







目录
大家好,今天要给大家介绍的是最新发布的目标检测模型——YOLOv12。相信关注计算机视觉和深度学习的小伙伴们都已经听说过YOLO系列,作为目标检测领域的“老牌明星”,YOLO每次更新都会带来不少惊喜。那么,新鲜出炉的YOLOv12,它到底有哪些亮点呢?今天,就让我们一起来深入了解一下!
一、YOLOv12论文信息

论文题目:YOLOv12: Attention-Centric Real-Time Object Detectors
论文链接:https://arxiv.org/abs/2502.12524
代码链接:https://github.com/sunsmarterjie/yolov12
二、YOLOv12性能突破
YOLOv12共包含了5种规模:YOLOv12-N、S、M、L和X。
YOLOv12在准确率和速度上超越了所有流行的实时物体检测器。例如,YOLOv12-N在T4 GPU上的推理延迟为1.64ms,达到40.6%的mAP,比先进的YOLOv10-N/YOLOv11-N高出2.1%/1.2%的mAP,而速度相当。这一优势在其他规模的模型中同样保持一致。YOLOv12还超越了改进DETR的端到端实时检测器,如RT-DETR/RT-DETRv2:YOLOv12-S比RT-DETR-R18/RT-DETRv2-R18快42%,仅使用36%的计算和45%的参数。
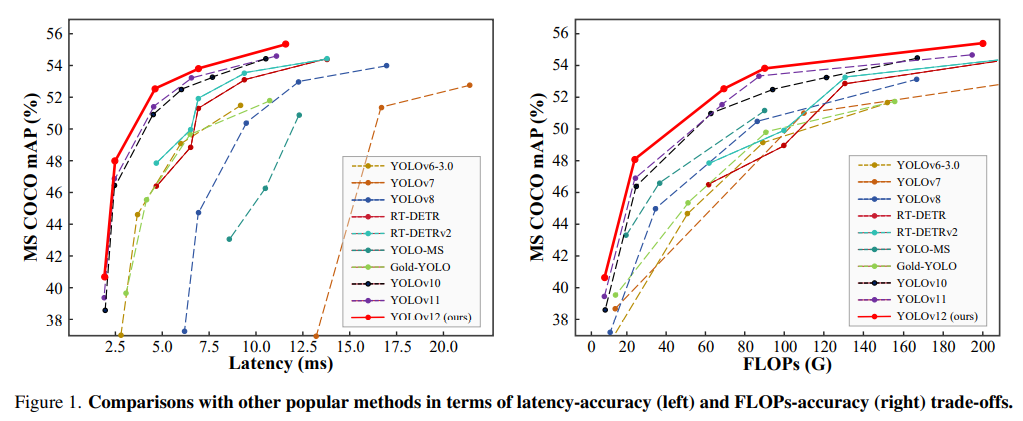
三、YOLOv12:技术创新和突破
YOLOv12是YOLO系列的最新版本,它继承了YOLO系列的高效和快速,并在此基础上做出了很多技术创新和优化。
-
区域注意力模块
为了克服传统自注意力机制计算复杂度高的问题,YOLOv12通过创新的区域注意力模块(Area Attention,A2),分辨率为(H, W)的特征图被划分为l个大小为(H/l, W)或(H, W/l)的段。这消除了显式的窗口划分,仅需要简单的重塑操作,从而实现更快的速度。将l的默认值设置为4,将感受野减小到原来的1/4,但仍保持较大的感受野。采用这种方法,注意力机制的计算成本从2n²hd降低到1/2n²hd。尽管存在n²的复杂度,但当n固定为640时(如果输入分辨率增加,则n会增加),这仍然足够高效,可以满足YOLO系统的实时要求。A2降低了注意力机制的计算成本,同时保持较大的感受野,显著提升了检测精度。

-
残差高效层聚合网络(R-ELAN)
针对传统ELAN(高效层聚合网络)在优化过程中的不稳定性问题,YOLOv12引入了R-ELAN,在整个块中从输入到输出引入了一个具有缩放因子(默认为0.01)的残差捷径。通过新的聚合方法,使用一个过渡层来调整通道维度,并生成一个单一的特征图。然后,该特征图通过后续块进行处理,接着进行连接,形成一个瓶颈结构。使得网络在处理大规模模型时能够更加稳定和高效,还降低了计算成本和参数/内存使用量。
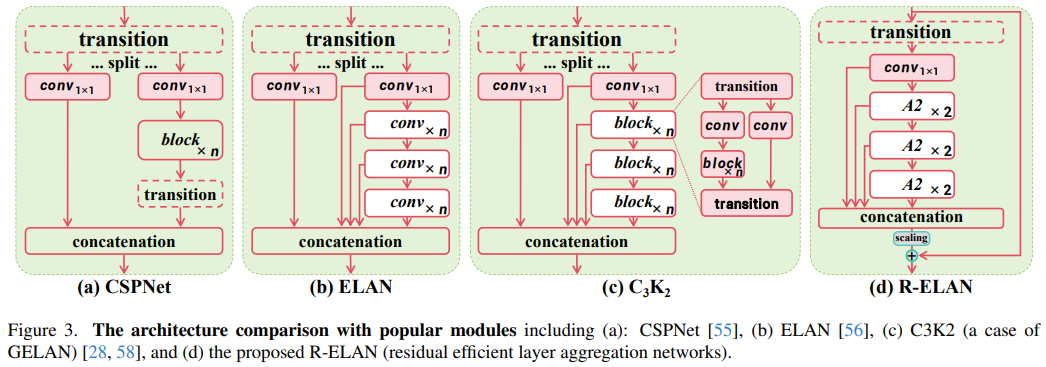
-
架构优化
引入FlashAttention来解决注意力的内存访问问题,减少了内存读写延迟,提高了计算效率。调整MLP比率,进一步提升了速度和精度,去除了位置编码,并引入了大卷积核(7×7卷积),有效增强了网络对位置的感知能力,同时保持了计算效率。
综上所述,YOLOv12的贡献有两方面:
-
建立了一个以注意力机制为中心,简洁高效的YOLO框架,通过方法创新和架构改进,打破了YOLO系列中CNN模型的主导地位。
-
YOLOv12无需依赖预训练等额外技术,就能以更快的推理速度和更高的检测准确率取得最佳效果,展现出其巨大的潜力。
四、Coovally AI模型训练与应用平台
你想第一时间使用YOLOv12模型吗?Coovally平台满足你的要求!
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是最新的YOLOv12模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
在Coovally平台上,无需配置环境、修改配置文件等繁琐操作,可一键另存为我的模型,上传数据集,即可使用YOLO、Faster RCNN等热门模型进行训练与结果预测,全程高速零代码!而且模型还可分享与下载,满足你的实验研究与产业应用。
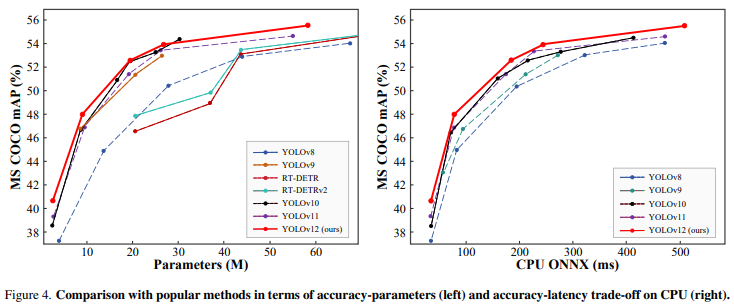
五、YOLOv12实验比较
-
在COCO上的详细性能
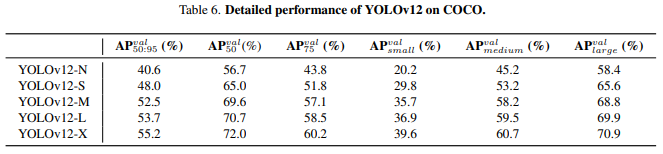
-
与其他实时监测器的性能比较
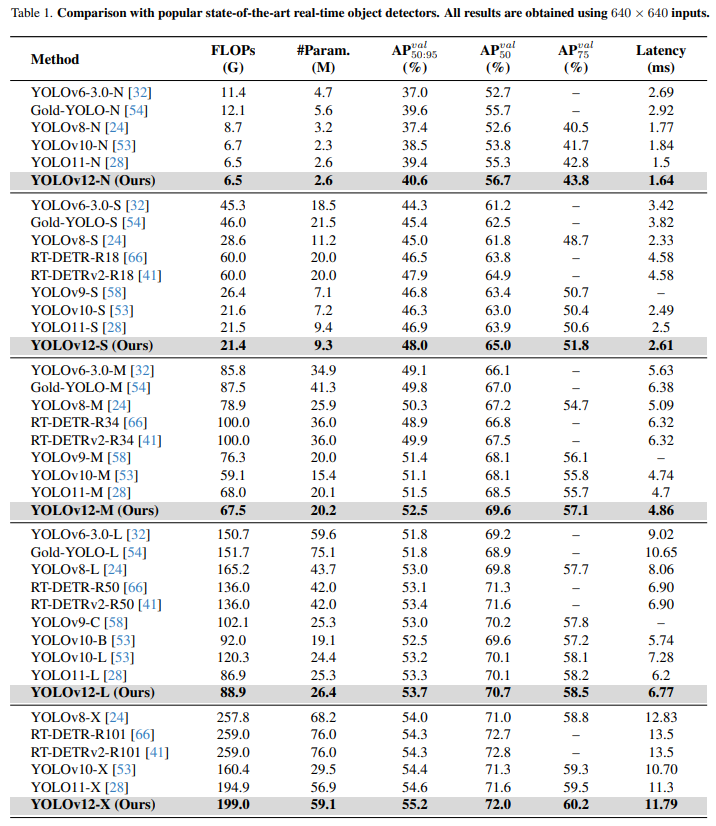
YOLOv12-N:在推理延迟为1.64毫秒时,mAP达到了40.6%,较YOLOv11提高了1.2%,推理速度也更快。
YOLOv12-S:相较于RT-DETR-R18/RT-DETRv2-R18,YOLOv12-S实现了38.6%的推理速度提升,且mAP较其高出1.5%/1.1%。与此同时,YOLOv12-S仅使用了36%的计算量和45%的参数数量。
YOLOv12-X:对于大型模型,YOLOv12-X在更复杂的任务中依然展现出优异的性能,并能高效处理大规模数据。
-
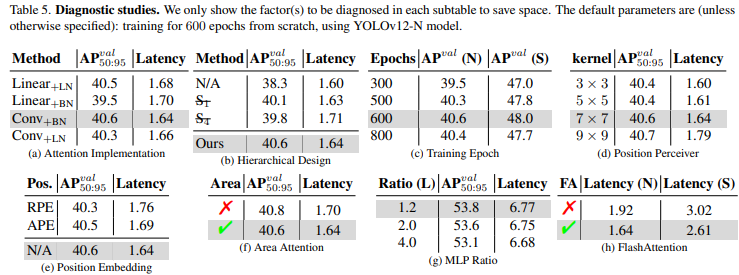
消融实验
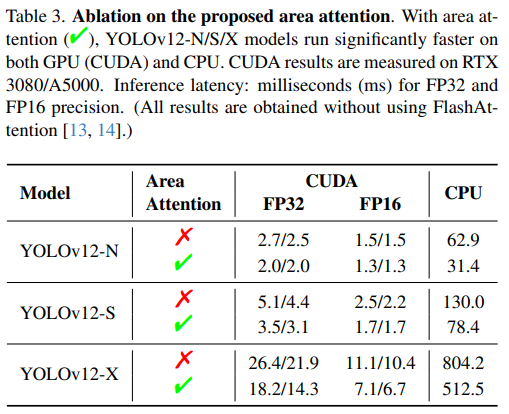
区域注意力模块:进行了消融实验来验证区域注意的有效性,评估是在 YOLOv12-N/S/X模型上进行的,测量了GPU(CUDA)和CPU上的推理速度。在RTX 3080上使用FP32,YOLOv12-N实现了减少0.7ms推理时间。这种性能提升在不同的模型和硬件配置中都得到了一致的体现。
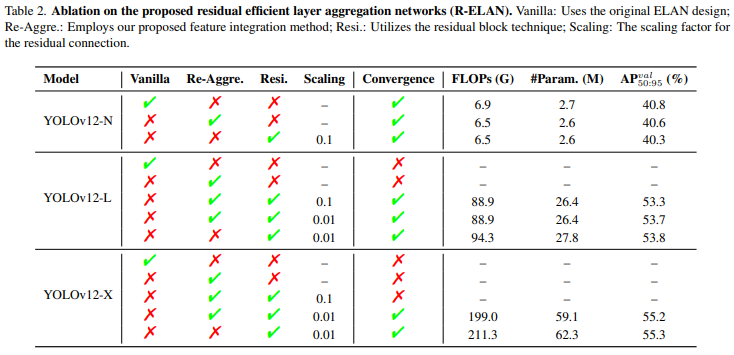
R-ELAN:使用YOLOv12-N/L/X模型评估了所提出的残差高效层网络(R-ELAN)的有效性。对于像YOLOv12-N这样的小模型,残差连接不会影响收敛,但会降低性能。相反,对于较大的模型(YOLOv12-L/X),它们对于稳定的训练至关重要。特别是,YOLOv12-X需要最小缩放因子(0.01)以确保收敛。特征集成方法有效地降低了模型在FLOP和参数方面的复杂性,同时保持了可比的性能,仅有轻微的下降。
-
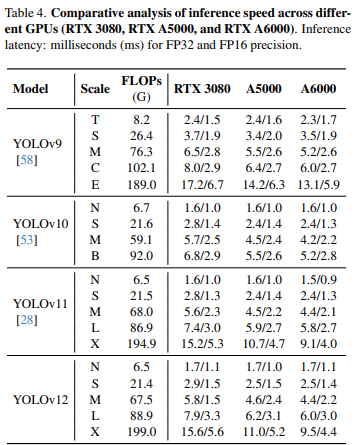
速度比较
对不同GPU的推理速度进行了比较分析,评估了YOLOv9、YOLOv10、YOLOv11以及在RTX 3080、RTX A5000和RTX A6000上以FP32和FP16精度进行的YOLOv12。在RTX 3080上,YOLOv9报告2.4毫秒(FP32)和1.5毫秒(FP16),而YOLOv12-N实现了1.7毫秒(FP32)和1.1ms(FP16)。其他配置也存在类似的趋势。
-
诊断与可视化
YOLOv12通过优化注意力机制、分层设计、训练周期、位置感知和区域关注等多方面创新,提升了工件检测的性能和计算效率。
可视化分析热图分析显示,YOLOv12相比YOLOv10和YOLOv11在物体作用和前景激活上更清晰,表明区域注意在感知能力上的提升,使YOLOv12在性能上具备优势。

六、YOLOv12局限性
-
YOLOv12 目前的局限性在于它依赖FlashAttention来实现最佳速度。FlashAttention 仅支持相对较新的 GPU 架构(NVIDIA Turing、Ampere、Ada Lovelace 或 Hopper 系列),例如 Tesla T4、RTX 20/30/40 系列、A100、H100 等。
-
这意味着缺乏这些架构的旧 GPU 无法充分受益于 YOLOv12 优化的注意力实现。使用不受支持的硬件的用户将不得不回退到标准注意力内核,从而失去一些速度优势。
-
目前,作者尚未尝试将 YOLOv12 用于其他任务,例如姿势估计和实例分割。不过,作者可能会在未来提供相关结果。
总结
YOLOv12通过创新的区域注意力模块、残差层高效网络和架构优化,在精度、推理速度和计算效率上实现了突破,并挑战了基于CNN的设计在YOLO系统中的主导地位,并推动了注意力机制在实时物体检测中的集成,为未来的实时检测系统开辟了新的方向。



















 7966
7966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









