







摘要
从二维图像的三维重建被广泛的研究,训练与深度监督。为了放松对昂贵获取的数据集的依赖,我们提出了SceneRF,一种自监督的单目场景重建方法,只使用姿态图像序列进行训练。我们通过显式的深度优化和一种新的概率采样策略来有效地处理大场景。在推理时,一个输入图像足以产生新的深度视图,将其融合在一起得到三维场景重建。实验表明,在室内BundleFusion 和室外Semantic kitti上,我们在新的深度视图合成和场景重建方面优于所有最近的基线
一、前言
虽然双目视觉对感知环境是一个明显的进化优势,但生理学研究表明,即使使用单眼视觉,人类也能感知深度。
3D领域的一小部分处理了从单个图像[重建复杂场景,但它们都需要深度监督,不能仅限图像。同时,NeRF从一个或多个视角自我监督地优化了辐射场,在新观点合成方面以前所未有的表现带来很多衍生物。然而,当涉及到单视图输入时,它们大多仅限于对象。对于复杂的场景,除了[33]之外,所有的都使用合成数据[62]训练或需要额外的几何线索来训练真实数据。减少对复杂场景的监督需求将降低我们对成本获得的数据集的依赖。
在这项工作中,我们以一种完全自监督的方式来处理复杂的(可能是大的)场景的单视图重建。SceneRF只训练一序列的姿态图像,以优化一个大的NeRF。图1说明了单个RGB图像足以从在任意位置采样的合成的新深度/视图的融合中重建三维场景的推断。我们以PixelNeRF [78]为基础,并提出了具体的设计选择来显式地优化深度。
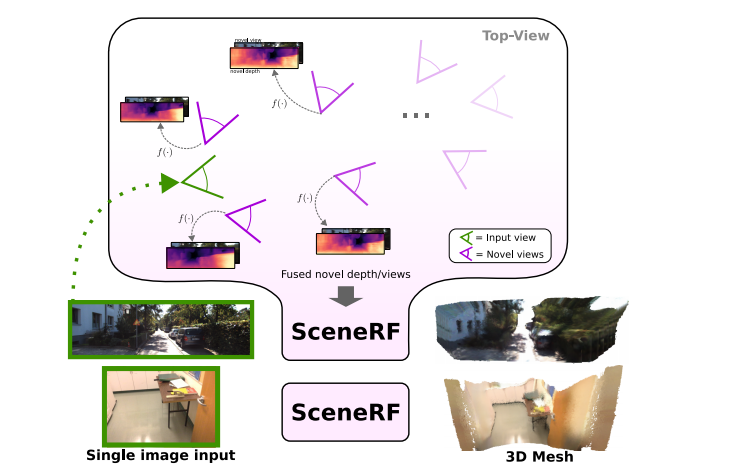
针对大场景的挑战,我们引入了一种新的概率射线采样在大辐射体内有效地选择优化稀疏位置,并引入了球形U-Net,目的是生成超出输入图像视场范围的数据、特征或可视化结果。
二、方法
SceneRF学习从单目RGB图像中推断场景的几何形状,使用图像条件的神经辐射场(NeRFs)以自监督的方式进行训练。给定一个由S序列组成的训练集,每个序列都有m个具有相应姿态的RGB图像,记为:
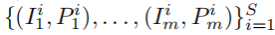 。我们估计了一个基于第一个序列框架的神经表示, conditioning learned 在序列中共享,并由其他框架进行自监督优化。
。我们估计了一个基于第一个序列框架的神经表示, conditioning learned 在序列中共享,并由其他框架进行自监督优化。
2.1.用于新的深度合成的NeRF
最初的NeRFs 优化连续体积辐射场:对于一个给定的3D点x∈R3 和观察方向d∈R3,它返回一个密度σ和RGB颜色c。我们将基于PixelNeRF [78]来学习跨序列的可推广的辐射场,并引入新的 design choices 来有效地合成新的深度视图。
SceneRF的训练过程如图2所示。给定序列1的第一个输入帧 I1,我们用我们的SU-Net提取一个特征volume: W = E(I1)。然后,随机选择一个source 未来帧 Ij,2≤j≤m,并从中随机抽取 L 个像素。已知source 的 pose 和相机内参,可有效地沿着通过该像素的射线,采样N个点。将每个采样点x投影到具有 ψ(·) 的一个球体上,通过双线性插值,检索到相应的输入图像特征向量W(ψ(x))。后者结合方向d和位置编码γ(x),传递给NeRF MLP f(·),以预测输入帧坐标中的点密度σ和RGB颜色c:
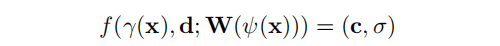
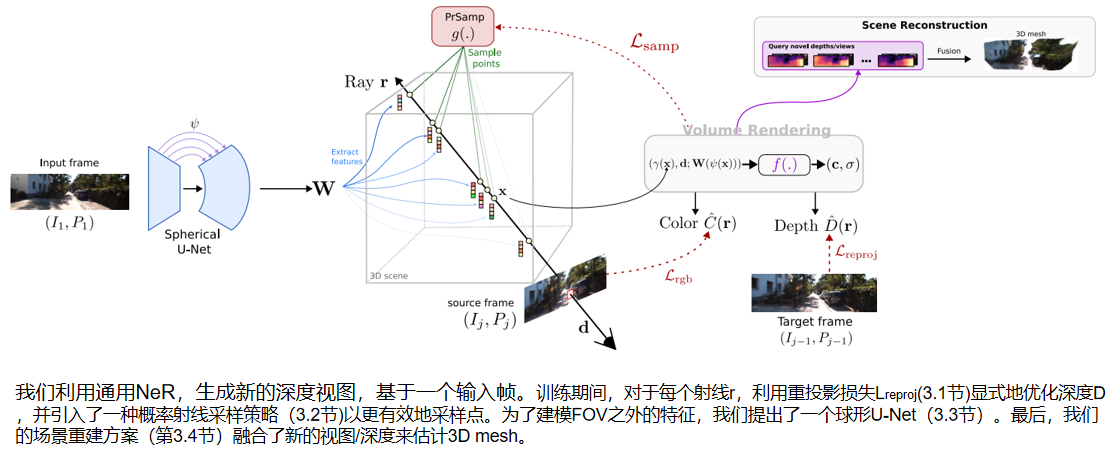
原始的NeRF 应用正交法来近似相机射线r的颜色C:
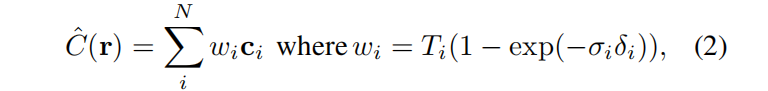
Ti是累积透过率, δi是相邻采样点的距离。
3.1.1 深度估计
与大多数nerf不同,我们试图从辐射体积中明确地揭示深度(其中 di 是点i到采样位置的距离):
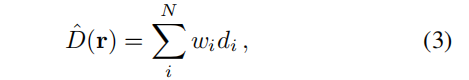
为了在没有 GT 的情况下优化深度,我们从自监督的深度方法[19,20]中得到启发,并在 warped 的源图像 Ij 与其前一帧 Ij−1 之间应用光度重投影损失,做为目标。我们选择连续的帧,以确保最大的重叠。使用稀疏深度估计ˆDj,photometric reprojection损失:
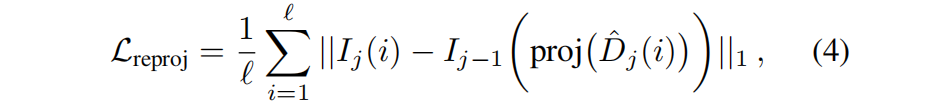
,使用ad-hoc 相机的内参和位姿,proj(·)在Ij−1 中投影二维坐标i。重要的是,虽然 ^Dj是稀疏的——因为只对某些射线进行了估计——但这些射线的随机性提供了统计上密集的监督。为了考虑移动对象,我们应用了[Digging into self-supervised monocular depth prediction]中的像素自动掩蔽策略。
3.2 概率射线采样 (PrSamp)
先前的研究[24,44,47]表明,对于体渲染,靠近表面采样点可以提高性能,并通过更少的f(·)推断提高性能并降低计算成本。由于我们在没有深度监督的情况下训练,这是一个循环问题(因为表面位置是未知)。
我们的概率射线采样策略(PrSamp)的目标是将沿每条射线的连续密度近似为一维高斯分布的混合物,以指导点采样。它隐式地学习将高混合值与表面位置相关联,从而导致用明显更少的点进行更好的采样。例如,优化一个100米的体素只需要每条射线64个点。
参考图3中的符号和(步骤),对于每条光线r,我们首先均匀地采样近边界和远边界之间的k个点。
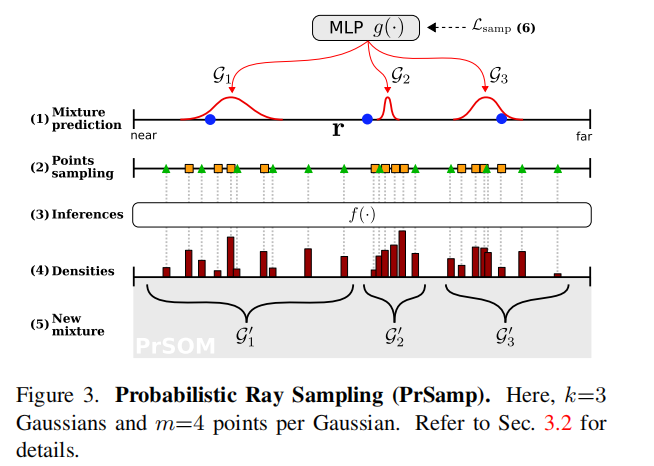
(1)以点及其对应的特征作为输入,一个专用的MLP g(·) 预测k个一维高斯的混合{G1,…,Gk}。
(2)然后我们在每高斯中采样m个点,再多采样32个均匀点;相当于N=k×m+32N点。.均匀点的添加对于探索场景体积和防止g(·)落入局部最小值是必不可少的。
(3)然后将所有的点传递给公式(1)中的 f(·) 用于颜色Cˆ(r)和深度ˆD(r)的体渲染。
(4)直观地说,密度{σ1,…σN } 由 f(·) 推断,是三维表面位置的线索,我们用它来更新我们的高斯混合,为了解决潜在的点-高斯分配问题
(5)我们依赖于来自[2]的概率自组织映射(PrSOM)。简而言之,PrSOM在严格保持混合拓扑的情况下,根据前者被一组点观察到的可能性,将点分配给高斯分布。对于每个高斯gi 及其分配的点Xi,更新后的g’i 是所有点j∈Xi 的平均值,由NeRF中定义的条件概率p(j/gi)和j的占用概率加权。
最后,(6)根据当前和新高斯分布之间的KL散度的平均值,对高斯预测器g(·)进行更新:
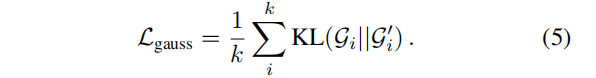
为了进一步在可见表面上加强一个高斯分布,我们还最小化了深度和最近高斯分布之间的距离
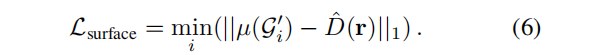
3.3 球形Unet(SU-net)
根据定义, f(·) 的有效域被限制为特征volumn的 W(·),对于标准U-Net来说,是相机的视场FOV,从而防止在FOV之外估计颜色和深度,导致不能提取特征。这不适合用于场景重建。相反,我们为SU-Net配备了一个在球形域中卷积的解码器。因为球面投影比平面对应的失真更小,可以扩大FOV(通常约120◦),使源图像FOV之外的颜色和深度产生填充。
在bottleneck,编码器的特性被与 ψ() 映射到一个任意的球体,然后传递给球形解码器(球形解码器中采用轻量级扩展卷积,以低成本增加感受野)。与标准的U-Net一样,我们使用多尺度跳跃连接,仅通过使用 ψ() 映射特征来增强梯度流。
在实践中,我们将一个二维像素[x,y]T 映射到其归一化的经纬度球面坐标[θ,φ]。考虑到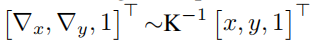 一条射线通过所述像素和相机中心。投影:
一条射线通过所述像素和相机中心。投影:
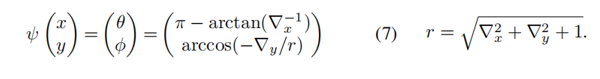
当输入解码器时,[θ,φ]被均匀离散,特征存储在一个覆盖任意大FOV的张量中。
3.4.场景重建方案
如图4所示,给定一个输入帧,我们沿着一个假想的直线路径合成新的深度(每ρ米均匀采样),直到一个给定的距离。在每个位置,我们也改变水平视角Φ={−φ,0,φ}。
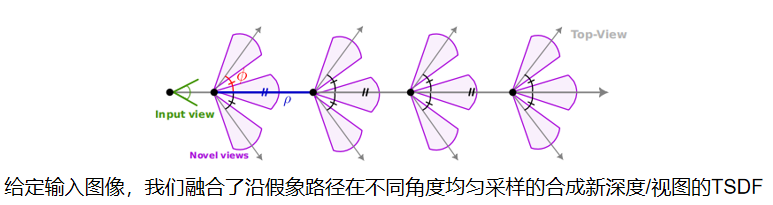
然后使用[3dmatch]将合成深度转换为TSDF,体素v的整体场景TSDF使用所有的最小值: 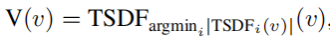
,其中 i 跨越了所有合成深度。传统上,体素TSDF是所有tsdf[10,48]的加权平均值,但我们的经验表明(附录C.2),使用最小值可以得到更好的结果。我们推测这与深度误差随距离的线性增加有关。
四、实验
我们评估了SceneRF的两个主要任务:新的深度合成和场景重建,以及一个辅助任务:新的视图合成。 在数据集 SemanticKITTI 和 BundleFusion 测试以上三个任务。SemanticKITTI 有很大的驾驶场景(≈100米深),图像序列是从一个前置摄像机捕获的,它提供了很少的视角变化。相反,捆绑融合有较浅的室内场景(≈10m)和序列有较大的横向运动。
在PrSamp中,使用k = 4个高斯,每个高斯采样点m=8,但改变新的深度/视图采样进行重建。Φ={−10,0,+10}的角度,采样每个ρ=0.5米(SemanticKITTI);并使用ρ=0.2米采样多达2.0米,使用Φ={−20,0,+20}对于BundleFusion数据 。
一些结果:
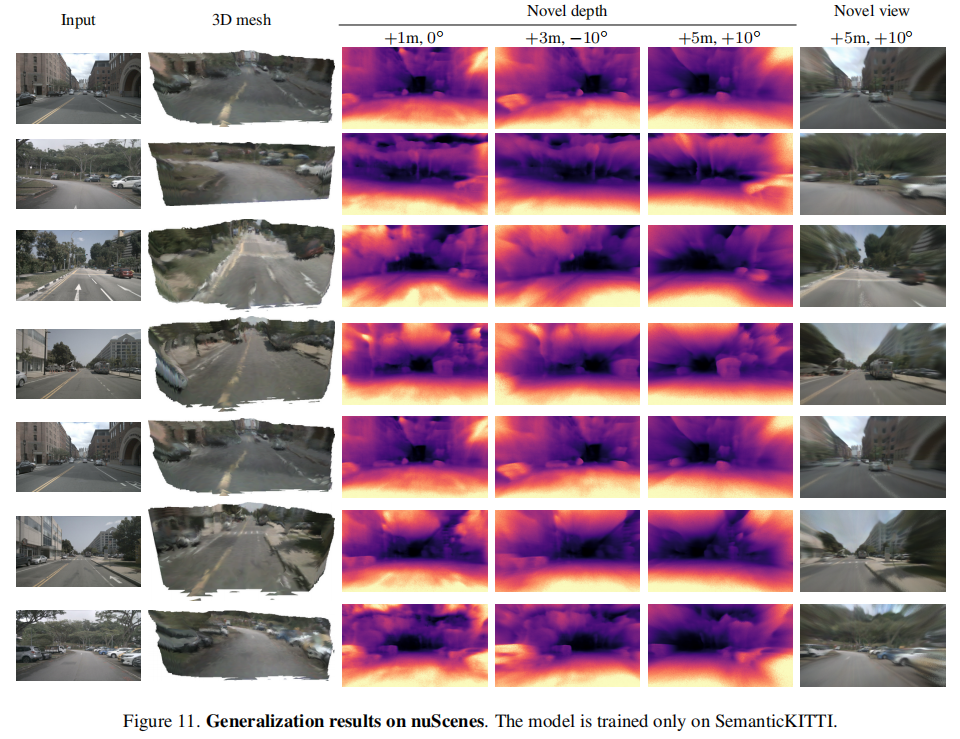
对比结果:

总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
















 8586
8586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









