









测试sc.pp.normalize_per_cell
import numpy as np
import scanpy as sc
x=np.array([[1,2,3],[2,3,4],[1,1,3],[0,2,10]])
adata=sc.AnnData(x)
adata.raw=adata.copy()
#print(adata.X)
# adata.raw=adata.copy()
# sc.pp.scale(adata)
# print(adata.X)
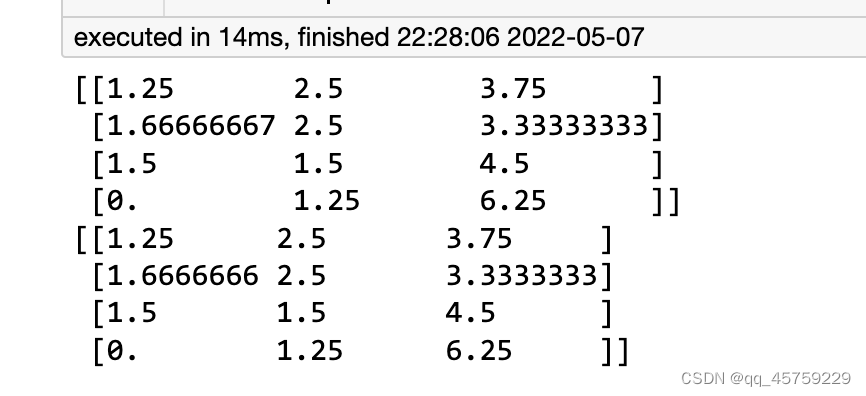
ff=np.median(np.sum(x,axis=1))/np.sum(x,axis=1)
print(np.dot(np.diag(ff),x))
sc.pp.normalize_per_cell(adata)
print(adata.X)
# sc.pp.normalize_total(adata.raw.X)
# print()
结果如下
 注意这个
注意这个
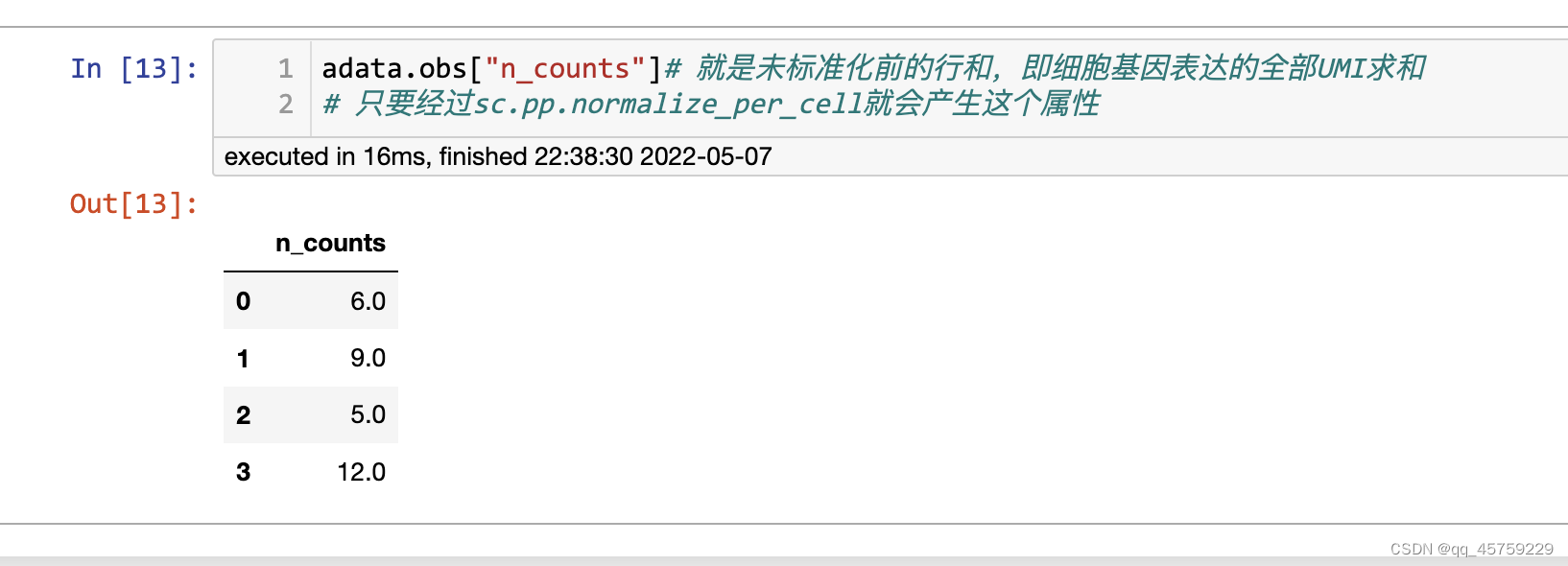
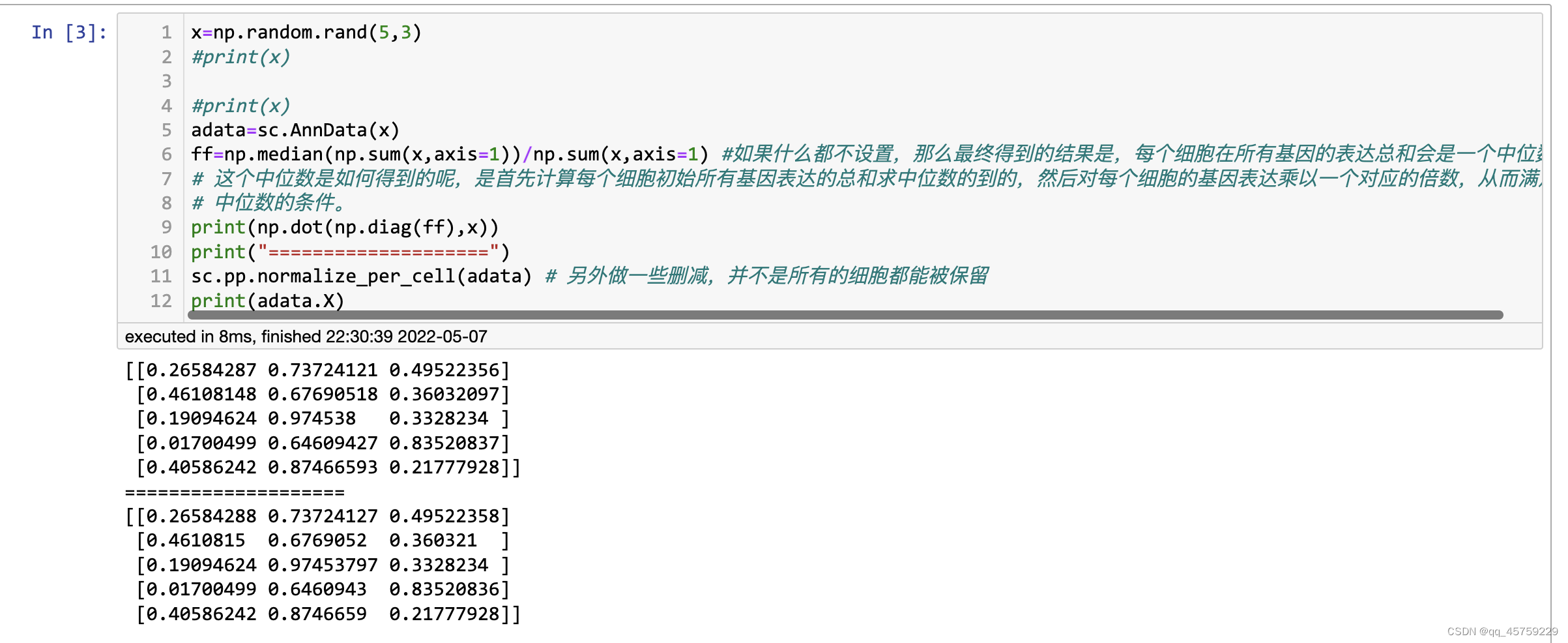
测试sc.pp.normalize_total
import numpy as np
import scanpy as sc
x=np.array([[1,2,3],[2,3,4],[1,1,3],[0,2,10]])
adata=sc.AnnData(x)
sc.pp.normalize_total(adata)
print(adata.X)
结果如下
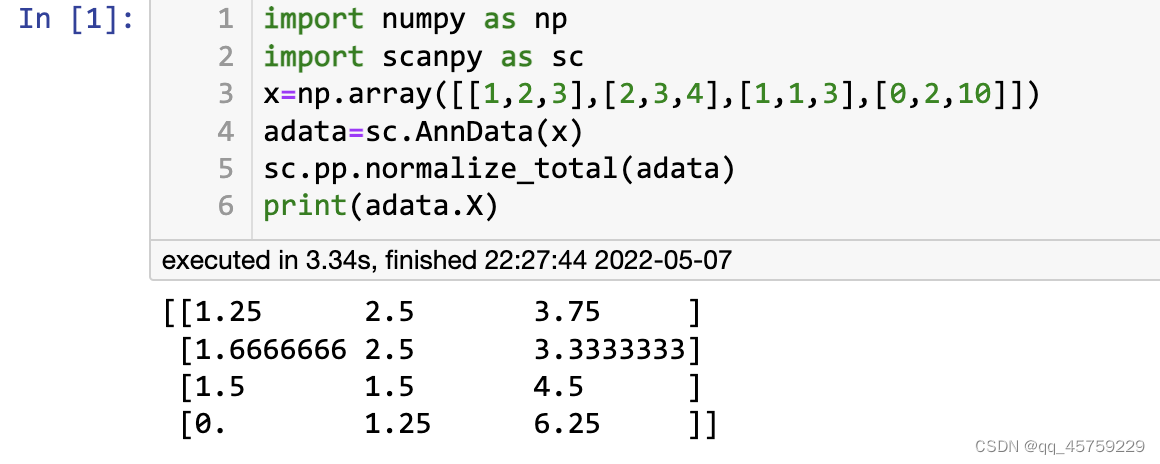
验证sc.pp.normalize_per_cell
x=np.random.rand(5,3)
#print(x)
#print(x)
adata=sc.AnnData(x)
ff=np.median(np.sum(x,axis=1))/np.sum(x,axis=1) #如果什么都不设置,那么最终得到的结果是,每个细胞在所有基因的表达总和会是一个中位数值
# 这个中位数是如何得到的呢,是首先计算每个细胞初始所有基因表达的总和求中位数的到的,然后对每个细胞的基因表达乘以一个对应的倍数,从而满足
# 中位数的条件。
print(np.dot(np.diag(ff),x))
print("====================")
sc.pp.normalize_per_cell(adata) # 另外做一些删减,并不是所有的细胞都能被保留
print(adata.X)
记录python的操作
按列操作实现1
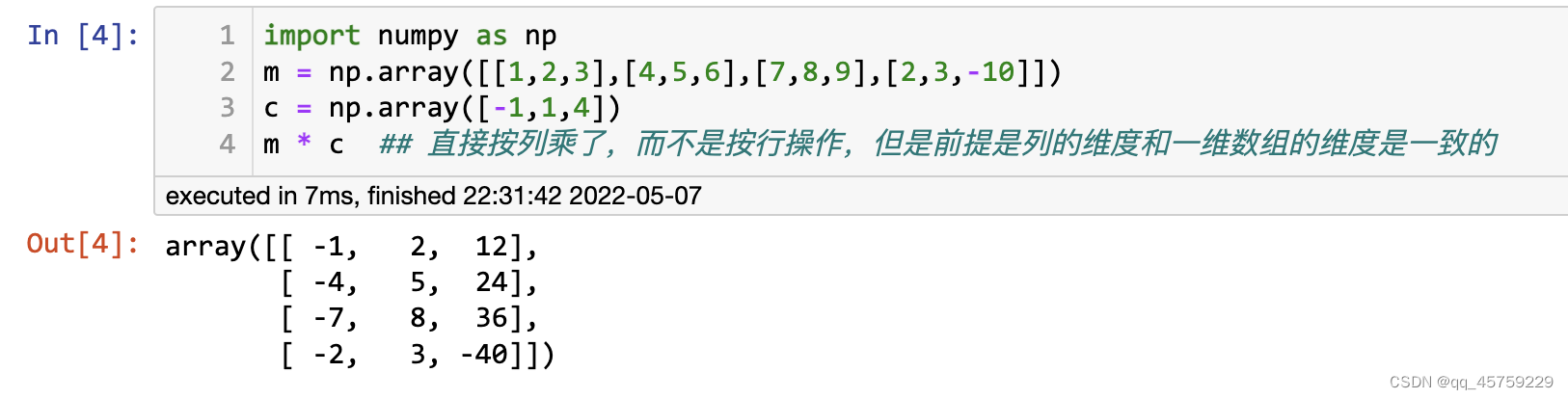
import numpy as np
m = np.array([[1,2,3],[4,5,6],[7,8,9],[2,3,-10]])
c = np.array([-1,1,4])
m * c ## 直接按列乘了,而不是按行操作,但是前提是列的维度和一维数组的维度是一致的
按列操作实现2
np.dot(m,np.diag(c))

按行操作实现1
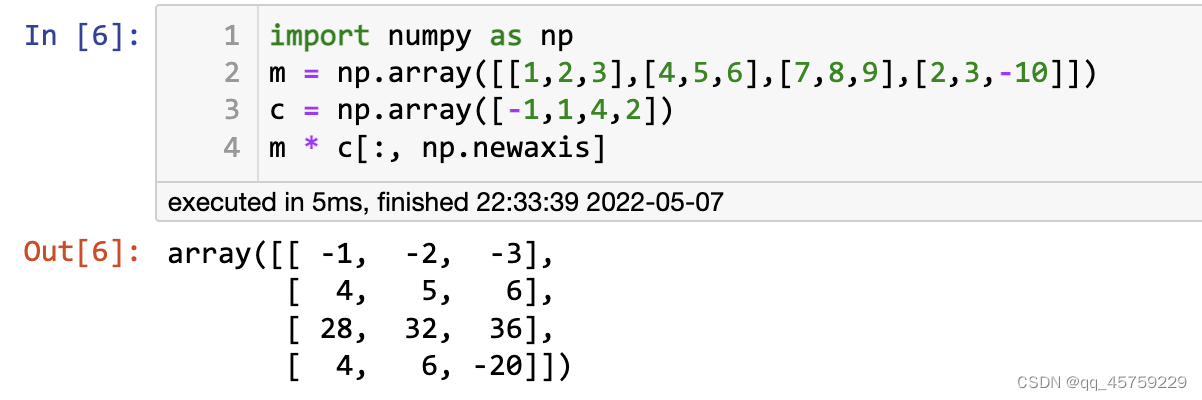
import numpy as np
m = np.array([[1,2,3],[4,5,6],[7,8,9],[2,3,-10]])
c = np.array([-1,1,4,2])
m * c[:, np.newaxis]
#np.dot(c.reshape(1,len(c)),m),这个做的是矩阵乘法
结果如下
按行操作实现2
(m.T * c).T

按行操作实现3
m * c[:, None]

按行操作实现4
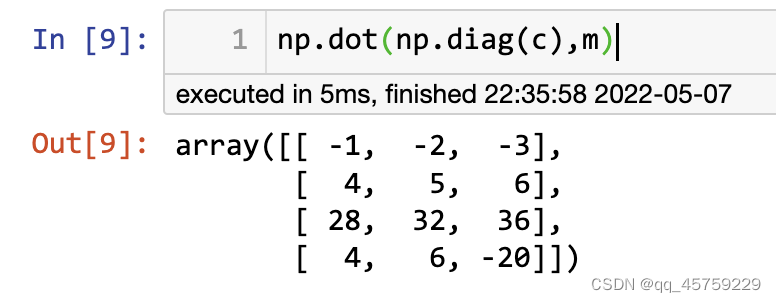
np.dot(np.diag(c),m)
结果如下
今天再次遇到了这个问题,再复习一下
首先人家的代码
def take_norm(data, cellwise_norm=True, log1p=True):
data_norm = data.copy()
data_norm = data_norm.astype('float32')
if cellwise_norm:
libs = data.sum(axis=1)
norm_factor = np.diag(np.median(libs) / libs)
data_norm = np.dot(norm_factor, data_norm)
if log1p:
data_norm = np.log2(data_norm + 1.)
return data_norm
这个相当于以下的操作
sc.pp.normalize_total(adata)
sc.pp.log1p(adata)
注意sc.pp.normalize_total(adata)不要设置targe_sum参数
但是你会发现这个结果还是不一致哈哈哈,因为
sc.pp.log1p是以自然对数(就是e为底的),而take_norm函数中是np.log2()是以2为底的,两者差了一个倍数,需要注意
import scanpy as sc
import numpy as np
import pandas as pd
def take_norm(data, cellwise_norm=True, log1p=True):
data_norm = data.copy()
data_norm = data_norm.astype('float32')
if cellwise_norm:
libs = data.sum(axis=1)
norm_factor = np.diag(np.median(libs) / libs)
data_norm = np.dot(norm_factor, data_norm)
if log1p:
data_norm = np.log2(data_norm + 1.)
return data_norm
data=np.array([
[3, 3, 3, 6, 6],
[1, 1, 1, 2, 2],
[1, 22, 1, 2, 2],
])
adata = sc.AnnData(data)
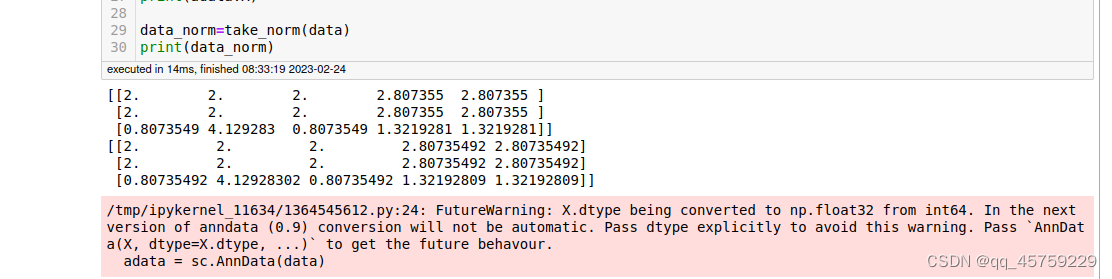
sc.pp.normalize_total(adata)
sc.pp.log1p(adata,base=2)
print(adata.X)
data_norm=take_norm(data)
print(data_norm)
结果如下

















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









