







 本文概述了NLP领域的DeepLearningRecommendationModel (DLRM)、内容与上下文推荐系统综述,以及TF-IDF在生成式下游任务中的应用。重点比较了DLRM的结构和性能,介绍了内容与上下文推荐的进展,以及开源社区中推荐方法的创新,如混合推荐模型的提升。
本文概述了NLP领域的DeepLearningRecommendationModel (DLRM)、内容与上下文推荐系统综述,以及TF-IDF在生成式下游任务中的应用。重点比较了DLRM的结构和性能,介绍了内容与上下文推荐的进展,以及开源社区中推荐方法的创新,如混合推荐模型的提升。
-
NLP文章阅读小结(更新中,未完待续...)
| 文章标题 | 模型创新点 | 是否有源码 |
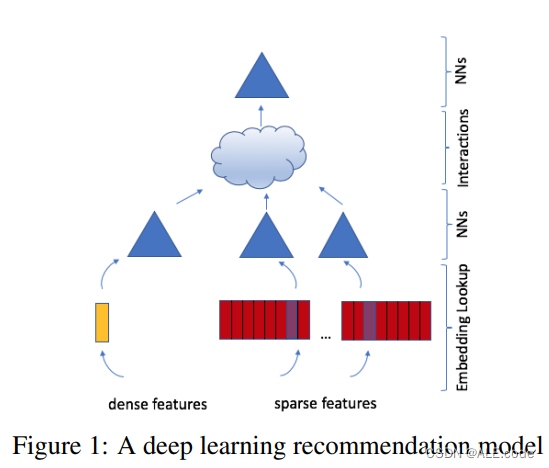
| 1. Deep Learning Recommendation Model for Personalization and Recommendation Systems | deep learning recommendation model (DLRM) -PyTorch and Caffe2 frameworks模型 结合了以下两个观点 1.推荐系统的观点(推荐的东西基于过去的行为,比如先前的评分) 2.预测分析(统计模型来分类 or 根据给定的数据预测事件的概率) 模型的结构: 1.sparse features——来表示categorial data 2.一个多层感知器(MLP)处理密集特征(dense features)
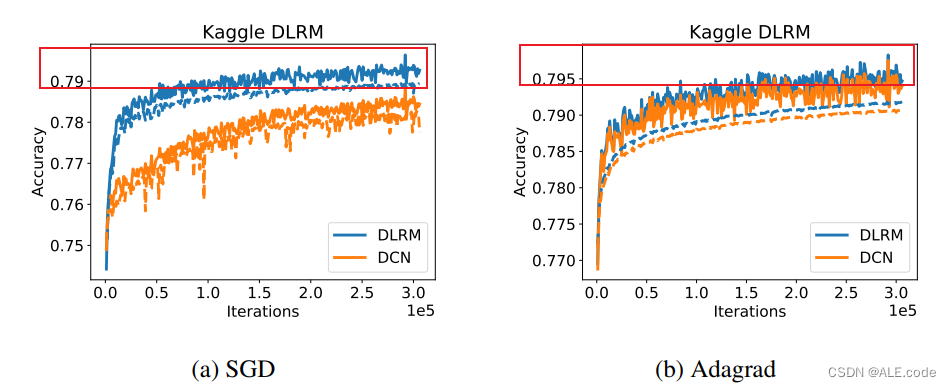
a key difference compare with others: 网络如何处理嵌入式特征向量以及其交叉项,DLRM是使用模仿因式分解的结构化方式交互嵌入 模型的指标是accuracy达到大约79.5%
| yes |
| 2. A Review of Content-Based and Context-Based Recommendation Systems | 本文是一篇综述 由于目前上下文文本信息有:丰富的信息、数据冗余和上下文冗余等问题,本文先分别介绍了content-based recommender system and context-aware recommender system ,还有着重介绍了ontology-based recommendation system,因为ontology domain knowledge可以有效的提高准确度和质量。 同时提出了后期建立model的展望,即有三层content-aware 架构的recommendation system,model包含:① pre-filtering上下文前过滤,②post-filtering 上下文后过滤 ③contextual modelling 上下文建模 | no |
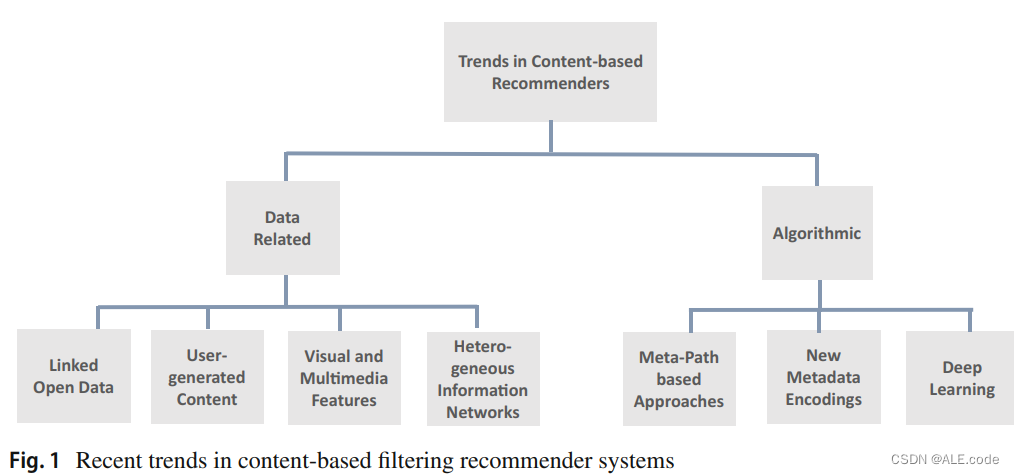
| 3. Trends in content-based recommendation | 本文是一篇综述 从历史上看,构建推荐系统主要有两种方法: 1. 协同过滤 Collaborative Filtering (CF):只依赖于偏好模式的识别 2. 基于内容的过滤 Content-Based Filtering:只考虑了个人用户过去的偏好,并尝试学习基于偏好的模型基于特征的可推荐项目内容的表示 由于两种方法,都只考虑的是单个用户过去的偏好,所以存在局限性,所以目前都是两种方法的hybrid。(Content的是主流,但纯Content已经很少了,都和CF有结合)
| no |
| 4. 开源社区中Issue解决过程的参与者推荐方法 | 现存问题: ①目前问答系统中回答者推荐主要采用的是问题相似度来推荐回答者,但开源社区中开发者是否参与某一问题讨论还受到其他因素的影响 ②Pull-Request评价者推荐不适用于Issue解决过程 提出了一个混合模型:1.根据开发者参与过的问题特征(多个问题特征向量组)构建开发者画像 2.根据开发者画像,利用熵值法进行特征偏好权重计算 3.最后结合信息检索和评论网络进行混合推荐 基于开发者画像的混合推荐模型jasmine的性能(采用召回率作为评价指标Recall)从42.63%提升为79.49% | no |
-
TF-IDF模型学习(更新中,未完待续...)
-
杂记(更新中,未完待续...)

生成式下游任务:拆开来理解
- 生成式:要产生新的语言内容(比如说问答,翻译,摘要)
- 下游任务:模型下一步输出的任务【即:模型的输入输出可以看作数据流,一个跟着一个;下游任务就是这个模型的输出要传给的模型】

















 8253
8253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









