,每个区域独立进行注意力计算。这种划分方式避免了复杂的窗口划分和反转操作,简化了计算过程。
- 通过将特征图划分为多个区域,每个区域的计算复杂度显著降低,从而提高了模型的推理速度。
b. 保持较大的感受野:
- 尽管特征图被划分为多个区域,但每个区域仍然保持了较大的感受野,能够捕获全局上下文信息。
- 这种设计确保了模型在减少计算复杂度的同时,不会显著降低检测精度。
c. 高效计算:
- 区域注意力模块通过简单的重塑操作实现区域划分,避免了额外的内存开销。
- 这种设计使得注意力机制的计算更加高效,适合实时目标检测任务。
结论
Area Attention 通过将特征图划分为多个区域,显著降低了注意力机制的计算复杂度,同时保持了较大的感受野。这种设计不仅提高了模型的推理速度,还保持了较高的检测精度,为实时目标检测任务提供了一种高效的注意力机制。
2. Residual Efficient Layer Aggregation Networks(R-ELAN)
背景
注意力机制的引入虽然提升了模型的性能,但也带来了优化挑战。传统的注意力机制由于其复杂的计算过程,容易导致梯度消失或梯度爆炸,影响模型的训练稳定性。为了解决这一问题,YOLOv12 引入了残差高效层聚合网络(R-ELAN)。
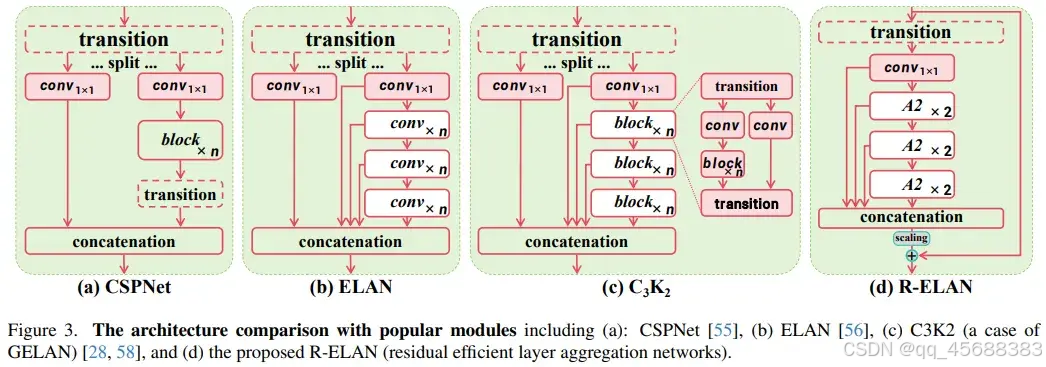
核心创新点
a. 残差连接:
- R-ELAN 引入了残差连接,通过在输入和输出之间添加直接的梯度路径,增强了模型的优化能力。
- 这种设计有助于缓解梯度消失问题,提高模型的训练稳定性。
b. 重新设计的特征聚合方法:
- R-ELAN 重新设计了特征聚合方法,通过在特征图的不同层次之间进行有效的信息交换,增强了特征表达能力。
- 这种设计不仅提高了模型的表达能力,还减少了计算复杂度和参数量。
c. 块级残差设计:
- R-ELAN 在块级引入了残差设计,通过在每个块内部添加残差连接,进一步增强了模型的优化能力。
- 这种设计使得模型在处理大规模数据时更加稳定,提高了模型的泛化能力。
结论
R-ELAN 通过引入残差连接和重新设计的特征聚合方法,显著增强了模型的优化能力和特征表达能力。这种设计不仅提高了模型的训练稳定性,还提升了模型的检测性能,为实时目标检测任务提供了一种高效的网络架构。
3. 架构改进
背景
传统的注意力机制在设计上存在一些局限性,例如内存访问效率低、计算复杂度高、模型设计复杂等。为了解决这些问题,YOLOv12 在传统注意力机制的基础上进行了多项改进。
核心创新点
a. 引入 FlashAttention:
- YOLOv12 引入了 FlashAttention 技术,通过优化内存访问模式,显著提高了注意力机制的计算效率。
- FlashAttention 通过减少内存访问开销,提高了模型的推理速度,适合实时目标检测任务。
b. 去除位置编码:
- YOLOv12 去除了位置编码,简化了模型设计。
- 通过去除位置编码,模型变得更加简洁,同时减少了计算复杂度和参数量。
c. 调整 MLP 比例:
- YOLOv12 调整了 MLP(多层感知器)的比例,优化了计算资源的分配。
- 通过调整 MLP 比例,模型在保持性能的同时,减少了计算复杂度和参数量。
d. 使用卷积操作代替线性操作:
- YOLOv12 使用卷积操作代替线性操作,提高了计算效率。
- 卷积操作具有更高的计算效率和更好的并行性,适合实时目标检测任务。
结论
YOLOv12 通过引入 FlashAttention、去除位置编码、调整 MLP 比例和使用卷积操作代替线性操作,显著优化了传统注意力机制的计算效率和模型设计。这些改进不仅提高了模型的推理速度,还保持了较高的检测精度,为实时目标检测任务提供了一种高效且简洁的网络架构。

















 2983
2983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









